and the distribution of digital products.
Navigating the LLM Landscape: A Comparative Analysis of Open-Source Models
\ “Language is the instrument of thought.” - Ralph Waldo Emerson \n
Don’t you feel this timeless quote encapsulates the essence of human communication and cognition? It definitely does! Just like a skilled musician wields an instrument to create beautiful melodies, humans, the god created meaningful creatures employ language to shape and express their thoughts. Of course, how could they not? Isn’t language the “mirror of mind”? The power of language lies in its ability to communicate complex ideas, emotions, and experiences.
\ I know, I know, you might be thinking “Why is this language saga being said in this blog which is about LLM models”? Well, that’s because LLMs are essentially digital musicians, crafting intricate linguistic compositions.
\ The world of artificial intelligence is here and Large Language Models (LLMs) have emerged as powerful tools capable of understanding, generating, and seamlessly translating human language. They have been trained on massive datasets of text, learning patterns, grammar rules, and even nuances of language. However, with the plethora of LLMs available, LLM selection from that huge sea can be a daunting task.
\ Fear not! This blog will guide you through the labyrinth of Large Language Models (LLMs). In this post, we’ll also dive deep into the world of LLMs, comparing some of the most popular open-source and non-commercial options.
\ So… Without any further ado, let’s get started.
\ But wait! Before we start, have a look at what Praful Krishna has to say to businesses about LLMs,
\

This is indeed a wake-up call message for all business planning to put to work Large Language Models for business benefits.
\ Just a simple message “DON’T BE MISGUIDED”!
\ That being said, let’s GET STARTED!
An Introduction to Large Language Models (LLM)What exactly are these LLMs? LLMs are powerful AI tools designed to generate and understand natural language. They can without rest perform a range of tasks, including text summarization, translation, and question answering making them a cornerstone of Generative AI. These models are built to understand the context and structure of language, allowing them to predict words or even sentences based on a given input. Interesting right?
Definition and Role of LLMs in Generative AIThe fact is that large language models are trained on massive datasets and have billions of parameters. Yess! Their role in Generative AI includes text generation, answering complex queries, and even coding tasks.
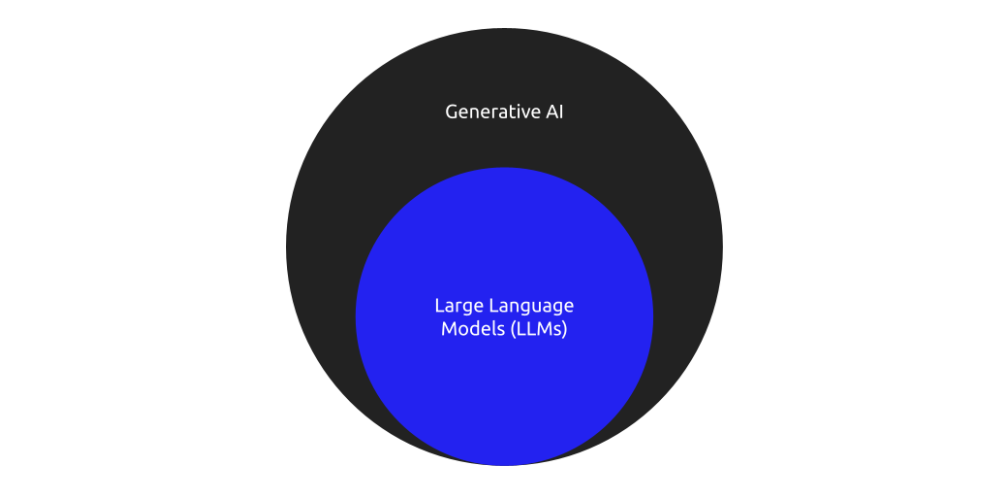
\ These models excel in creating coherent and contextually relatable content, similar to human language, thereby transforming how businesses approach automation. Ironically it’s like having a team of tireless interns that never need coffee breaks!
Importance and Capabilities of LLMsThe most impressive and lovable feature of LLMs is their flexibility. From writing long essays to generating code, LLMs effortlessly adapt to multiple use cases, providing tremendous value across industries. Whether you’re working on content creation, customer service automation, or natural language understanding, LLMs have your back - and unlike humans, they will never complain about writer’s block!
