and the distribution of digital products.
Open-Vocabulary Segmentation with Unpaired Mask-Text Supervision
:::info Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
:::
Table of Links3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
\
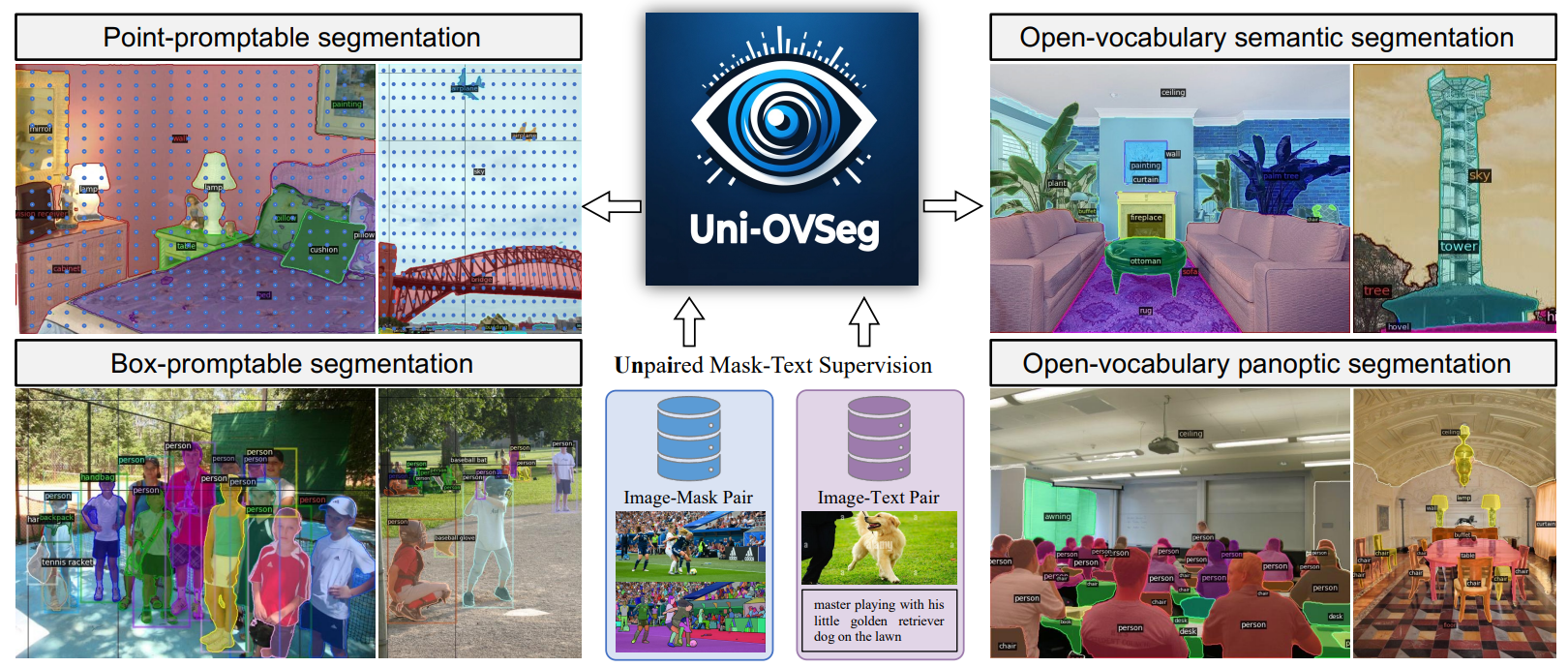
Contemporary cutting-edge open-vocabulary segmentation approaches commonly rely on image-mask-text triplets, yet this restricted annotation is labour-intensive and encounters scalability hurdles in complex real-world scenarios. Although some methods are proposed to reduce the annotation cost with only text supervision, the incompleteness of supervision severely limits the versatility and performance. In this paper, we liberate the strict correspondence between masks and texts by using independent image-mask and image-text pairs, which can be easily collected respectively. With this unpaired mask-text supervision, we propose a new weakly-supervised open-vocabulary segmentation framework (Uni-OVSeg) that leverages confident pairs of mask predictions and entities in text descriptions. Using the independent image-mask and image-text pairs, we predict a set of binary masks and associate them with entities by resorting to the CLIP embedding space. However, the inherent noise in the correspondence between masks and entities poses a significant challenge when obtaining reliable pairs. In light of this, we advocate using the large vision-language model (LVLM) to refine text descriptions and devise a multi-scale ensemble to stablise the matching between masks and entities. Compared to text-only weaklysupervised methods, our Uni-OVSeg achieves substantial improvements of 15.5% mIoU on the ADE20K datasets, and even surpasses fully-supervised methods on the challenging PASCAL Context-459 dataset.
