and the distribution of digital products.
Using MinIO to Build a Retrieval Augmented Generation Chat Application
\ It’s often been said that in the age of AI - data is your moat. To that end, building a production-grade RAG application demands a suitable data infrastructure to store, version, process, evaluate, and query chunks of data that comprise your proprietary corpus. Since MinIO takes a data-first approach to AI, our default initial infrastructure recommendation for a project of this type is to set up a Modern Data Lake (MinIO) and a vector database. While other ancillary tools may need to be plugged in along the way, these two infrastructure units are foundational. They will serve as the center of gravity for nearly all tasks subsequently encountered in getting your RAG application into production.
\ But you are in a conundrum. You’ve heard of these terms LLM and RAG before but beyond that you haven’t ventured much because of the unknown. But wouldn't it be nice if there was a “Hello World” or boilerplate app that can help you get started?
\ Don’t worry, I was in the same boat. So in this blog, we will demonstrate how to use MinIO to build a Retrieval Augmented Generation(RAG) based chat application using commodity hardware.
\
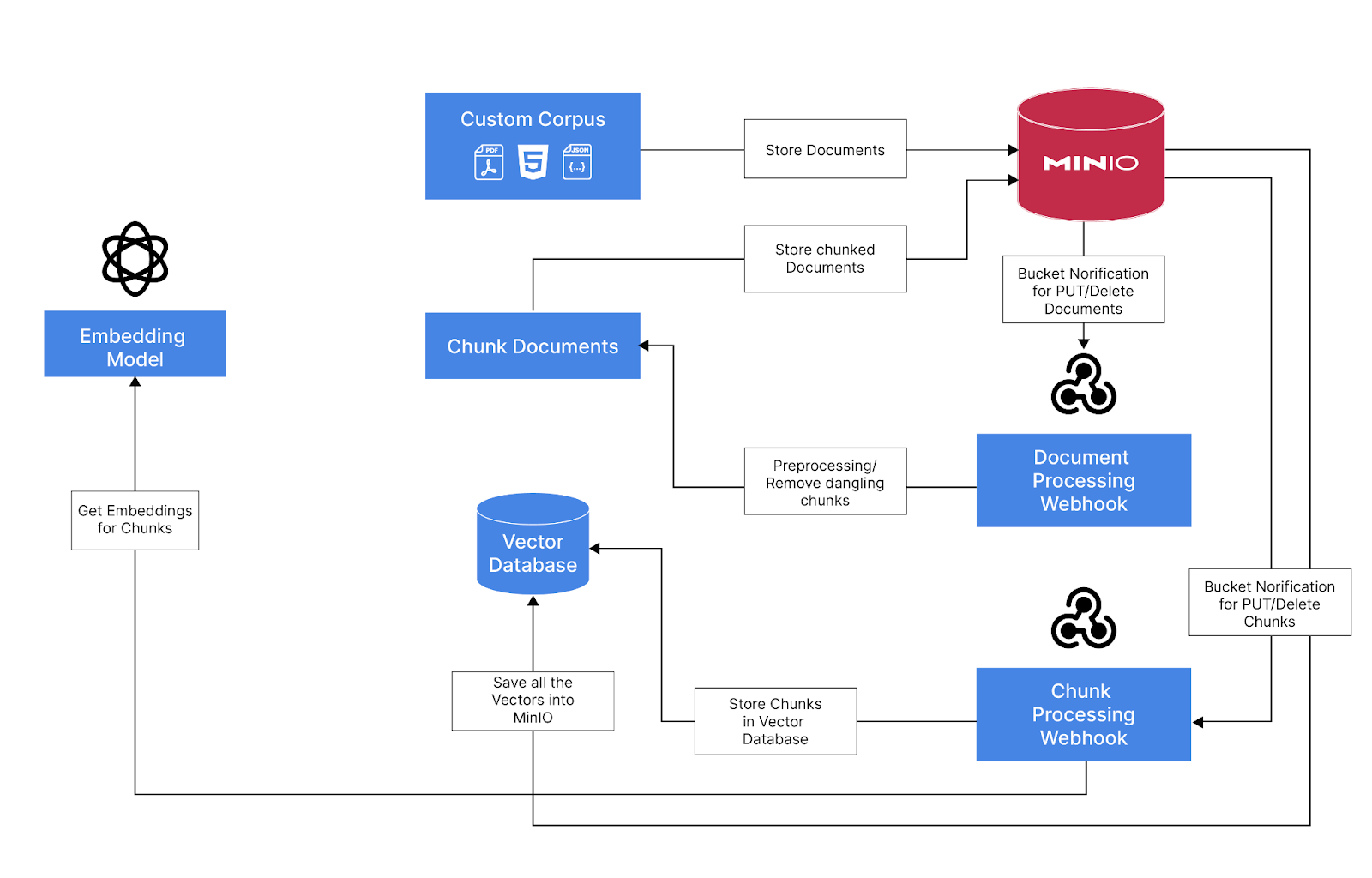
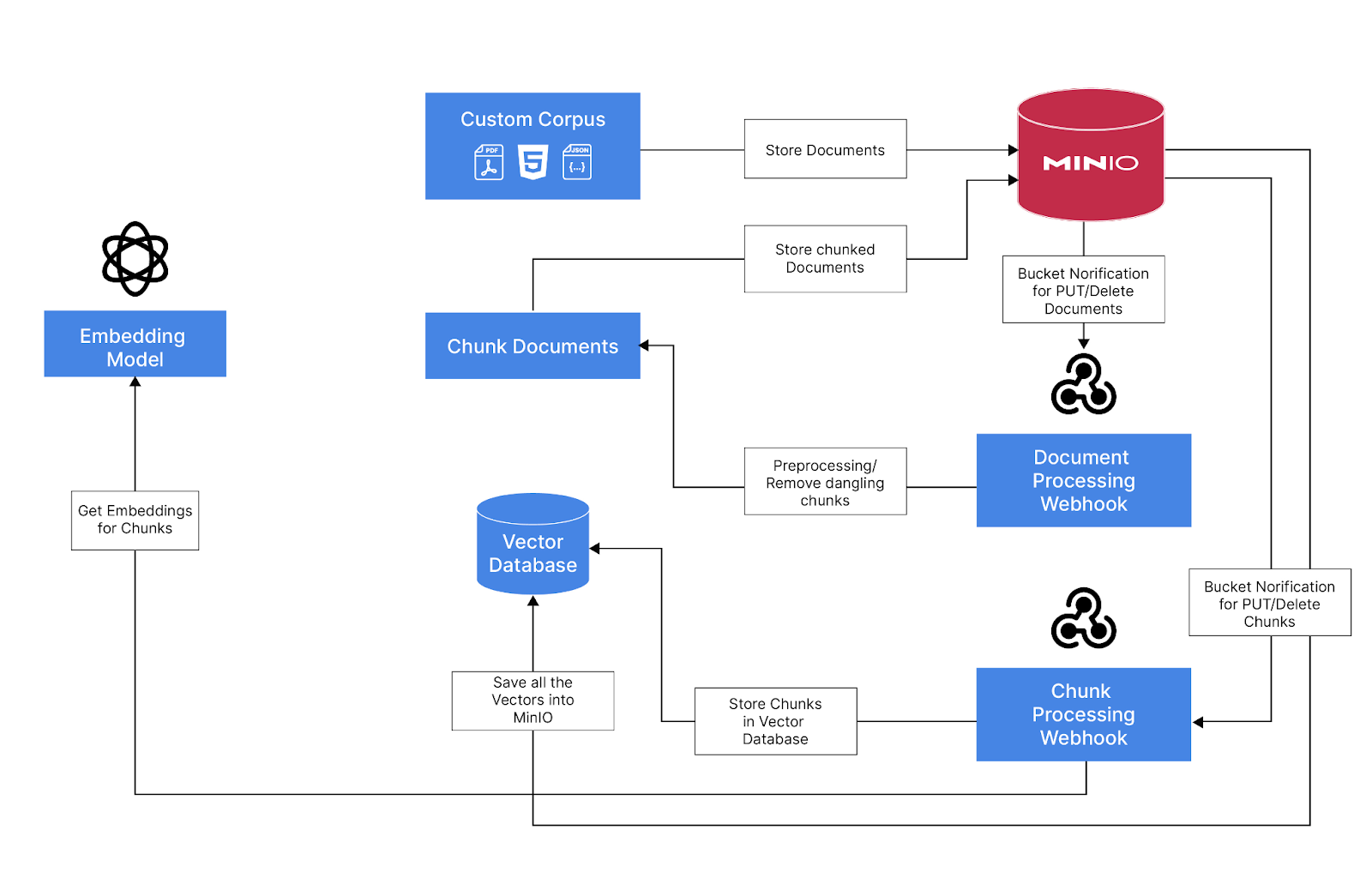
Use MinIO to store all the documents, processed chunks and the embeddings using the vector database.
