and the distribution of digital products.
Primer on Large Language Model (LLM) Inference Optimizations: 2. Introduction to Artificial Intelligence (AI) Accelerators
Exploration of AI accelerators and their impact on deploying Large Language Models (LLMs) at scale.
\ Posts in this series:
Primer on Large Language Model (LLM) Inference Optimizations: 1. Background and Problem Formulation
Primer on Large Language Model (LLM) Inference Optimizations: 2. Introduction to Artificial Intelligence (AI) Accelerators (this post)
\
In the previous post, we discussed the challenges of Large Language Model (LLM) inference, such as high latency, intensive resource consumption, and scalability issues. Addressing these issues effectively often requires the right hardware support. This post delves into AI accelerators—specialized hardware designed to enhance the performance of AI workloads, including LLM inference—highlighting their architecture, key types, and impact on deploying LLMs at scale.
Why AI Accelerators?If you ever wondered how companies like OpenAI and Google manage to run these massive language models serving millions of users simultaneously, the secret lies in specialized hardware called AI accelerators. While traditional CPUs handle general-purpose tasks well, they aren’t optimized for the demands of AI workloads. AI accelerators, by contrast, are purpose-built for AI tasks, offering high-speed data access, parallel processing capabilities, and support for low-precision arithmetic. By shifting computation to AI accelerators, organizations can achieve significant performance gains and reduce costs, especially when running complex models like LLMs. Let’s explore some common types of AI accelerators and their unique advantages for these workloads.
Types of AI AcceleratorsAI accelerators come in several forms, each tailored for specific AI tasks and environments. The three main types are GPUs, TPUs, and FPGAs/ASICs, each with unique features and advantages:
Graphics Processing Units (GPUs)Originally developed for graphics rendering, GPUs have become a powerful tool for deep learning tasks due to their parallel processing capabilities. Their architecture is well-suited for high-throughput matrix calculations, which are essential for tasks like LLM inference. GPUs are particularly popular in data centers for training and inference at scale. GPUs like NVIDIA Tesla, AMD Radeon, and Intel Xe being widely used in both cloud and on-premises environments.
Tensor Processing Units (TPUs)Google developed TPUs specifically for deep learning workloads, with optimizations for TensorFlow-based training and inference. TPUs are designed to accelerate large-scale AI tasks efficiently, powering many of Google’s applications, including search and translation. Available through Google Cloud, TPUs offer high performance for both training and inference, making them a preferred choice for TensorFlow users.
Field-Programmable Gate Arrays (FPGAs) / Application-Specific Integrated Circuits (ASICs)FPGAs and ASICs are two distinct types of customizable accelerators that support specific AI tasks. FPGAs are reprogrammable, which allow them to adapt to different AI models and applications, while ASICs are purpose-built for specific tasks, offering maximum efficiency for those workloads. Both types are used in data centers and at the edge, where low latency and high throughput are crucial. Examples include Intel Arria and Xilinx Alveo (FPGAs) and Google’s Edge TPU (ASICs).
Key differences between CPUs and AI AcceleratorsThe distinct architectures of CPUs and AI accelerators make them suited for different types of workloads. Here’s a comparison of some of the most critical features:
- Architecture: While CPUs are general-purpose processors, AI accelerators are specialized hardware optimized for AI workloads. CPUs typically have fewer cores but high clock speeds, making them ideal for tasks requiring quick single-threaded performance. AI accelerators, however, have thousands of cores optimized for parallel processing and high throughput.
- Precision and Memory: CPUs often use high-precision arithmetic and large cache memory, which supports general computing tasks. In contrast, AI accelerators support low-precision arithmetic, like 8-bit or 16-bit, reducing memory footprint and energy consumption without compromising much on accuracy—key for LLM inference.
- Energy Efficiency: Designed for high-intensity AI tasks, accelerators consume significantly less power per operation than CPUs, contributing to both cost savings and lower environmental impact when deployed at scale.