1. IntroductionOpen-vocabulary segmentation refers to the segmentation and categorisation of objects from an expansive and unrestricted vocabulary, even though the object categories within the vocabulary are not encountered during training [16, 35, 70]. Compared to traditional closed-vocabulary segmentation [13, 83], which depends on predefined training categories and cannot recognise absent categories, open-vocabulary segmentation can segment any category with arbitrary text descriptions. This innovative segmentation paradigm has garnered considerable attention [39, 67] and opened up numerous potential applications [72, 87, 88].
\ Cutting-edge approaches in open-vocabulary segmentation typically leverage supervision with triplet annotations that are composed of images, masks, and corresponding texts [63, 76]. It is worth noting that strict alignment between each mask and text results in an expensive annotation cost. To mitigate this, some weakly-supervised methods propose using only text supervision [6, 64, 65]. However, learning with this supervision, the model falls short in capturing complex spatial details, which is suboptimal for dense prediction. Furthermore, this type of supervision lacks positional information, making the model difficult to distinguish different instances with the same semantic class. These issues severely limit the versatility and segmentation performance of existing weakly-supervised methods.
\ Motivated by that, in this paper, we propose an advanced weakly-supervised open-vocabulary segmentation framework, named Uni-OVSeg, to reduce the annotation expense while significantly enhancing performance. In essence, we liberate the strict correspondence between masks and texts, by using independent image-mask and image-text pairs. These two types of pairs can be easily collected from different sources, as illustrated in Fig. 1, such as SA-1B [34] for image-mask pairs and CC3M [50] for image-text pairs. By resorting to independent image-mask and image-text pairs, our Uni-OVSeg has a strong segmentation ability to group semantically similar pixels, and align mask-wise embeddings with entity embeddings of texts into the same space, achieving open-vocabulary segmentation.
\ Technically, when presented with an image-mask pair, we train a visual prompt encoder, a pixel decoder, and a mask decoder to generate a set of binary masks. The collected image-text pair often contains certain texts that does not match the image [52], leading to an incorrect correspondence between masks and entities. We employ the LLaVa model [42] to refine the quality of text descriptions, coupled with a ChatGPT-based parser for precise entity extraction. For mask-text alignment, we introduce a mask-text bipartite matching to exploit confident pairs of predicted masks and entities. A multi-scale feature adapter is designed to enhance the visual embeddings of predicted masks, which are further aligned with the text embeddings of corresponding entities. As masks and text are allowed to be unpaired in Uni-OVSeg, a multi-scale ensemble is introduced to improve the quality of visual embeddings and tackle inherent noise in the correspondence between masks and entities effectively, thereby stablising the matching process. During the inference phase, a zero-shot classifier, built by embedding target dataset category names, assigns categories to predicted masks, enabling the system to segment objects across an open vocabulary. We summarise our contributions in the following aspects:
\
We introduce a new framework Uni-OVSeg and offer an innovative solution that significantly reduces the need for costly triplet annotations. This makes openvocabulary segmentation more accessible and scalable.
\
Uni-OVSeg employs a visual prompt encoder, pixel decoder, and mask decoder for binary mask segmentation. An inclusion of refinement of text descriptions, multiscale ensemble enhances segmentation performance by alleviating inherent noise in mask-text correspondence.
\
With one suit of weights, we achieve 32.6% mIoU on the ADE20K dataset, and even surpassing the state-of-theart FC-CLIP [76] on the challenging PASCAL Context459 dataset. Comprehensive ablation studies and discussions are also provided.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\