\
Use MinIO's bucket notification feature to trigger events when adding or removing documents to a bucket
\
Webhook that consumes the event and process the documents using Langchain and saves the metadata and chunked documents to a metadata bucket
\
Trigger MinIO bucket notification events for newly added or removed chunked documents
\
A Webhook that consumes the events and generates embeddings and save it to the Vector Database (LanceDB) that is persisted in MinIO
\
Key Tools Used- MinIO - Object Store to persist all the Data
- LanceDB - Serverless open-source Vector Database that persists data in object store
- Ollama - To run LLM and embedding model locally (OpenAI API compatible)
- Gradio - Interface through which to interact with RAG application
- FastAPI - Server for the Webhooks that receives bucket notification from MinIO and exposes the Gradio App
- LangChain & Unstructured - To Extract useful text from our documents and Chunk them for Embedding
\
Models Used- LLM - Phi-3-128K (3.8B Parameters)
- Embeddings - Nomic Embed Text v1.5 (Matryoshka Embeddings/ 768 Dim, 8K context)
You can download the binary if you don't have it already from here
\
# Run MinIO detached !minio server ~/dev/data --console-address :9090 &\
Start Ollama Server + Download LLM & Embedding ModelDownload Ollama from here
\
# Start the Server !ollama serve\
# Download Phi-3 LLM !ollama pull phi3:3.8b-mini-128k-instruct-q8_0\
# Download Nomic Embed Text v1.5 !ollama pull nomic-embed-text:v1.5\
# List All the Models !ollama ls\
Create A Basic Gradio App Using FastAPI to Test the Model LLM_MODEL = "phi3:3.8b-mini-128k-instruct-q8_0" EMBEDDING_MODEL = "nomic-embed-text:v1.5" LLM_ENDPOINT = "http://localhost:11434/api/chat" CHAT_API_PATH = "/chat" def llm_chat(user_question, history): history = history or [] user_message = f"**You**: {user_question}" llm_resp = requests.post(LLM_ENDPOINT, json={"model": LLM_MODEL, "keep_alive": "48h", # Keep the model in-memory for 48 hours "messages": [ {"role": "user", "content": user_question } ]}, stream=True) bot_response = "**AI:** " for resp in llm_resp.iter_lines(): json_data = json.loads(resp) bot_response += json_data["message"]["content"] yield bot_response\
import json import gradio as gr import requests from fastapi import FastAPI, Request, BackgroundTasks from pydantic import BaseModel import uvicorn import nest_asyncio app = FastAPI() with gr.Blocks(gr.themes.Soft()) as demo: gr.Markdown("## RAG with MinIO") ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear") ch_interface.chatbot.show_label = False ch_interface.chatbot.height = 600 demo.queue() if __name__ == "__main__": nest_asyncio.apply() app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH) uvicorn.run(app, host="0.0.0.0", port=8808) Test Embedding Model import numpy as np EMBEDDING_ENDPOINT = "http://localhost:11434/api/embeddings" EMBEDDINGS_DIM = 768 def get_embedding(text): resp = requests.post(EMBEDDING_ENDPOINT, json={"model": EMBEDDING_MODEL, "prompt": text}) return np.array(resp.json()["embedding"][:EMBEDDINGS_DIM], dtype=np.float16)\