\
\
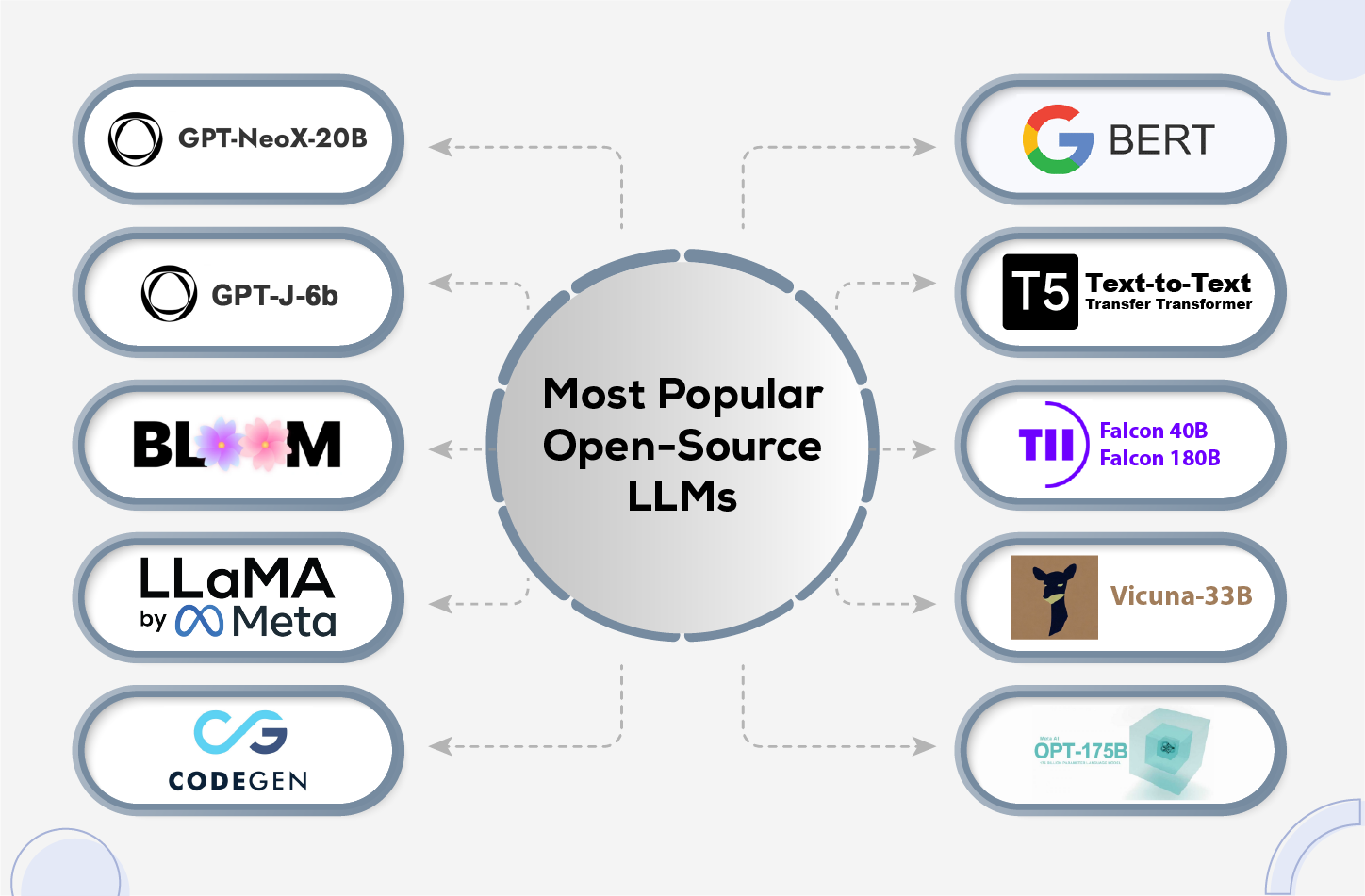
Examples Of Prominent LLMsAlthough the focus of this article to be honest is on open-source LLMs, some commercial models like GPT-3, Claude 2, and ChaGPT (of course, the famous one) have set benchmarks in the field. However, non-commercial LLMs like BERT, ROBERTa, and Llama-2 also demonstrate high performance in natural language tasks, offering flexibility and customization for specific needs.