\
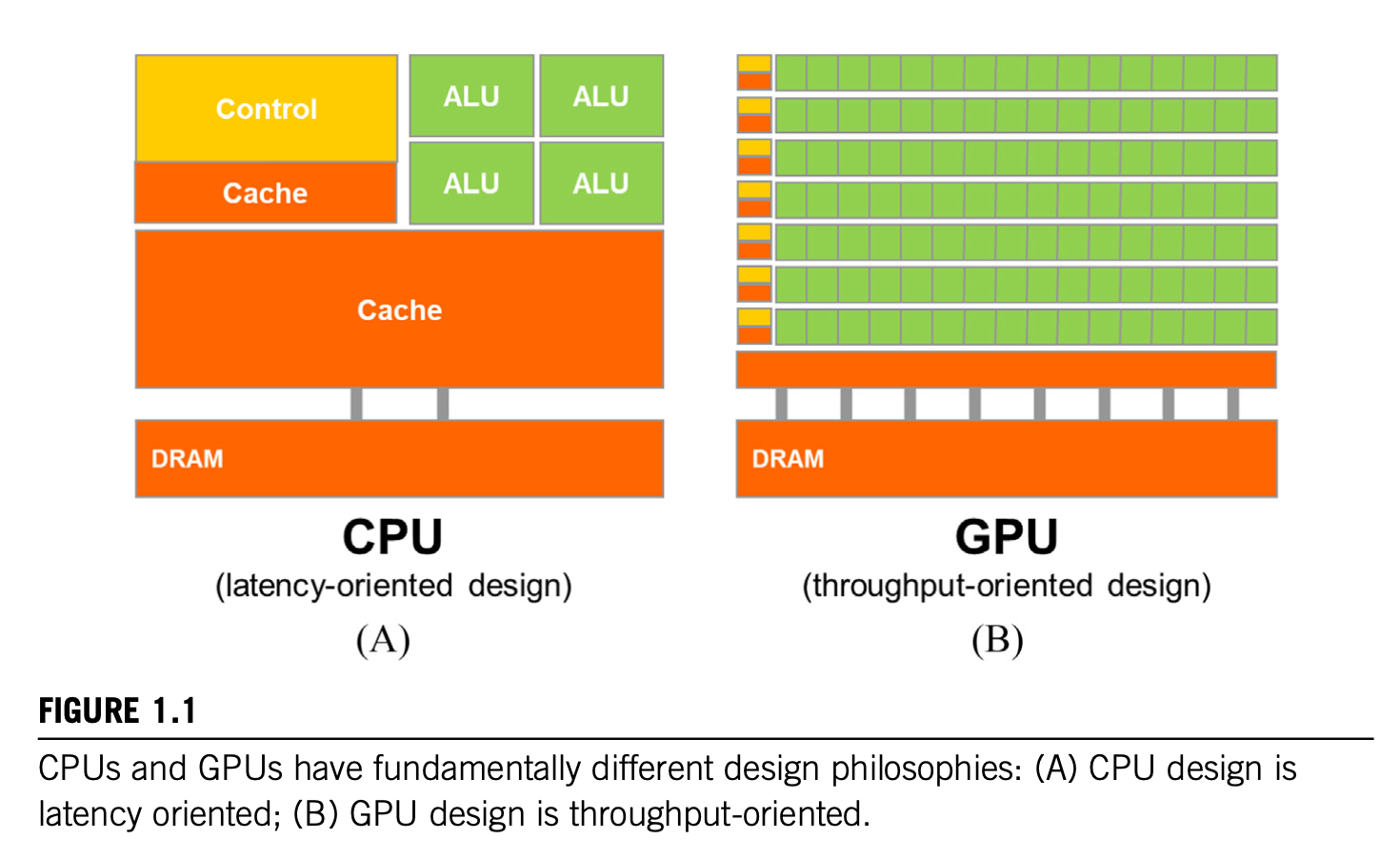 Reference: Programming Massively Parallel Processors by David B. Kirk and Wen-mei W. Hwu [1]
Reference: Programming Massively Parallel Processors by David B. Kirk and Wen-mei W. Hwu [1]
\ Note that in CPU there are fewer cores (4-8) and the design is optimized for low latency and high single-threaded performance. In contrast, GPUs have thousands of cores and are optimized for high throughput and parallel processing. This parallel processing capability allows GPUs to handle large-scale AI workloads efficiently.
Key Features of AI Accelerators & Impact on LLM InferenceAI accelerators are built with several features that make them ideal for handling large-scale AI workloads like LLM inference. Key features include:
Parallel ProcessingAI accelerators are designed for large-scale parallel processing, thanks to their architecture with thousands of cores. This parallelism allows them to handle the intensive matrix calculations required in LLM inference efficiently. Many accelerators also include specialized tensor cores, which are optimized for tensor operations such as matrix multiplications. These capabilities make AI accelerators significantly faster than CPUs when processing LLM tasks at scale.
