and the distribution of digital products.
Apparate: Early-Exit Models for ML Latency and Throughput Optimization - Early-Exit Models
:::info Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
:::
Table of Links2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
2.2 Early-Exit ModelsEarly (or multi) exit models [53,57] present an alternate way to address this tension by rethinking the granularity of inference. As shown in Figure 4, the key premise is that certain ‘easy’ inputs may not require the full predictive power of a model to generate an accurate result. Instead, results for such inputs may be predictable from the values at intermediate layers. In such cases, the foregone model execution can yield proportional reductions in both per-request latencies and compute footprints. Thus, the goal with early exits (EEs) is to determine, on a per-input basis, the earliest model layer at which an accurate response can be generated.
\ To use EEs, intermediate layers in a model are augmented with ramps of computation. These ramps ingest the values output by the layers they are attached to and parse them to predict the final model’s result, e.g., a classification label. Ramps can perform arbitrary degrees of computation to arrive at a potential result. Exiting decisions at each ramp are made by comparing the entropy in the predicted result (or averaged over the past k ramps) to a preset threshold. Thresholds are set to balance latency and compute wins with potential dips in accuracy; a higher threshold implies lower required confidence for exiting, and thus more exiting.
\ Potential benefits. To understand the effect that EEs can have on the latency-throughput tension, we considered offthe-shelf EE variants for the models used in Figure 3: BranchyNet [53] (for CV) and DeeBERT [57] (for NLP). For each model-input pair, we identified the optimal exit point defined as the earliest exit ramp that predicted the correct response for the input, i.e., the ramp which assigned the maximum probability to the correct label. We then modified the
\
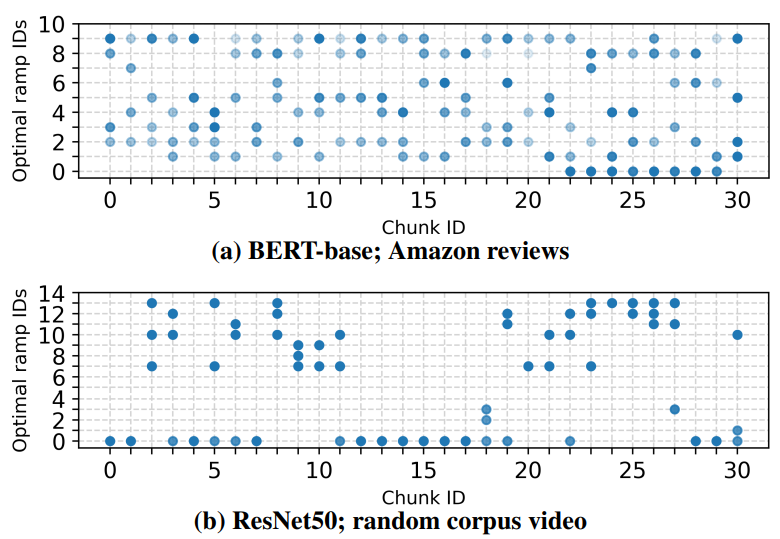
\ highest-throughput results in Figure 3 to account for exiting by subtracting the time saved for each exiting input, i.e., the difference in time for passing an input to the end of its optimal ramp versus passing it to the end of the model (without any ramps present). Note that these results are conservative upper bounds in that they do not reduce queuing delays or alter job scheduling. As shown in Figure 5, without changing queueing decisions, EEs can bring 35-54.7% and 17.9-26% improvements in median and 95th percentile latencies relative to running existing serving systems alone.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\