\ Who needs fame when you’ve got skills like BERT and Llama-2-they may not be rockstars, but for sure they know how to STEAL the show!
\
\
Did You Know? The global LLM market is projected to grow from $1,590 million in 2023 to $259,8 million in 2030. During the 2023-2030 period, the CAGR will be at 79,80%.
\
Overview of Large Language Model ArchitecturesAt the heart of LLMs lies a complex neural network architecture. You might be thinking “Is it that hard?” Of course yes! While the final process is a cakewalk, there is indeed a complex neural network architecture behind the scene. The most prominent among all is the Transformer architecture, which has revolutionized how these models handle language.
\
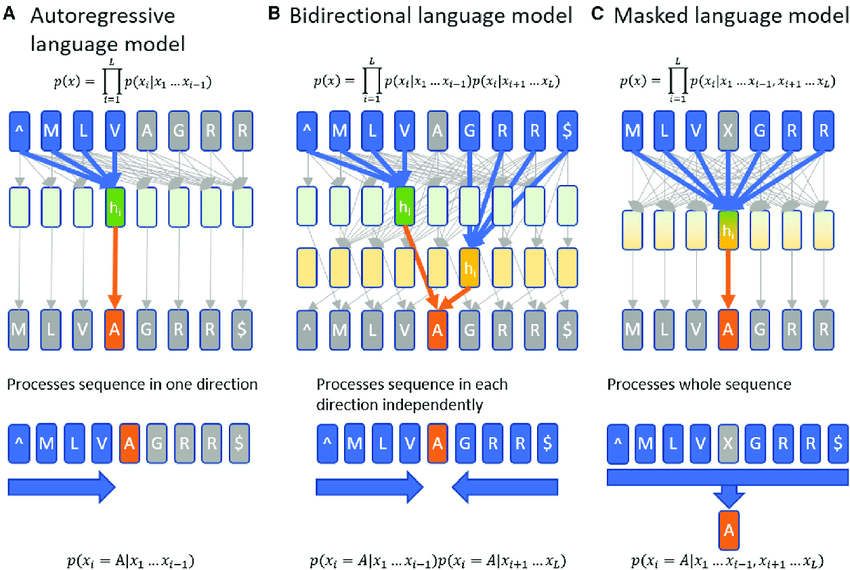
Much before transformers (not the film), models like RNNs (Recurrent Neural Networks) were popular for processing sequential data. However, RNNs really struggled with handling long-term dependencies often resulting in inaccuracies. That’s when Transformers, introduced by Vaswani et al., rolled in like Optimus Prime and changed the game by allowing parallelization of training, drastically improving performance.

\
Word Embeddings and Vector RepresentationsSo what did the transformers rely on? Transformers rely on word embeddings, where each word is represented as a dense vector. This enables the model to understand the contextual meaning of a word in a sentence. Then, by converting words into numerical vectors, transformers can analyze relationships between words leading to more precise and accurate predictions. It’s like turning words into a secret language - code that only transformers can crack!
Encoder-Decoder Structure For Generating OutputsOkaay, now that seems like a new term-“Encoder-Decoder” Structure! The encoder-decoder structure in LLMs allows these models to not only understand language but also generate responses based on input prompts. The encoder takes in the input sequence and compresses it into a representation, while the decoder uses this information to produce a coherent output. It’s like the ultimate tag team-one packs the suitcase, the other unpacks it perfectly, with no socks left behind!
\n With that being said, let’s take a brief look at the training and adaptability of LLMs
Training and Adaptability of LLMsAhhh! When it comes to the training and adaptability of LLMs, you could say they’re like overachieving students–always learning new tricks and never afraid to hit the books.
\ The Training process of LLMs involves unsupervised learning techniques and vast amounts of data. This process allows these models to generalize well to various tasks.
Unsupervised Training on Large Data SourcesThe most popular datasets like Common Crawl and Wikipedia serve as the training ground for LLMs. As a matter of fact, the unsupervised nature of this training helps models to adapt to diverse tasks and domains, even when labeled data is scarce.