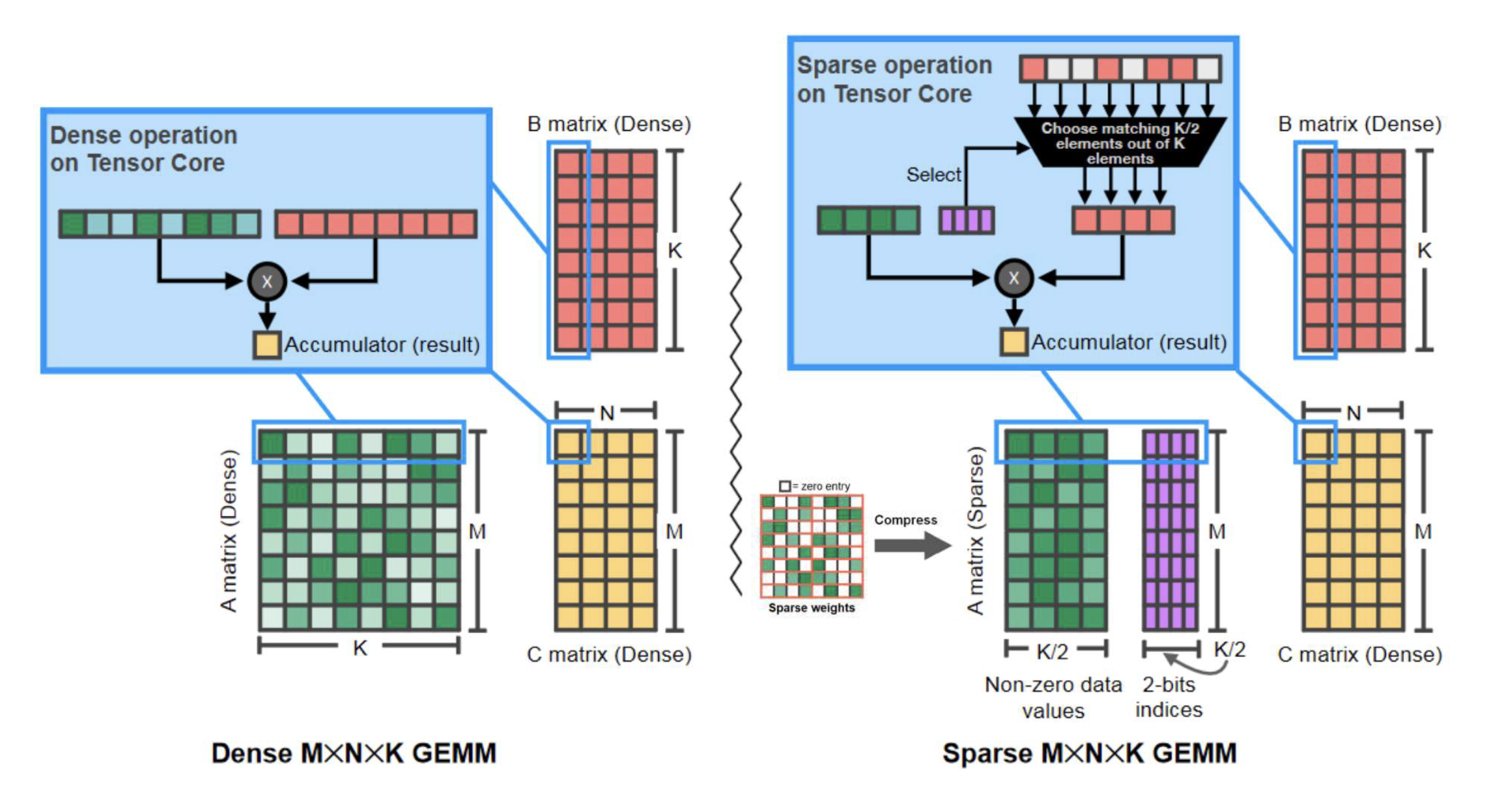 Reference: Inference Optimization of Foundation Models on AI Accelerators by Youngsuk Park, et al.
Reference: Inference Optimization of Foundation Models on AI Accelerators by Youngsuk Park, et al.
Accelerators come with specialized memory that enables high bandwidth, allowing them to access large datasets and model parameters with minimal latency. This feature is essential for LLM inference, where frequent data access is required to load input text and model parameters. High-bandwidth memory reduces the bottleneck in data retrieval, resulting in lower latency and improved performance.
High Speed Interconnect BandwidthAI accelerators are equipped with high-speed interconnects to facilitate fast data transfer within multi-device setups. This is particularly important for scaling LLM inference across multiple devices, where accelerators need to communicate and share data efficiently. High interconnect bandwidth ensures that large datasets can be split across devices and processed in tandem without causing bottlenecks.
Low Precision ArithmeticAnother advantage of AI accelerators is their support for low-precision arithmetic, such as 8-bit integer and 16-bit floating-point calculations. This reduces memory usage and energy consumption, making AI tasks more efficient. For LLM inference, low-precision calculations provide faster processing while maintaining sufficient accuracy for most applications. AI accelerators have very rich data type selection.