## Test with sample text get_embedding("What is MinIO?")\
Ingestion Pipeline Overview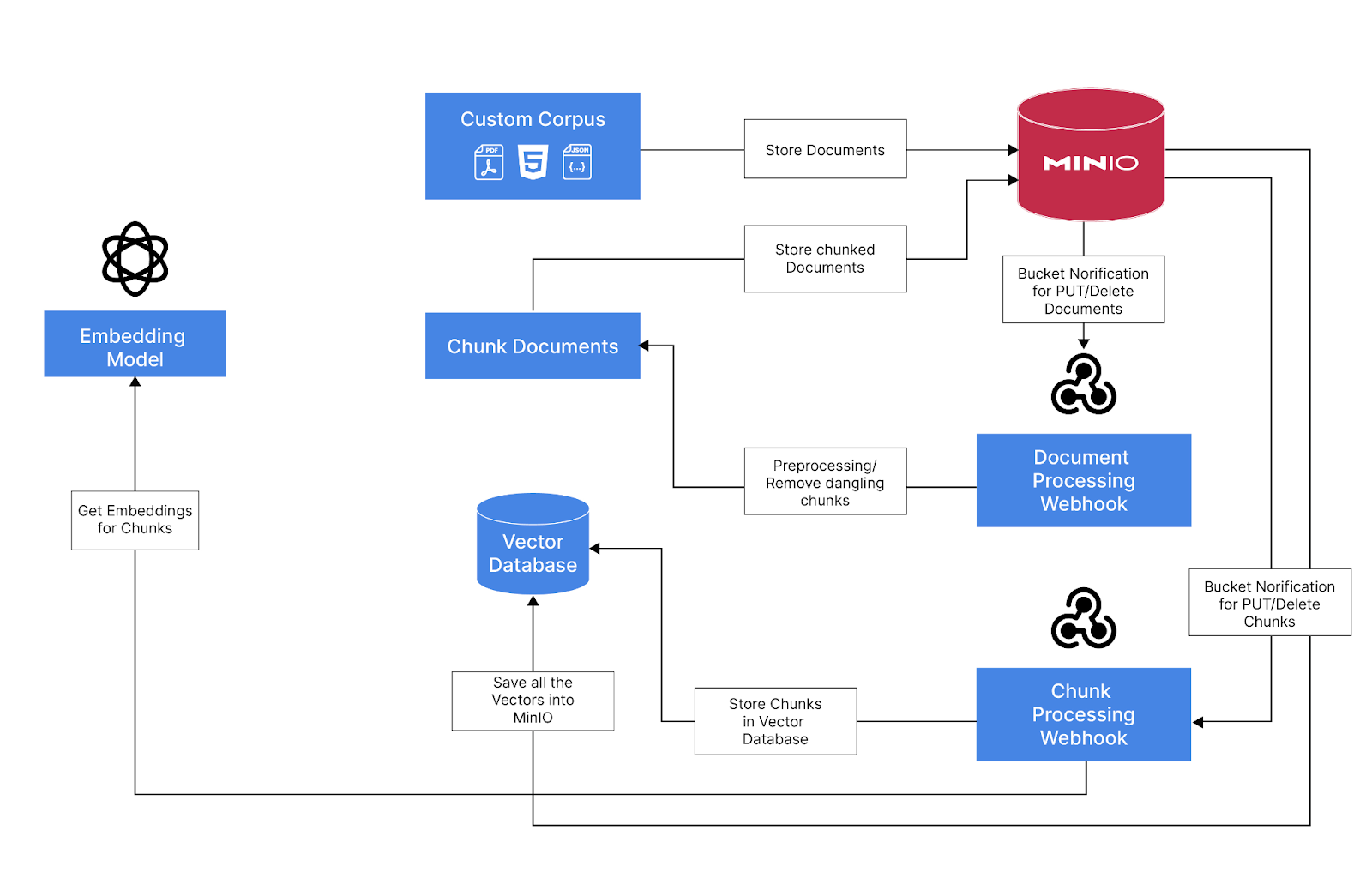
Use mc command or do it from UI
- custom-corpus - To store all the documents
- warehouse - To store all the metadata, chunks and vector embeddings
\
!mc alias set 'myminio' 'http://localhost:9000' 'minioadmin' 'minioadmin'\
!mc mb myminio/custom-corpus !mc mb myminio/warehouse Create Webhook that Consumes Bucket Notifications from custom-corpus bucket import json import gradio as gr import requests from fastapi import FastAPI, Request from pydantic import BaseModel import uvicorn import nest_asyncio app = FastAPI() @app.post("/api/v1/document/notification") async def receive_webhook(request: Request): json_data = await request.json() print(json.dumps(json_data, indent=2)) with gr.Blocks(gr.themes.Soft()) as demo: gr.Markdown("## RAG with MinIO") ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear") ch_interface.chatbot.show_label = False demo.queue() if __name__ == "__main__": nest_asyncio.apply() app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH) uvicorn.run(app, host="0.0.0.0", port=8808)\
## Test with sample text get_embedding("What is MinIO?")\
Create MinIO Event Notifications and Link it to custom-corpus Bucket Create Webhook EventIn Console go to Events-> Add Event Destination -> Webhook
\ Fill the fields with Following values and hit save
\ Identifier - doc-webhook
\ Endpoint - http://localhost:8808/api/v1/document/notification
\ Click Restart MinIO at the top when pormpted to
\ (Note: You can also use mc for this)
Link the Webhook Event to custom-corpus bucket EventsIn console go to Buckets (Administrator) -> custom-corpus -> Events
\ Fill the fields with Following values and hit save
\ ARN - Select the doc-webhook from dropdown
\ Select Events - Check PUT and DELETE
\ (Note: You can also use mc for this)
\ We have our first webhook setup
Now test by adding and removing an object Extract data from the Documents and ChunkWe will use Langchain and Unstructured to read an object from MinIO and Split Documents in to multiples chunks
\
from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.document_loaders import S3FileLoader MINIO_ENDPOINT = "http://localhost:9000" MINIO_ACCESS_KEY = "minioadmin" MINIO_SECRET_KEY = "minioadmin" # Split Text from a given document using chunk_size number of characters text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=64, length_function=len) def split_doc_by_chunks(bucket_name, object_key): loader = S3FileLoader(bucket_name, object_key, endpoint_url=MINIO_ENDPOINT, aws_access_key_id=MINIO_ACCESS_KEY, aws_secret_access_key=MINIO_SECRET_KEY) docs = loader.load() doc_splits = text_splitter.split_documents(docs) return doc_splits\
# test the chunking split_doc_by_chunks("custom-corpus", "The-Enterprise-Object-Store-Feature-Set.pdf") Add the Chunking logic to WebhookAdd the chunk logic to webhook and save the metadata and chunks to warehouse bucket
\