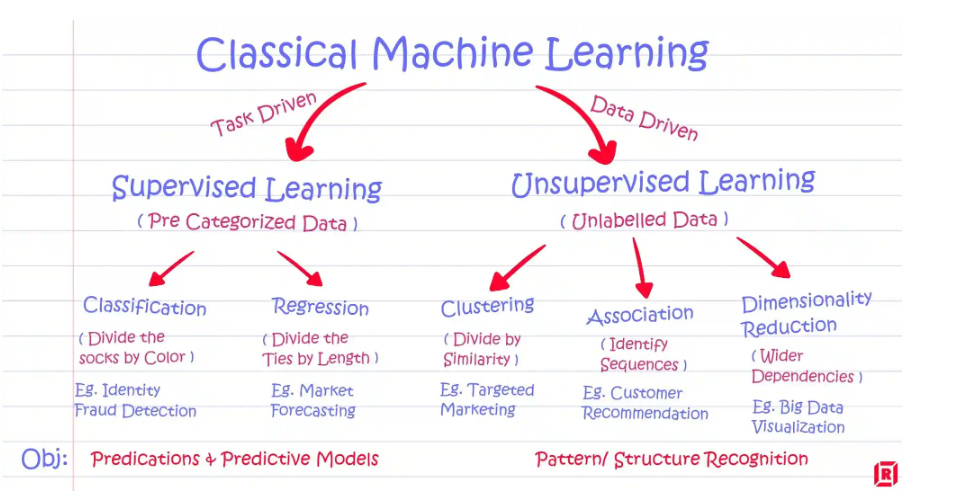
Now, fine-tuning allows these models to be optimized for specific tasks by adjusting parameters based on various task requirements. This iterative adjustment enables models like BERT and T5 to be highly effective across different NLP tasks. Think of it as giving them a personal trainer–getting them in shape for any language challenge that comes their way!
Zero-Shot, Few-Shot Learning, and Prompt EngineeringOne of the revolutionary and modern advancements in LLMs is their ability to perform zero-shot or few-shot learning –it’s like going to a party and being the life of it without even having to practice your dance moves! How awesomeee!
\ These models can respond to new tasks or even generate outputs with little to absolutely no prior training, making them incredibly versatile. Additionally, prompt engineering–designing effective prompts–has become essential in extracting desired results.
\ Okay! We spoke about a lot of things! Let’s now finally compare a few LLMs and see which one would be the perfect LLM selection.
Comparing LLMs: BERT, XLNet, T5, RoBERTa, Llama-2As a matter of fact, when it comes to open-source models, a few have made a significant impact in various applications. Let’s further break them down:
BERT: Bidirectional Encoding for Nuanced UnderstandingDid you know that BERT revolutionized NLP by introducing bidirectional training? Unlike previous models that read text in one direction, BERT reads the entire sequence, making it a cut above the rest at understanding context. Now, BERT has been widely used in sentiment analysis and language classification.
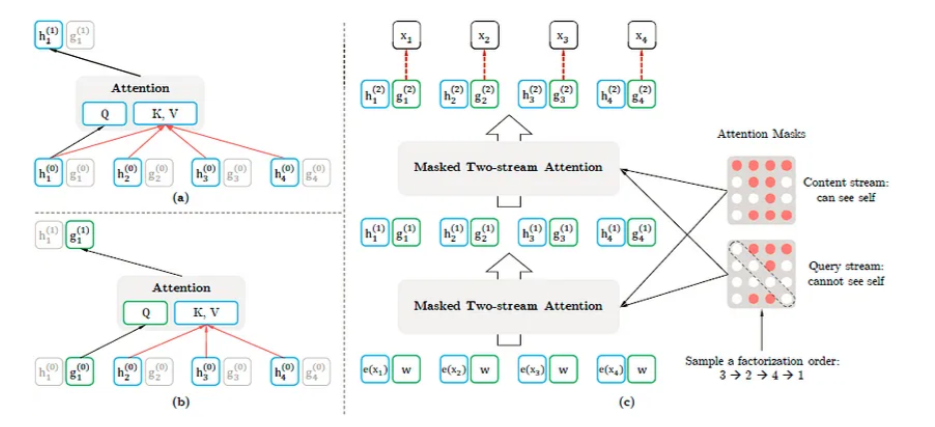
XLNet: Permutation-Based PredictionsWhen it comes to making predictions, XLNet likes to mix things up—literally! \n
XLNet uses a unique permutation-based technique to predict words, allowing it to consider all possible word arrangements. This indirectly enables it to outperform traditional models in tasks requiring nuanced understanding.