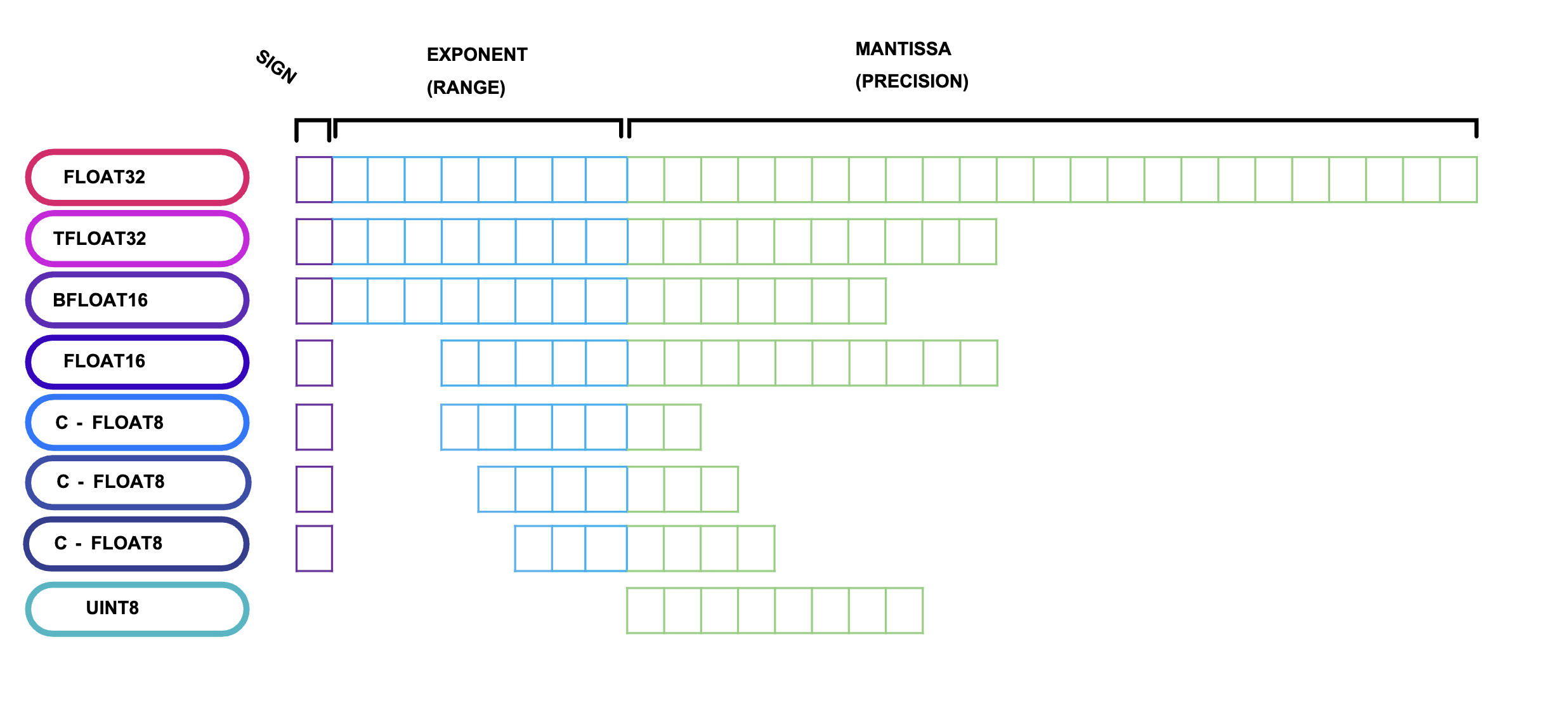 Reference: Inference Optimization of Foundation Models on AI Accelerators by Youngsuk Park, et al.
Reference: Inference Optimization of Foundation Models on AI Accelerators by Youngsuk Park, et al.
Most AI accelerators come with optimized libraries for popular AI frameworks, such as cuDNN for NVIDIA GPUs and XLA for Google TPUs. These libraries provide high-level APIs for performing common AI operations and include optimizations specifically for LLMs. Using these libraries enables faster model development, deployment, and inference optimization.
Scalability and Energy EfficiencyAI accelerators are highly scalable, allowing for deployment in clusters or data centers to handle large workloads efficiently. They are also designed to be energy-efficient, consuming less power than CPUs for comparable tasks, which makes them ideal for computationally intensive applications like LLM inference at scale. This efficiency helps reduce both the operational cost and environmental impact of running large AI models.
Parallelism in AI AcceleratorsDifferent types of parallelism techniques are employed to maximize the efficiency of AI accelerators for LLM inference:
Data ParallelismData parallelism involves splitting the input data into multiple batches and processing each batch in parallel. This is useful for AI workloads that involve large datasets, such as deep learning training and inference. By distributing the data across multiple devices, AI accelerators can process the workload faster and improve overall performance. An example of data parallelism in LLM inference is splitting the input text into batches and processing each batch on a separate accelerator.
