and the distribution of digital products.
Presto SQL + S3 Data + Superset = Data Lake
Apache Presto is an open-source, distributed SQL query engine that is optimized for running interactive analytic queries. It was developed by Facebook and is designed to query large datasets quickly and efficiently across various data sources. Presto allows for querying data directly in its native format, whether it's in Hadoop Distributed File System (HDFS), Amazon S3, relational databases, or other data storage systems. Presto is built from the ground up for efficient, low latency analytics. Presto Documentation
Key Features of Apache Presto\ Distributed Architecture: Presto's architecture allows for scalable query execution across multiple nodes, making it suitable for large-scale data analytics.
\ High Performance: Presto is engineered to execute queries with low latency, enabling interactive analysis of data.
\ SQL Compatibility: It supports ANSI SQL, which means users can write queries using a standard SQL syntax that is familiar to many data analysts and engineers. Presto SQL works with variety of connectors. I did some experiments to get it connect to AWS S3. I struggled a bit to get Presto SQL up and running and with an ability to query parquet files on S3.
\ Multi-Source Querying: Presto can query data from multiple sources within a single query. This includes data stored in Hadoop, relational databases, NoSQL databases, and other data stores.
\ Extensibility: The engine is designed to be extensible, allowing developers to add new data sources and functions through plugins.
\ Interactive Querying: It is designed for interactive querying rather than long-running batch jobs, making it suitable for data exploration and reporting.
\
Hive ConnectorPresto supports wide variety of connectors. Hive connector is one important connector which lets you connect presto to hive metastore(HMS). HMS manages the mapping between table definition and file system. The file system here could be HDFS or S3. Presto SQL works with hive metastore 3.0 and doesn't require HDFS or hive to be installed to get it working with Presto SQL.
Hive metastoreDownload hive metastore binary. Untar the tar ball, for example
/opt/apache-hive-metastore-3.0.0-bin
\ Update the metastore configuration
edit /opt/apache-hive-metastore-3.0.0-bin/conf/metastore-site.xml
\
\ Since we are using persistent metastore using mysql. We need to setup mysql to make sure it is able to talk to hive metastore.
Mysql configurationLogin on to mysql and create a database and user to manage HMS. Following DDL should suffice to do so
\
CREATE DATABASE hmsdb; CREATE USER 'hms'@'localhost' IDENTIFIED WITH mysql_native_password BY 'hms' ; GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, INDEX, DROP, ALTER, CREATE TEMPORARY TABLES, LOCK TABLES ON hmsdb.* TO 'hms'@'localhost'; GRANT FILE ON *.* TO 'hms'@'localhost';\ After creating the database and use make sure you test and connect to the hmsdb.
Initialize metastorecd /opt/apache-hive-metastore-3.0.0-bin ./bin/schematool -initSchema -dbType MYSQL
It will initialize the hive metastore and create all the tables. You can connect to hmsdb and check the tables
DDl for mysql\
$ mysql -u hms -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 35331 Server version: 8.0.21 MySQL Community Server - GPL Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> use hmsdb Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +---------------------------+ | Tables_in_hmsdb | +---------------------------+ | AUX_TABLE | | BUCKETING_COLS | | CDS | | COLUMNS_V2 | | COMPACTION_QUEUE | | WRITE_SET | +---------------------------+ 73 rows in set (0.00 sec) mysql>\
Install and configure Presto SQL[Download Presto server](http:// https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.237.1/presto-server-0.237.1.tar.gz) and configure Presto server
\
$ tar -zxf presto-server-0.237.1.tar.gz $ cd presto-server-0.237.1\ Create a configuration file etc/config.properties to include the basic Presto configuration
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
discovery-server.enabled=true
discovery.uri=http://localhost:8080
\ Create etc/jvm.config to specify the following JVM configuration.
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
\ Create etc/node.properties to include the following lines.
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/tmp/presto/data
\ Configure hive metastore, Presto Hive connector in etc/catalog/hive.properties, pointing to the Hive Metastore service that we just started
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083
hive.s3.aws-access-key=
hive.s3.aws-secret-key=
\ Start the presto server
$ ./bin/launcher start
\ To verify Presto server is running, open http://localhost:8080 in your browser and check the server status from its web UI.
Presto Client CLI $ mv presto-cli-0.237.1-executable.jar presto $ chmod +x presto\ Connect to server and query the data
$ ./presto --server localhost:8080 --catalog hive --debug presto> use default;\ create a table using presto CLI with data backed by AWS S3
\
CREATE TABLE reason5 ( r_reason_sk varchar, r_reason_id varchar, r_reason_desc varchar ) WITH ( external_location = 's3a://com.test/presto/', format = 'PARQUET' );\ Now this creates a table metadata in hive metastore which can be used to query the files in S3 which match the table schema. If we have files in S3 matching the schema, we should be able to query using presto CLI. Note the file format is PARQUET.
\ In order to do so you need to create a parquet file in S3 matching above schema. There are various tool to do so. I have used pyspark with jupyter to create a parquet file from CSV and then copy the file to S3.
Pyspark scriptInstall pyspark and use the following jupyter script to create parquet file.