import urllib.parse import s3fs METADATA_PREFIX = "metadata" # Using s3fs to save and delete objects from MinIO s3 = s3fs.S3FileSystem() # Split the documents and save the metadata to warehouse bucket def create_object_task(json_data): for record in json_data["Records"]: bucket_name = record["s3"]["bucket"]["name"] object_key = urllib.parse.unquote(record["s3"]["object"]["key"]) print(record["s3"]["bucket"]["name"], record["s3"]["object"]["key"]) doc_splits = split_doc_by_chunks(bucket_name, object_key) for i, chunk in enumerate(doc_splits): source = f"warehouse/{METADATA_PREFIX}/{bucket_name}/{object_key}/chunk_{i:05d}.json" with s3.open(source, "w") as f: f.write(chunk.json()) return "Task completed!" def delete_object_task(json_data): for record in json_data["Records"]: bucket_name = record["s3"]["bucket"]["name"] object_key = urllib.parse.unquote(record["s3"]["object"]["key"]) s3.delete(f"warehouse/{METADATA_PREFIX}/{bucket_name}/{object_key}", recursive=True) return "Task completed!" Update FastAPI server with the new logic import json import gradio as gr import requests from fastapi import FastAPI, Request, BackgroundTasks from pydantic import BaseModel import uvicorn import nest_asyncio app = FastAPI() @app.post("/api/v1/document/notification") async def receive_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() if json_data["EventName"] == "s3:ObjectCreated:Put": print("New object created!") background_tasks.add_task(create_object_task, json_data) if json_data["EventName"] == "s3:ObjectRemoved:Delete": print("Object deleted!") background_tasks.add_task(delete_object_task, json_data) return {"status": "success"} with gr.Blocks(gr.themes.Soft()) as demo: gr.Markdown("## RAG with MinIO") ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear") ch_interface.chatbot.show_label = False demo.queue() if __name__ == "__main__": nest_asyncio.apply() app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH) uvicorn.run(app, host="0.0.0.0", port=8808) Add new webhook to process document metadata/chunksNow that we have the first webhook working next step is the get all the chunks with metadata Generate the Embeddings and store it in the vector Database
\
\
import json import gradio as gr import requests from fastapi import FastAPI, Request, BackgroundTasks from pydantic import BaseModel import uvicorn import nest_asyncio app = FastAPI() @app.post("/api/v1/metadata/notification") async def receive_metadata_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() print(json.dumps(json_data, indent=2)) @app.post("/api/v1/document/notification") async def receive_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() if json_data["EventName"] == "s3:ObjectCreated:Put": print("New object created!") background_tasks.add_task(create_object_task, json_data) if json_data["EventName"] == "s3:ObjectRemoved:Delete": print("Object deleted!") background_tasks.add_task(delete_object_task, json_data) return {"status": "success"} with gr.Blocks(gr.themes.Soft()) as demo: gr.Markdown("## RAG with MinIO") ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear") ch_interface.chatbot.show_label = False demo.queue() if __name__ == "__main__": nest_asyncio.apply() app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH) uvicorn.run(app, host="0.0.0.0", port=8808)\