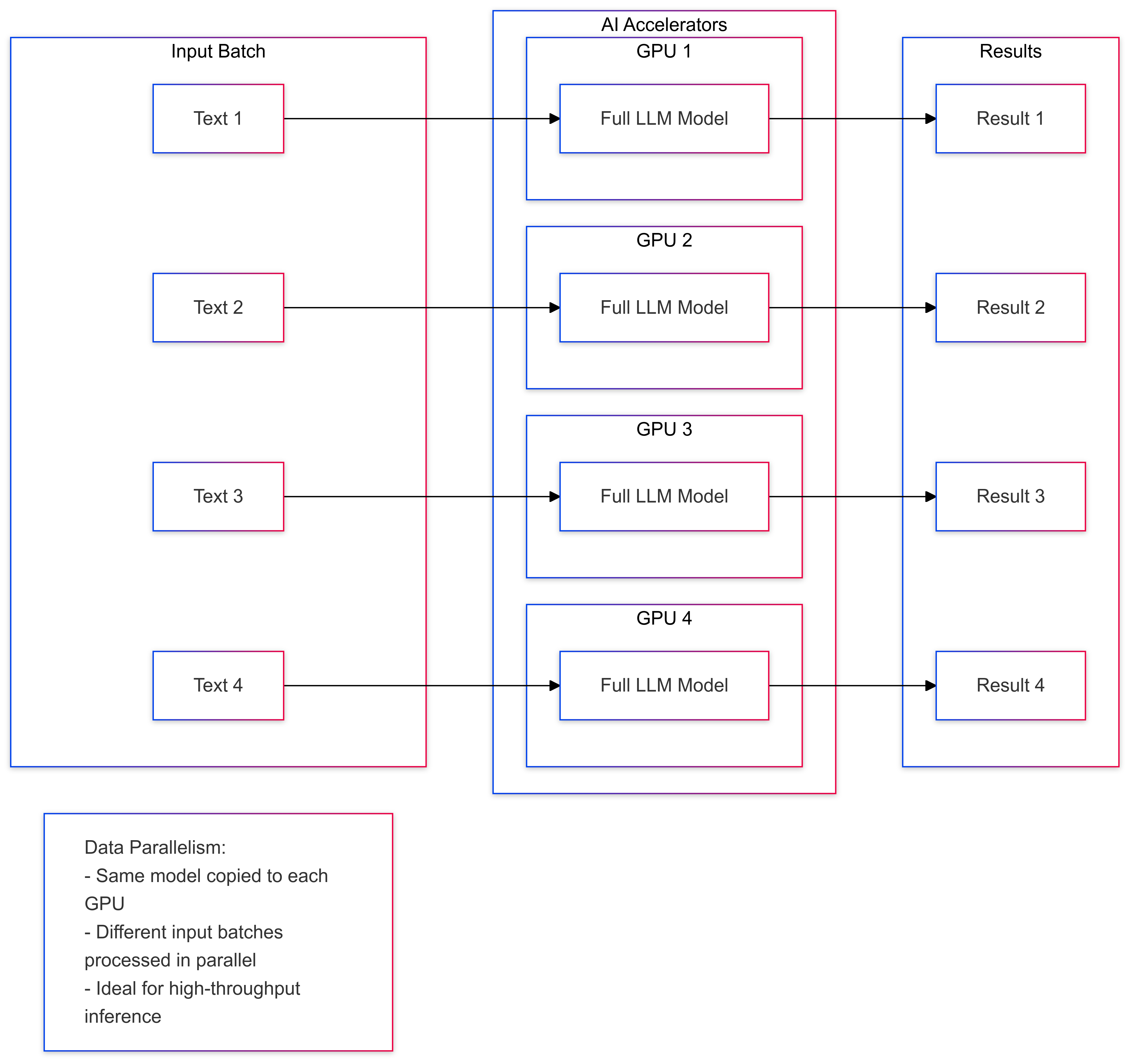
Model parallelism involves splitting the AI model’s components across multiple devices, enabling parallel processing of different model parts. This approach is particularly crucial for large AI models that exceed single-device memory capacity or require distributed computation for efficient processing. Model parallelism is widely used in large language models (LLMs) and other deep learning architectures where model size is a significant constraint.
Model parallelism can be implemented in two main approaches:
Intra-layer Parallelism (Tensor Parallelism): Individual layers or components are split across devices, with each device handling a portion