and the distribution of digital products.
Apparate: Early-Exit Models for ML Latency and Throughput Optimization - Background and Platforms
:::info Authors:
(1) Yinwei Dai, Princeton University (Equal contributions);
(2) Rui Pan, Princeton University (Equal contributions);
(3) Anand Iyer, Georgia Institute of Technology;
(4) Ravi Netravali, Georgia Institute of Technology.
:::
Table of Links2 Background and Motivation and 2.1 Model Serving Platforms
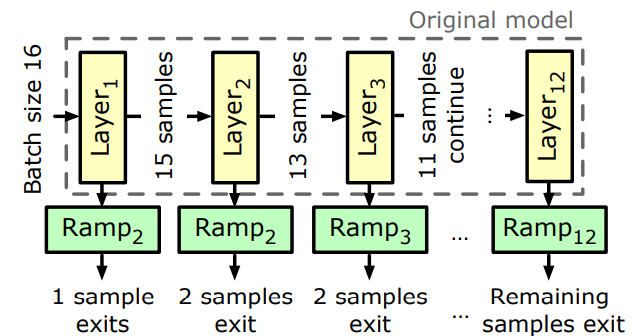
3.1 Preparing Models with Early Exits
3.2 Accuracy-Aware Threshold Tuning
3.3 Latency-Focused Ramp Adjustments
5 Evaluation and 5.1 Methodology
5.3 Comparison with Existing EE Strategies
7 Conclusion, References, Appendix
2 BACKGROUND AND MOTIVATIONWe start by overviewing existing ML serving platforms (§2.1), highlighting the challenges they face in balancing metrics that are important for system performance (i.e., throughput, resource utilization) and application interactivity, i.e., per-request latencies. We then describe the promising role that early exits can play in alleviating those tensions (§2.2), and the challenges in realizing those benefits in practice (§2.3). Results here follow the methodology from §5.1, and presented trends hold for all workloads used in the paper.
\
ML models are routinely used to service requests in interactive applications such as real-time video analytics [13, 49], recommendation engines [50], or speech assistants [12]. To manage such workloads, especially at large scale, applications employ serving platforms such as ONNX runtime [5], TensorFlow-Serving [39], PyTorch Serve [9], Triton Inference Server [4], among others [17,22,44,49,60]. These platforms ingest pre-trained model(s) from applications, often in graph exchange formats like ONNX [6] and NNEF [2], and are also granted access to a pool of compute resources (potentially with ML accelerators such as GPUs) for inference.
\ Given the latency-sensitive nature of interactive applications, requests are most often accompanied with service level objectives (SLOs) that indicate (un)acceptable response times for the service at hand. In particular, responses delivered after an SLO expires are typically discarded or yield severely degraded utility. Common SLOs are in the 10-100s of milliseconds, e.g., for live video analytics [40, 49].
\ During operation, serving platforms queue up incoming requests that can arrive at fixed or variable rates, and continually schedule jobs across the available compute resources. An inference task may be scheduled to run on a single node in a cluster, or may be distributed across multiple nodes [60]. State-of-the-art serving frameworks include optimizations such as response caching [17], intelligent job placement to aggressively pack GPU memory resources [49], or strategies to mitigate CPU-GPU communication overheads [60].
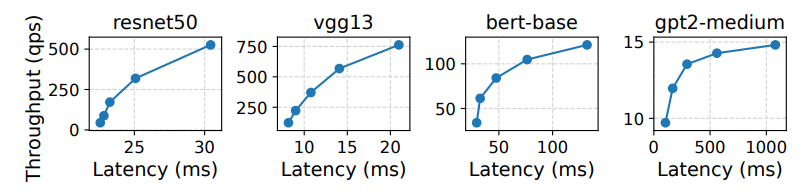
\ Latency-Throughput tension. Real-world inference deployments must handle large volumes of requests [25, 37]. To support the need for high throughput, serving platforms resort to batching, whereby inputs are grouped into a single high-dimensional tensor that moves through the model in lockstep, kernel by kernel, with final per-request responses being delivered at the same time. Larger batch sizes amortize the cost of loading a kernel into GPU memory across more inputs, and enable more effective use of the parallelism that ML-focused hardware affords [17, 62].
