and the distribution of digital products.
The Specifics Of Data Affect Augmentation-Induced Bias
:::info Authors:
(1) Athanasios Angelakis, Amsterdam University Medical Center, University of Amsterdam - Data Science Center, Amsterdam Public Health Research Institute, Amsterdam, Netherlands
(2) Andrey Rass, Den Haag, Netherlands.
:::
Table of Links- Abstract and 1 Introduction
- 2 The Effect Of Data Augmentation-Induced Class-Specific Bias Is Influenced By Data, Regularization and Architecture
- 2.1 Data Augmentation Robustness Scouting
- 2.2 The Specifics Of Data Affect Augmentation-Induced Bias
- 2.3 Adding Random Horizontal Flipping Contributes To Augmentation-Induced Bias
- 2.4 Alternative Architectures Have Variable Effect On Augmentation-Induced Bias
- 3 Conclusion and Limitations, and References
- Appendices A-L
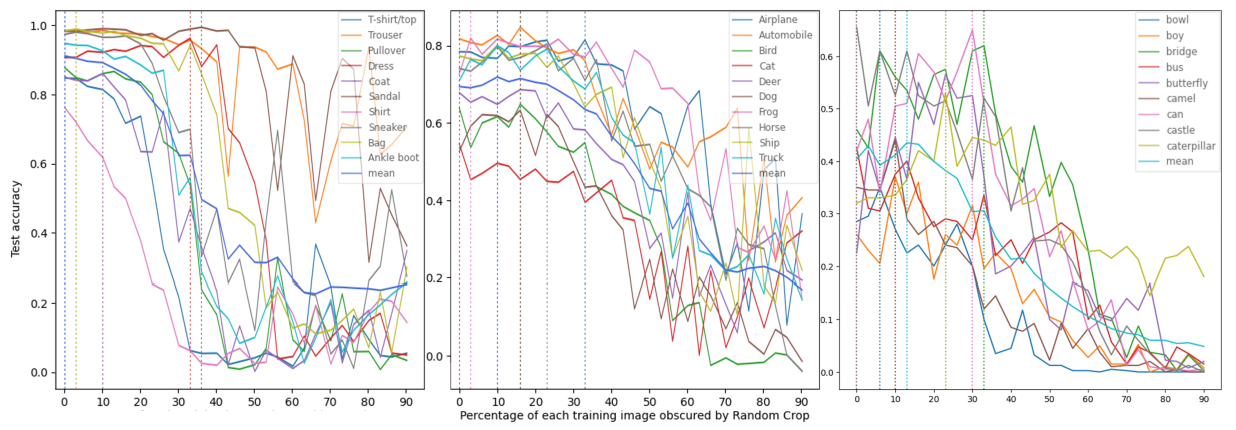
As a key part of our data-centric analysis of the bias-inducing effects of DA detailed by Balestriero, Bottou, and LeCun (2022), we conducted a series of experiments based on the paper’s initial proposal of training and evaluating a set of CNN models while adjusting a DA regime represented as a function of some parameter α between batches of runs (see Figure 2 for results). To focus the scope of our research, we have limited the experiments in this section to using ResNet50 as the architecture of choice, with Random Horizontal Flipping applied combined with Random Cropping with increasing portions of the training images obscured as the parametrized augmentation. For illustrative purposes, three datasets were chosen for the purposes of the trial to provide a relative diversity of content: Fashion-MNIST, CIFAR-10 and CIFAR-100. All three datasets differ from ImageNet in possessing a much smaller image quantity (< 100K vs. > 1M), class
\

\ count (≤ 100 vs. > 1K), and image size (< 40px vs. > 200px). There are some additional distinctions: Fashion-MNIST consists of greyscale top-down photos of clothing items, whereas CIFAR-100 has very few images per class, despite CIFAR datasets being otherwise quite close in subject matter to ImageNet.
\ Despite significantly fewer runs, the results of our experiments do clearly illustrate the label-erasing effect of excessive DA application and its strong variation between classes, as seen, for example, in the performances of the Coat, Dress, Shirt and Sandal in Figure 2, each of which experiences distinctive performance dynamics as α increases, and each category has a different threshold of α past which label-loss from Random Cropping occurs rapidly (as illustrated by a rapid drop-off in test set accuracy). In addition to confirming class-specific DA-induced bias, we observe a very clear difference across the three datasets in terms of the speed at which this effect is seen in mean performance, as well as the degree of difference between individual classes. This can be attributed to the complexity of each dataset, but also clearly illustrates how ”robustness” to classpecific bias from DA can vary heavily between datasets in the same way as it can between classes. While this difference is noticeable between the three observed datasets, it is even more stark when compared to ImageNet’s performance in Balestriero, Bottou, and LeCun (2022), as label loss and corresponding mean test set performance decline occur at much earlier values of α in our observations.
\ As in Balestriero, Bottou, and LeCun (2022), mean test set performance in all cases follows a trend of ”increase, fall, level off” as α pushes all but the most robust classes past the threshold of complete label loss (for example, in the Figure 2, the mean accuracy on CIFAR-10 reaches its highest point of 0.764 at 10% α, then rapidly declines until an α of 70%, after which it levels off at around 0.21. On the other hand, the Fashion-MNIST plot is very illustrative of class-specific behaviors, as we see the ”Sandal” class reach its peak accuracy of 0.994 at an α as late as 36%, while ”Coat” begins to drop from 0.86 down to near-zero accuracies as early as 10% and 43%, respectively. For a full summary of the diverse α at which each class and mean test set performance reach their peak, see Appendices F, G and H.
\ The causes of this dataset-specific bias robustness can be narrowed to two causes - overall complexity as a learning task (e.g. Fashion-MNIST is ”simple to solve”, and thus experiences minimal benefit from regularization before reaching detriment), as well as robustness to label loss from a given DA, which can occur on dataset or class level. Class-level robustness can be illustrated by comparing the performance of the T-Shirt and Trouser classes in Figure 2, as images belonging to the Trouser class are quite visually distinct from most other categories even at higher levels of cropping, while the T-Shirt class quickly loses its identity with increased α values, manifesting in the visible performance difference. Dataset-level robustness can occur due to such factors as training images containing more information (e.g. ”zoomed-out” depictions of objects, higher image size, as well as RGB color), and can be seen in how the CIFAR datasets’ mean performance and its dynamics relative to α compare to Fashion-MNIST.
\ Here, a promising direction for research could be to conduct a range of similar experiments on datasets picked out specifically with this robustness to a particular DA in mind - for example, a dataset such as the Describable Textures Dataset (Cimpoi et al. 2014) consists of images of objects with a focus on texture, with 47 classes, such as ”braided”, ”dotted”, ”honeycombed”, ”woven”. By nature, textures are repeating patterns, and as such, at least some of the featured classes should be very resilient to random cropping. For example, if the image features a ”chequered” texture with a 10x10 grid of squares, then cropping out up to 89% of the original image would still not obscure the pattern.
\ It is also worth noting that the mean performance decline in our experiments occurs at a more drastic rate than in Balestriero, Bottou, and LeCun (2022). This could have been caused by differences in DA implementation, but could also stem from differences in the training data used. For example, while a human observer may conclude that the same amount of information is being removed by cropping images using the same α, this is not the case from a model’s perspective, as the absolute count of pixels removed by this operation depends on the original size of the images. This, in turn, is another possible avenue for future inquiry: experiments could be run on entirely new datasets with varying image sizes, or alternatively, on the same datasets used in this work, but with the training images upscaled.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\