of the computation within the same layer. For example, in transformer models, attention heads or feed-forward network layers can be distributed across multiple devices. This approach minimizes communication overhead since devices only need to synchronize at layer boundaries.
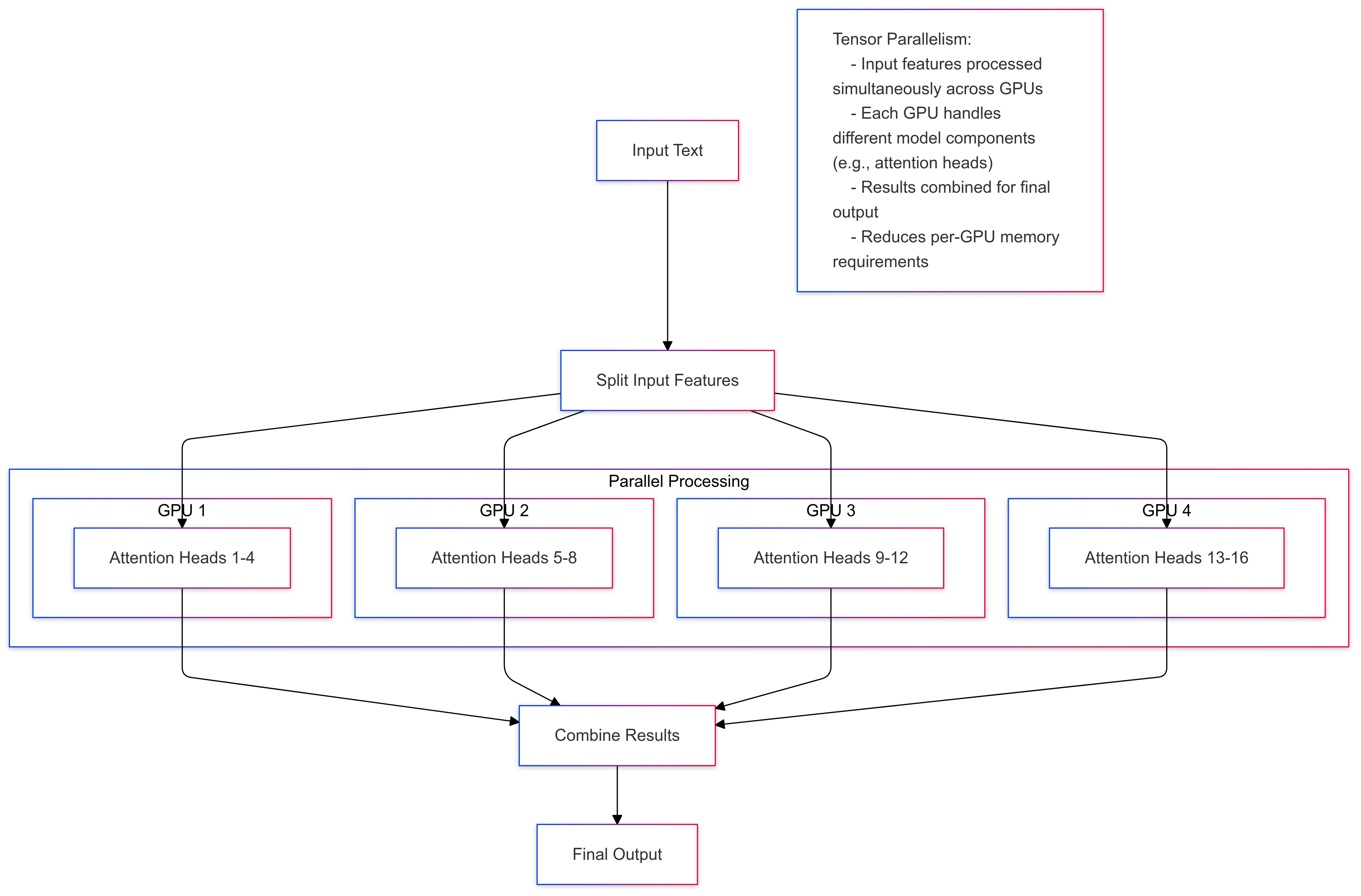
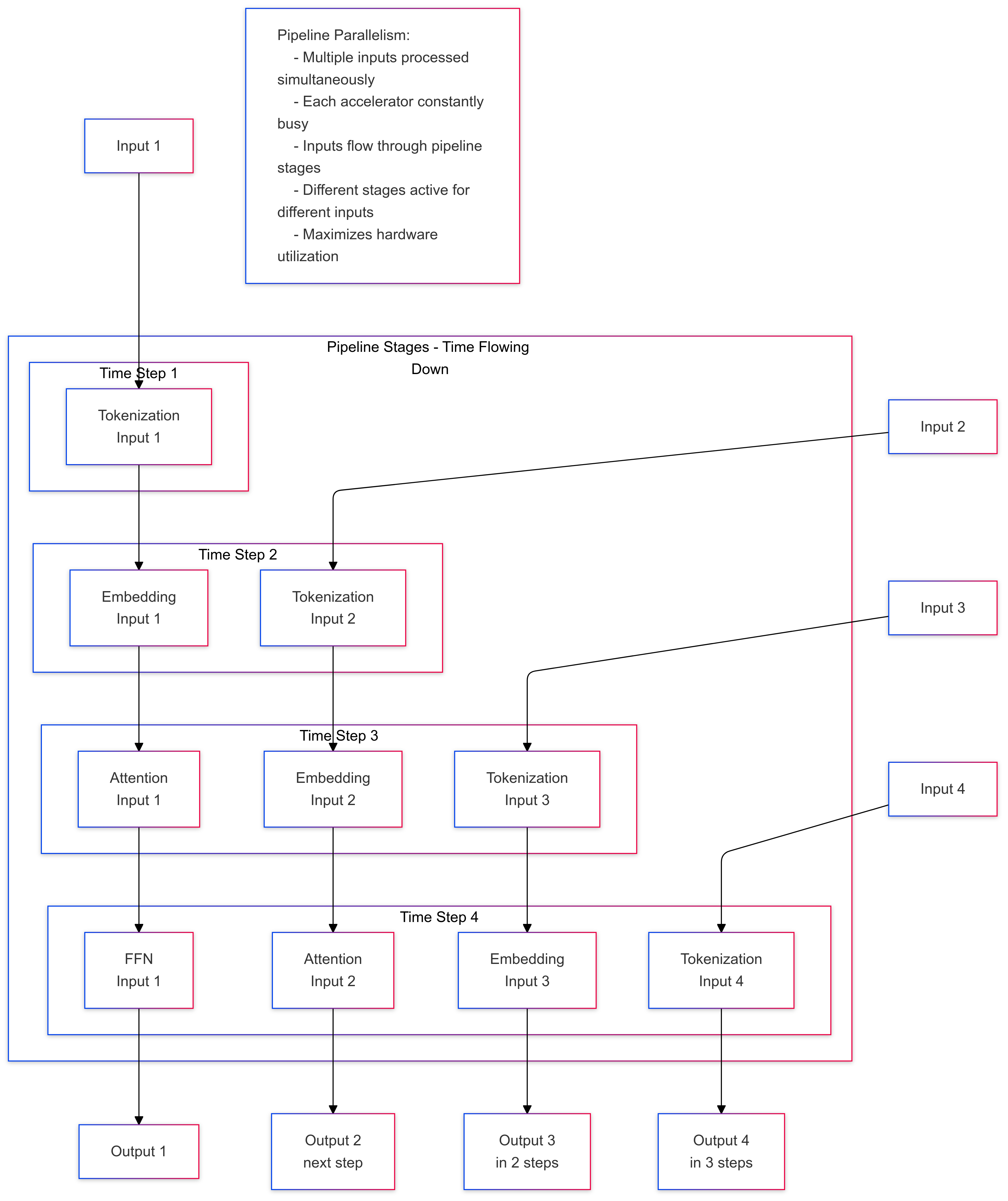
Inter-layer Parallelism (Pipeline Parallelism): Sequential groups of layers are distributed across devices, creating a pipeline of computation. Each device processes its assigned layers before passing the results to the next device in the pipeline. This approach is particularly effective for deep networks but introduces pipeline latency.
