and the distribution of digital products.
Performance Assessment of LALMs and Multi-Modality Models
:::info Authors:
(1) Qian Yang, Zhejiang University, Equal contribution. This work was conducted during Qian Yang’s internship at Alibaba Group;
(2) Jin Xu, Alibaba Group, Equal contribution;
(3) Wenrui Liu, Zhejiang University;
(4) Yunfei Chu, Alibaba Group;
(5) Xiaohuan Zhou, Alibaba Group;
(6) Yichong Leng, Alibaba Group;
(7) Yuanjun Lv, Alibaba Group;
(8) Zhou Zhao, Alibaba Group and Corresponding to Zhou Zhao ([email protected]);
(9) Yichong Leng, Zhejiang University
(10) Chang Zhou, Alibaba Group and Corresponding to Chang Zhou ([email protected]);
(11) Jingren Zhou, Alibaba Group.
:::
Table of Links4 Experiments
4.3 Human Evaluation and 4.4 Ablation Study of Positional Bias
A Detailed Results of Foundation Benchmark
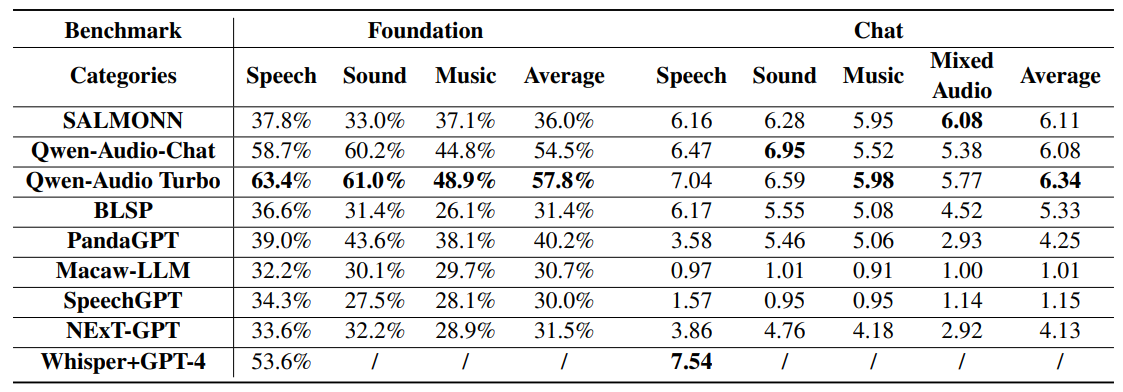
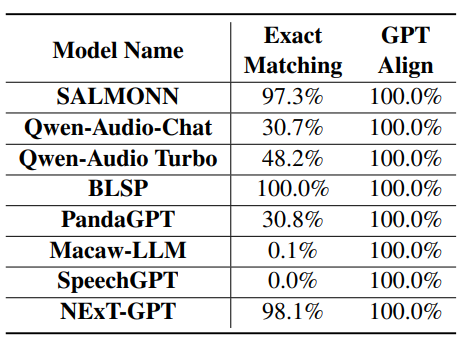
4.1 ModelsWe evaluate the performance of various LALMs with instruction-following capabilities. These models are either open-sourced or accessible through public APIs, such as SpeechGPT (Zhang et al., 2023), BLSP (Wang et al., 2023a), SALMONN (Tang et al., 2023a), Qwen-AudioChat (Chu et al., 2023), and Qwen-Audio Turbo [3]. Additionally, we consider large multi-modality models with audio understanding abilities like PandaGPT (Su et al., 2023), Macaw-LLM (Lyu et al., 2023), and NExT-GPT (Wu et al., 2023b). Besides, we also incorporate a concatenative approach comprising Whisper-large-v2 (Radford et al., 2023) and GPT-4 Turbo (OpenAI, 2023) for tasks related to speech as a baseline. We evaluate the performance of all these models on both funda
\
\
\ mental and chat benchmarks, utilizing their latest publicly available checkpoints. In cases of multiple checkpoints, we select the model with the largest parameter size. For all models, we directly follow their default decoding strategies for evaluation.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[3] https://help.aliyun.com/zh/dashscope/developerreference/qwen-audio-api