and the distribution of digital products.
Apparate: Early-Exit Models for ML Latency and Throughput Optimization - Challenges
:::info Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
:::
Table of Links2 Background and Motivation and 2.1 Model Serving Platforms
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
2.3 ChallengesDespite numerous EE proposal from the ML community [28, 36, 46, 53, 57, 58, 64], and their potential benefits for serving platforms, multiple issues complicate their use in practice, leading to low adoption rates. We describe them in turn.
\ C1: Latency and resource overheads. Although exiting can enable certain inputs to eschew downstream model computations, exit ramps impose two new overheads on model serving. First, to be used, ramps must also be loaded into GPU memory which is an increasingly precious resource as models grow in size [31, 48, 60] and inference shifts to resourceconstrained settings [23,40]. For instance, DeeBERT inflates overall memory requirements by 6.56% compared to BERTbase. Second, certain inputs may be too “hard” to accurately exit at an intermediate ramp. In these cases, overall serving latency mildly grows as unsuccessful exiting decisions are made, e.g., inputs that cannot exit at any ramp slow by 22.0% and 19.5% with BranchyNet and DeeBERT.
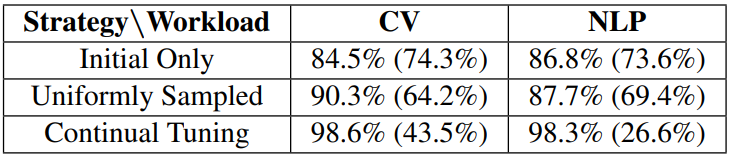
\ C2: Frequent and costly adaptation. As shown in Figure 6, the evolving nature of workloads for interactive applications [35, 51] brings frequent changes in the best EE configuration at any time, i.e., the set of active ramps (and their thresholds) that maximize latency savings without sacrificing response accuracy or exceeding available memory. Unfortunately, the large body of EE literature is unaccompanied by any policy for tuning ramps and thresholds during serving. Instead, proposed EE models are equipped with the max number of ramps, and mandate users to perform one-time tuning of thresholds. Such tuning is non-trivial and fails to cope with workload dynamism. For example, Table 1 shows how one-time tuning on initial or sampled data brings 8.3- 14.5% drops in accuracy relative to continual tuning. Worse, the space of configurations is untenably large, with many ramp options (i.e., at any layer, with any computation) and a continuous space of possible threshold values for each.
\
\ C3: Lack of accuracy feedback. EE ramp decisions are ultimately confidence-driven and may result in accuracy degradations (as shown above). In production scenarios, serving optimizations that deliver accuracy reductions of more than 1-2% are generally considered unacceptable [14]. Yet, despite this strict constraint, once deployed, EE models do not provide any indication of accuracy drops; indeed, when an exit is taken, the corresponding input does not pass through the remaining model layers, and the original (nonEE) model’s prediction is never revealed. Thus, with early exiting, we lack mechanisms to determine when accuracy degradations are arising and EE tuning is required.
\ C4: Incompatibility with batching. Lastly, although EE decisions do not directly conflict with queuing decisions in serving platforms, combining exiting and batching presents practical challenges. In particular, as inputs exit at ramps, batch sizes for already scheduled inference tasks naturally shrink, leading to resource underutilization for the rest of the model’s execution. Batch reforming [4] could help, but adds undue latency from added CPU-GPU data transfers; recent proposals [29,38] aim to address these communication overheads but fail to generalize across hardware configurations.[1]
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
[1] Solving this challenge directly is outside the scope of this paper. We note that this would bring latency and compute wins from EEs, but would forego accuracy feedback (and thus, adaptation).