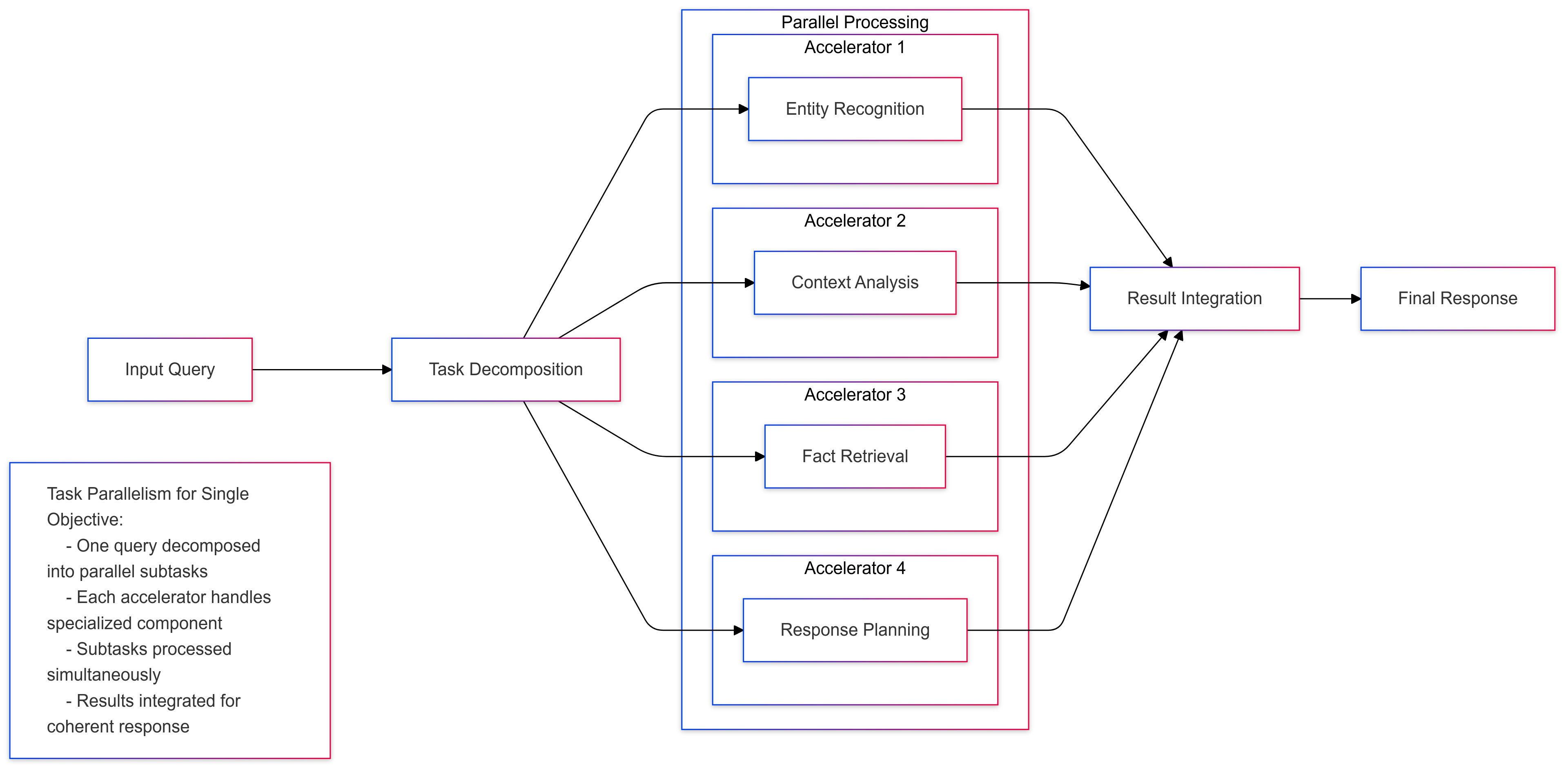
Task parallelism involves splitting the AI workload into multiple tasks and processing each task in parallel. This is useful for AI workloads that involve multiple independent tasks, such as autonomous driving. By processing the tasks in parallel, AI accelerators can reduce the time it takes to complete complex tasks and improve overall performance. Task parallelism is often used in AI accelerators for tasks like object detection and video analysis.