\
T5 (Text-to-Text Transfer Transformer) makes things very easy! T5 frames all NLP tasks as text generation problems, making it extremely adaptable. Whether it’s translation or summarization, T5 efficiently delivers robust performance across different language tasks.

This one is indeed a competition to BERT. RoBERTa enhances BERT by training with larger batches and much longer sequences. It has become the go-to model for tasks requiring high accuracy and better performance metrics than its predecessor. \
\ You could say RoBERTa took BERT’s homework and upgraded it with a few extra tricks!
Llama-2: Advanced Open-Source ModelHave you ever thought that an open-source LLM would be trained on 2 trillion tokens? Llama-2 trained on 2 trillion tokens offers exceptional performance across various benchmarks. With much fewer parameters than commercial models, it delivers competitive accuracy and speed, making it a great contender for research and production use.
Comparison Table: BERT vs XLNet vs T5, RoBERTa vs Llama-2| Model | Key Features | Strengths | Weaknesses | |----|----|----|----| | BERT | Bidirectional Encoder Representations from Transformers | Excellent for understanding context and relationships between words. | Can be computationally expensive to train. | | XLNet | Permutation Language Model | Improved over BERT by considering all possible permutations of word order. | More complex architecture compared to BERT. | | T5 | Text-to-Text Transfer Transformer | Highly versatile, capable of handling a wide range of tasks. | Can be large and require substantial computational resources. | | RoBERTa | Robustly Optimized BERT Pre-training Approach | Improved performance over BERT through various optimizations. | Similar to BERT in terms of computational requirements. | | Llama-2 | Large Language Model from Meta | Trained on a massive dataset of 2 trillion tokens, offering impressive performance. | Commercial use may be restricted. |
\ The truth is that choosing the right LLM is like finding the perfect recipe–it’s all about having the best and right ingredients to suit your unique taste and needs. Thus, here is the list of criteria for LLM Model Selection to help you make informed choices based on your specific needs.
Criteria for Model SelectionIn school days, we would have often found it hard to choose the right answer in multiple choice questions because the answer “A” would sound exactly like the answer “C”. Similarly choosing the right LLM depends on several factors:
\ #1 Task Relevance: As we have seen, different models excel in different tasks, such as text summarization or classification. \n
#2 Data Privacy: You would never want your data to be leaked even in your bad dreams. For sensitive information, opt for models that can be deployed on private infrastructure.
\ #3 Resource Limitation: Consider the factors like compute resources, memory, and storage when selecting a model.
\ #4 Performance Evaluation: When it comes to picking the right model, performance isn’t just a test–it’s a final exam, and you surely want an A+! Real-time performance, latency, and throughput are critical, especially for large-scale deployments.
Evaluating LLMs for Specific Use CasesWhen you want to select the most suitable LLM, always start by understanding the problem you need to solve. You can find a solution only when there is a problem. For instance, BERT might be better for sentiment analysis, while T5 is more suited for text generation.
Practical Considerations in Choosing LLMsVarious factors like
\
- Language Capabilities
- Toke Count
- Context Window Length
\ plays a significant role in the effectiveness of an LLM. Cost, of course, is another important factor, especially when dealing with commercial LLMs.
The Future of Large Language ModelsTo be honest, the future of Large Language Models is like a rocket on the launchpad–ready to soar into new heights, transforming industries and redefining possibilities with every breakthrough. \n
As AI advancements continue to flourish, the future of LLMs is posed to bring:
- Increased Accuracy and Understanding
- Domain Specific Customization
- Enhanced Multimodal Capabilities
- Ethical AI and Explainability
- Real-Time Collaboration and Automation
- Much Advanced Personalization
- AI as a Creative Partner
\ Truth to be told! As the field advances, maintaining a focus on responsible AI will be the key to realizing the full promise of these powerful tools.
End Lines: A New Dawn for AIAs we embark on this AI adventure, one thing is clear. LLMs are the “write” choice for the future. These powerful strong tools capable of understanding, generating, and translating human language, are shaking up industries across the board.