\ input file
\
$ cat /tmp/reason5.csv r_reason_sk, r_reason_id, r_reason_desc "100", "this is the reason", "good way" "101", "this is the reason", "good way" "102", "this is the reason", "good way" "103", "this is the reason", "good way" "104", "this is the reason", "good way" "105", "this is the reason", "good way"\ jupyter script
\
import pyspark from pyspark import SparkContext sc = SparkContext.getOrCreate(); schema = StructType([ StructField("r_reason_sk", StringType(), True), StructField("r_reason_id", StringType(), True), StructField("r_reason_desc", StringType(), True)]) rdd = sc.textFile('/tmp/reason5.csv').map(lambda line: line.split(",")) df = sqlContext.createDataFrame(rdd, schema) df.write.parquet('/tmp/reason5.parquet')\ Copy file to s3
aws s3 sync /tmp/reason5.parquet s3://com.test/presto/\ Query using Presto CLI. Ta-da! You can query the files on S3 mapped to a SQL table.
\
presto:default> select * from reason5; r_reason_sk | r_reason_id | r_reason_desc -------------+-----------------------+---------------- "100" | "this is the reason" | "good way" "101" | "this is the reason" | "good way" "102" | "this is the reason" | "good way" "103" | "this is the reason" | "good way" "103" | "this is the reason" | "good way" "104" | "this is the reason" | "good way" "105" | "this is the reason" | "good way" "104" | "this is the reason" | "good way" "105" | "this is the reason" | "good way" "100" | "this is the reason" | "good way" "101" | "this is the reason" | "good way" "102" | "this is the reason" | "good way" (12 rows) Query 20201101_214203_00027_prps3, FINISHED, 1 node Splits: 20 total, 20 done (100.00%) 0:01 [12 rows, 1.29KB] [17 rows/s, 1.57KB/s]\ High level components used in the workflow. The query performance on presto can can tuned by giving more worker nodes and various other tuning parameters.
\
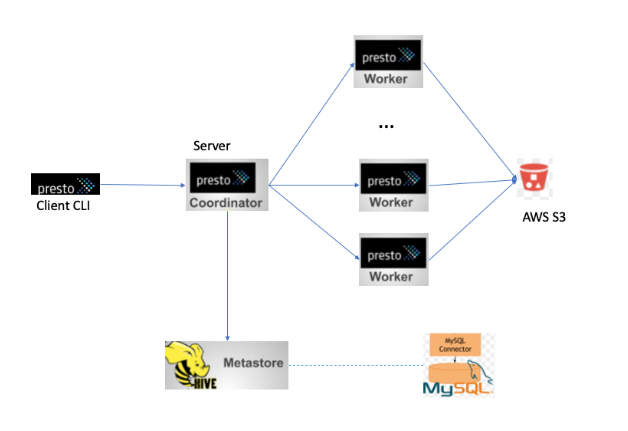
\ \ \
Apache supersetApache Superset is an open-source data exploration and visualization platform designed to help users create, share, and manage dashboards and reports. Initially developed by Airbnb, Superset has become a popular tool for business intelligence (BI) and data analytics due to its robust feature set and ease of use.
\ Integrating Apache Superset with Presto allows users to leverage the powerful SQL query engine of Presto for data exploration and visualization through Superset's intuitive interface. This combination is particularly effective for interactive analytics on large datasets across diverse data sources.
Steps to Integrate Apache Superset with Presto Install Apache SupersetYou can install Superset using Docker, pip, or from source. The official Apache Superset documentation provides detailed instructions.
\ Superset requires the pyhive library to connect to Presto. You can install it using pip:pip install pyhive
\ Configure the Presto Connection in Superset
Open your Superset instance and navigate to "Data" → "Databases".
Click on "+ Database" to add a new database.
Configure the connection settings for Presto. Here’s a sample connection string format for Presto:presto://@://For example:presto://user@presto-host:8080/hive/default
\ Test the Connection
Once you've entered the connection details, test the connection to ensure Superset can communicate with your Presto instance.
After successfully connecting to Presto, you can add and configure datasets (tables) from Presto in Superset. This involves defining the schemas, tables, and columns you want to work with.
\ Explore Data and Create Visualizations
Use Superset’s interface to explore your datasets, run SQL queries, and create visualizations. You can then combine these visualizations into interactive dashboards.
Sample ConfigurationBelow is an example of how you might configure a Presto connection in Superset:
\ Add Database
Navigate to "Data" → "Databases" → "+ Database".
\ Database Connection
Enter the URI:presto://user@presto-cluster:8080/hive/default
Replace user with your Presto username, presto-cluster with the hostname of your Presto server, and hive/default with the catalog and schema you want to use.
\ Advanced Settings (Optional):
You can configure additional options such as connection timeout and SSL settings if required.
\ Save and Test:
Save the database configuration and test the connection to ensure it is working.
Common Use CasesData Lake Analytics: Querying data directly in data lakes without the need for data movement or transformation.
Business Intelligence: Enabling business analysts to run complex queries on large datasets for reporting and data visualization.
Ad-hoc Data Analysis: Providing data scientists and engineers with a tool for running exploratory queries to gain insights from diverse data sources.
SummaryIntegrating Apache Superset with Presto provides a powerful and flexible platform for data exploration and visualization. By leveraging Presto's high-performance query engine and Superset's intuitive interface, users can perform interactive analytics on large and diverse datasets effectively. For more detailed information, you can refer to the Apache Superset documentation and the Presto documentation.
References\