Create MinIO Event Notifications and Link it to warehouse Bucket Creat Webhook EventIn Console go to Events-> Add Event Destination -> Webhook
\ Fill the fields with Following values and hit save
\ Identifier - metadata-webhook
\ Endpoint - http://localhost:8808/api/v1/metadata/notification
\ Click Restart MinIO at the top when prompted to
\ (Note: You can also use mc for this)
Link the Webhook Event to custom-corpus bucket EventsIn console go to Buckets (Administrator) -> warehouse -> Events
\ Fill the fields with Following values and hit save
\ ARN - Select the metadata-webhook from dropdown
\ Prefix - metadata/
\ Suffix - .json
\ Select Events - Check PUT and DELETE
\ (Note: You can also use mc for this)
\ We have our first webhook setup
Now test by adding and removing an object in custom-corpus and see if this webhook gets triggered Create LanceDB Vector Database in MinIONow that we have the basic webhook working, lets setup the lanceDB vector databse in MinIO warehouse bucket in which we will save all the embeddings and additional metadata fields
\
import os import lancedb # Set these environment variables for the lanceDB to connect to MinIO os.environ["AWS_DEFAULT_REGION"] = "us-east-1" os.environ["AWS_ACCESS_KEY_ID"] = MINIO_ACCESS_KEY os.environ["AWS_SECRET_ACCESS_KEY"] = MINIO_SECRET_KEY os.environ["AWS_ENDPOINT"] = MINIO_ENDPOINT os.environ["ALLOW_HTTP"] = "True" db = lancedb.connect("s3://warehouse/v-db/")\
# list existing tables db.table_names()\
# Create a new table with pydantic schema from lancedb.pydantic import LanceModel, Vector import pyarrow as pa DOCS_TABLE = "docs" EMBEDDINGS_DIM = 768 table = None class DocsModel(LanceModel): parent_source: str # Actual object/document source source: str # Chunk/Metadata source text: str # Chunked text vector: Vector(EMBEDDINGS_DIM, pa.float16()) # Vector to be stored def get_or_create_table(): global table if table is None and DOCS_TABLE not in list(db.table_names()): return db.create_table(DOCS_TABLE, schema=DocsModel) if table is None: table = db.open_table(DOCS_TABLE) return table\
# Check if that worked get_or_create_table()\
# list existing tables db.table_names() Add Storing/removing data from lanceDB to metadata-webhook import multiprocessing EMBEDDING_DOCUMENT_PREFIX = "search_document" # Add queue that keeps the processed meteadata in memory add_data_queue = multiprocessing.Queue() delete_data_queue = multiprocessing.Queue() def create_metadata_task(json_data): for record in json_data["Records"]: bucket_name = record["s3"]["bucket"]["name"] object_key = urllib.parse.unquote(record["s3"]["object"]["key"]) print(bucket_name, object_key) with s3.open(f"{bucket_name}/{object_key}", "r") as f: data = f.read() chunk_json = json.loads(data) embeddings = get_embedding(f"{EMBEDDING_DOCUMENT_PREFIX}: {chunk_json['page_content']}") add_data_queue.put({ "text": chunk_json["page_content"], "parent_source": chunk_json.get("metadata", "").get("source", ""), "source": f"{bucket_name}/{object_key}", "vector": embeddings }) return "Metadata Create Task Completed!" def delete_metadata_task(json_data): for record in json_data["Records"]: bucket_name = record["s3"]["bucket"]["name"] object_key = urllib.parse.unquote(record["s3"]["object"]["key"]) delete_data_queue.put(f"{bucket_name}/{object_key}") return "Metadata Delete Task completed!" Add a scheduler that Processes Data from Queues from apscheduler.schedulers.background import BackgroundScheduler import pandas as pd def add_vector_job(): data = [] table = get_or_create_table() while not add_data_queue.empty(): item = add_data_queue.get() data.append(item) if len(data) > 0: df = pd.DataFrame(data) table.add(df) table.compact_files() print(len(table.to_pandas())) def delete_vector_job(): table = get_or_create_table() source_data = [] while not delete_data_queue.empty(): item = delete_data_queue.get() source_data.append(item) if len(source_data) > 0: filter_data = ", ".join([f'"{d}"' for d in source_data]) table.delete(f'source IN ({filter_data})') table.compact_files() table.cleanup_old_versions() print(len(table.to_pandas())) scheduler = BackgroundScheduler() scheduler.add_job(add_vector_job, 'interval', seconds=10) scheduler.add_job(delete_vector_job, 'interval', seconds=10) Update FastAPI with the Vector Embedding Changes import json import gradio as gr import requests from fastapi import FastAPI, Request, BackgroundTasks from pydantic import BaseModel import uvicorn import nest_asyncio app = FastAPI() @app.on_event("startup") async def startup_event(): get_or_create_table() if not scheduler.running: scheduler.start() @app.on_event("shutdown") async def shutdown_event(): scheduler.shutdown() @app.post("/api/v1/metadata/notification") async def receive_metadata_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() if json_data["EventName"] == "s3:ObjectCreated:Put": print("New Metadata created!") background_tasks.add_task(create_metadata_task, json_data) if json_data["EventName"] == "s3:ObjectRemoved:Delete": print("Metadata deleted!") background_tasks.add_task(delete_metadata_task, json_data) return {"status": "success"} @app.post("/api/v1/document/notification") async def receive_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() if json_data["EventName"] == "s3:ObjectCreated:Put": print("New object created!") background_tasks.add_task(create_object_task, json_data) if json_data["EventName"] == "s3:ObjectRemoved:Delete": print("Object deleted!") background_tasks.add_task(delete_object_task, json_data) return {"status": "success"} with gr.Blocks(gr.themes.Soft()) as demo: gr.Markdown("## RAG with MinIO") ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear") ch_interface.chatbot.show_label = False ch_interface.chatbot.height = 600 demo.queue() if __name__ == "__main__": nest_asyncio.apply() app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH) uvicorn.run(app, host="0.0.0.0", port=8808)\
\
\ Now that we have the Ingestion pipeline working let's integrate the final RAG pipeline.