Consider an LLM with 70 billion parameters processing a batch of text inputs:
- Data Parallelism: The input batch is split across multiple GPUs, each processing a portion of the inputs independently.
- Tensor Parallelism: The transformer model’s attention heads are distributed across multiple devices, with each device handling a subset of the heads.
- Pipeline Parallelism: The transformer model’s layers are split into sequential groups, with each group processed by a different device in a pipelined fashion.
- Task Parallelism: Multiple independent inference requests are processed simultaneously on different accelerator units.
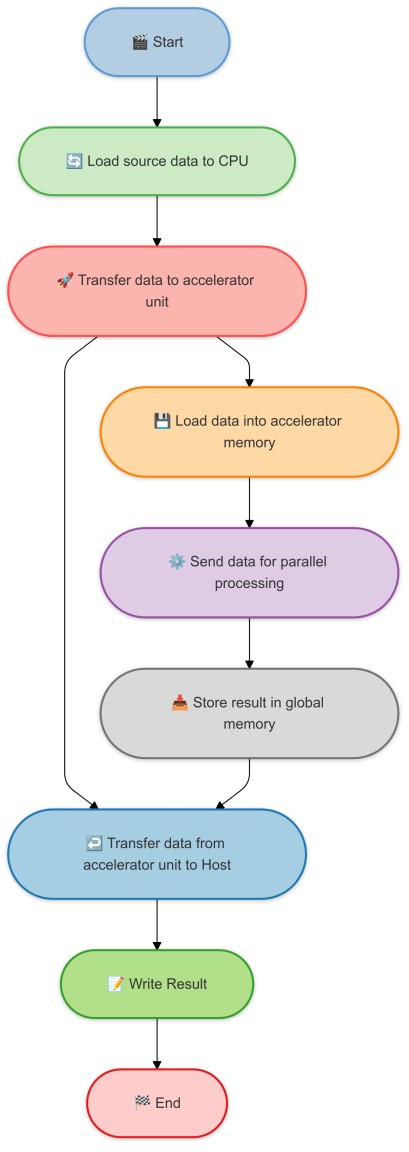
AI Accelerators often work in tandem with the main CPU to offload the heavy computation tasks. The main CPU is responsible for the general purpose tasks and the AI Accelerators are responsible for the heavy computation tasks. This is usually called co-processing. Here is a simple diagram to show how the AI Accelerators work with the main CPU. Here is some brief nomenclature for co-processing:
Host: The main CPU. It is responsible for the main flow of the program. It orchestrates the task by loading the main data and handling input/output operations. In co-processing mode, the host initiates the process, transfers data to AI Accelerators, and receives the results. It handles all the non-computation logic and leaves the number crunching to the AI Accelerators.
Device: The AI Accelerators. They are responsible for the heavy computation tasks. After receiving data from the host, the accelerator loads it into its specialized memory and performs parallel processing optimized for AI workloads, such as matrix multiplications. Once it completes the processing, it stores the results and transfers them back to the host.
As AI workloads continue to grow in complexity and scale, AI accelerators are evolving to meet the demands of modern applications. Some key trends shaping the future of AI accelerators [3] include:
Intelligent Processing Units (IPUs)Developed by Graphcore, IPUs are designed to handle complex machine learning tasks with high efficiency. Their architecture focuses on parallel processing, making them suitable for large-scale AI workloads.
Reconfigurable Dataflow Units (RDUs)Developed by SambaNova Systems, RDUs are designed to accelerate AI workloads by optimizing data flow within the processor dynamically. This approach improves performance and efficiency for tasks like LLM inference.
Neural Processing Units (NPUs)NPUs are specialized for deep learning and neural network tasks, providing efficient data processing tailored to AI workloads. They are increasingly integrated into devices requiring on-device AI capabilities.
ConclusionIn this post, we discussed the role of AI accelerators in enhancing the performance of AI workloads, including LLM inference. By leveraging the parallel processing capabilities, high-speed memory, and low-precision arithmetic of accelerators, organizations can achieve significant performance gains and cost savings when deploying LLMs at scale. Understanding the key features and types of AI accelerators is essential for optimizing LLM inference and ensuring efficient resource utilization in large-scale AI deployments. In the next post, we will discuss the system optimization techniques for deploying LLMs at scale using AI accelerators.
References- [1] Programming Massively Parallel Processors by David B. Kirk and Wen-mei W. Hwu
- [2] Inference Optimization of Foundation Models on AI Accelerators by Youngsuk Park, et al.
- [3] Evaluating Emerging AI/ML Accelerators: IPU, RDU, and NVIDIA/AMD GPUs by Hongwu Peng, et al.
\