\ Unfortunately, delivering the throughput necessary to support high request rates is directly at odds with per-request latencies (Figure 1). On one hand, latency for an input is minimized by scheduling inference as soon as the request arrives with batch size of 1. On the other hand, throughput is maximized by creating large batches using a queuing system which directly inflates request latencies.
\ The problem. In navigating this tension, the key decision
\
\
![Tuning platform knobs lowers latencies but harms throughput. Results vary TF-Serve’s max_batch_size from 4-16. Gray lines show min serving delay per model (batch of 1). CV uses a random video in our set; NLP uses Amazon reviews [10].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-kha3z3o.png)
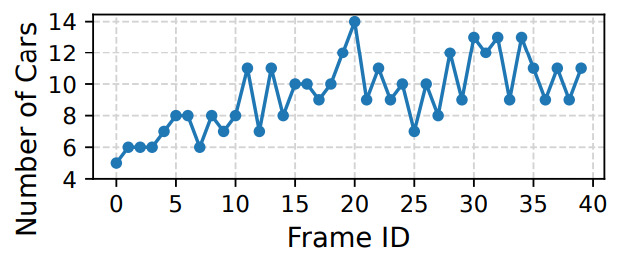
\ that serving platforms face is when to drain queued requests and schedule them for inference. Certain platforms [17, 22, 49] take an all-or-nothing viewpoint on latency, with adherence to SLOs considered complete success, and violations viewed as complete failure. Accordingly, these platforms schedule inference jobs in a work-conserving manner and select the max batch size that limits SLO violations for queued requests. However, many interactive applications present a more nuanced latency story where sub-SLO responses are not equally useful. For instance, live video analytics results can change every frame, i.e. 33 ms (Figure 2); faster responses ensure up-to-date perception of the environment. Similarly, for speech assistance, faster responses are favored to keep conversational interactivity high [26, 59].
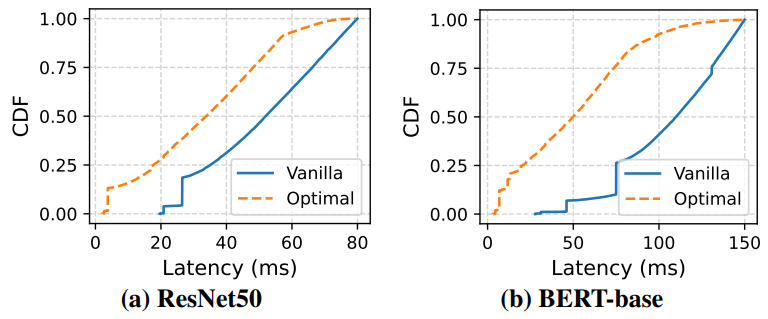
\ Other platforms [4, 9, 39] provide more flexibility by exposing tunable knobs to guide queue management. For instance, applications can configure maxbatchsize and batchtimeoutmicros parameters that set a cap on batch size or inter-job scheduling durations. However, as shown in Figure 3, such knobs do little to ease the throughput-latency tension, and instead expose harsh tradeoffs: across both CV and NLP workloads, tuning these knobs for median latency improvements of 17.3-39.1% brings 1.1-3.6× reductions in average batch sizes (and proportional hits on throughput).
\ Takeaway. Existing platform configurations and knobs fail to practically remediate the throughput-latency tension, and instead simply navigate (often) unacceptable tradeoff points between the two goals. Given ever-growing request rates and the need for high throughput, we ask if there is a middle-ground: whereby new serving adaptations enable lower per-request latencies (moving closer to the lower-bound serving times in Figure 3) without harming platform throughput.. Existing platform configurations and knobs fail to practically remediate the throughput-latency tension, and instead simply navigate (often) unacceptable tradeoff points between the two goals. Given ever-growing request rates and the need for high throughput, we ask if there is a middleground: whereby new serving adaptations enable lower perrequest latencies (moving closer to the lower-bound serving times in Figure 3) without harming platform throughput.
\
\
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
\