Add Vector Search CapabilityNow that we have the document ingested into the lanceDB let's add the search capability
\
EMBEDDING_QUERY_PREFIX = "search_query" def search(query, limit=5): query_embedding = get_embedding(f"{EMBEDDING_QUERY_PREFIX}: {query}") res = get_or_create_table().search(query_embedding).metric("cosine").limit(limit) return res\
# Lets test to see if it works res = search("What is MinIO Enterprise Object Store Lite?") res.to_list() Prompt LLM to use the Relevant Documents RAG_PROMPT = """ DOCUMENT: {documents} QUESTION: {user_question} INSTRUCTIONS: Answer in detail the user's QUESTION using the DOCUMENT text above. Keep your answer ground in the facts of the DOCUMENT. Do not use sentence like "The document states" citing the document. If the DOCUMENT doesn't contain the facts to answer the QUESTION only Respond with "Sorry! I Don't know" """\
context_df = [] def llm_chat(user_question, history): history = history or [] global context_df # Search for relevant document chunks res = search(user_question) documents = " ".join([d["text"].strip() for d in res.to_list()]) # Pass the chunks to LLM for grounded response llm_resp = requests.post(LLM_ENDPOINT, json={"model": LLM_MODEL, "messages": [ {"role": "user", "content": RAG_PROMPT.format(user_question=user_question, documents=documents) } ], "options": { # "temperature": 0, "top_p": 0.90, }}, stream=True) bot_response = "**AI:** " for resp in llm_resp.iter_lines(): json_data = json.loads(resp) bot_response += json_data["message"]["content"] yield bot_response context_df = res.to_pandas() context_df = context_df.drop(columns=['source', 'vector']) def clear_events(): global context_df context_df = [] return context_df Update FastAPI Chat Endpoint to use RAG import json import gradio as gr import requests from fastapi import FastAPI, Request, BackgroundTasks from pydantic import BaseModel import uvicorn import nest_asyncio app = FastAPI() @app.on_event("startup") async def startup_event(): get_or_create_table() if not scheduler.running: scheduler.start() @app.on_event("shutdown") async def shutdown_event(): scheduler.shutdown() @app.post("/api/v1/metadata/notification") async def receive_metadata_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() if json_data["EventName"] == "s3:ObjectCreated:Put": print("New Metadata created!") background_tasks.add_task(create_metadata_task, json_data) if json_data["EventName"] == "s3:ObjectRemoved:Delete": print("Metadata deleted!") background_tasks.add_task(delete_metadata_task, json_data) return {"status": "success"} @app.post("/api/v1/document/notification") async def receive_webhook(request: Request, background_tasks: BackgroundTasks): json_data = await request.json() if json_data["EventName"] == "s3:ObjectCreated:Put": print("New object created!") background_tasks.add_task(create_object_task, json_data) if json_data["EventName"] == "s3:ObjectRemoved:Delete": print("Object deleted!") background_tasks.add_task(delete_object_task, json_data) return {"status": "success"} with gr.Blocks(gr.themes.Soft()) as demo: gr.Markdown("## RAG with MinIO") ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear") ch_interface.chatbot.show_label = False ch_interface.chatbot.height = 600 gr.Markdown("### Context Supplied") context_dataframe = gr.DataFrame(headers=["parent_source", "text", "_distance"], wrap=True) ch_interface.clear_btn.click(clear_events, [], context_dataframe) @gr.on(ch_interface.output_components, inputs=[ch_interface.chatbot], outputs=[context_dataframe]) def update_chat_context_df(text): global context_df if context_df is not None: return context_df return "" demo.queue() if __name__ == "__main__": nest_asyncio.apply() app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH) uvicorn.run(app, host="0.0.0.0", port=8808)\ Were you able to go through and implement RAG based chat with MinIO as the data lake backend? We will in the near future do a webinar on this same topic where we will give you a live demo as we build this RAG based chat application.
RAGs-R-UsAs a developer focused on AI integration at MinIO, I am constantly exploring how our tools can be seamlessly integrated into modern AI architectures to enhance efficiency and scalability. In this article, we showed you how to integrate MinIO with Retrieval-Augmented Generation (RAG) to build a chat application. This is just the tip of the iceberg, to give you a boost in your quest to build more unique used cases for RAG and MinIO. Now you have the building blocks to do it. Let's do it!
\ If you have any questions on MinIO RAG integration be sure to reach out to us on Slack!