and the distribution of digital products.
Let AI Tune Your Database Management System for You
:::info Authors:
(1) Limeng Zhang, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia;
(2) M. Ali Babar, Centre for Research on Engineering Software Technologies (CREST), The University of Adelaide, Australia.
:::
Table of Links1.1 Configuration Parameter Tuning Challenges and 1.2 Contributions
3 Overview of Tuning Framework
4 Workload Characterization and 4.1 Query-level Characterization
4.2 Runtime-based Characterization
5 Feature Pruning and 5.1 Workload-level Pruning
5.2 Configuration-level Pruning
7 Configuration Recommendation and 7.1 Bayesian Optimization
10 Discussion and Conclusion, and References
7.3 Reinforcement LearningReinforcement Learning (RL) is a subfield of machine learning where an agent learns to make sequential decisions by interacting with an environment. In RL, the agent, often represented as an algorithm or program, seeks to develop a strategy or policy that enables it to maximize a cumulative reward over time. The learning process involves the agent navigating through different states, taking actions based on the policy (a mapping from perceived states of the environment to actions to be taken when in these states), receiving feedback in the form of rewards, and updating the policy. The ultimate goal is to obtain an optimal policy by learning from experiences. Currently, RL has gained more popularity in various areas, including games [57], [58], robotics [59], [60], natural language processing [61]–[63], healthcare [64], [65], finance [66], [67], business management [68], [69], transportation [70], [71], etc.
\ According to the methods used to determine the policy, RL can be classified into two three categories: (1) Valuebased RL, which aims to learn the value or benefit (commonly referred to as Q-value) of all actions and selects the action corresponding to the highest value. Among them, QLearning [72] is a classic example of a value-based algorithm where the agent learns a Q-value for each action in each state. The optimal policy is then derived from these learned Q-values. (2) Policy-based RL takes a different approach by directly learning the optimal policy. Typically, a parameterized policy is chosen, whose parameters are updated to maximize the expected return using either gradient-based or gradient-free optimization [73]. In comparison to valuebased algorithms, policy-based approaches are effective for high-dimensional or continuous action spaces and can learn stochastic policies, which are more practical than deterministic policies in value-based RL.
\ Currently, the actor-critic framework has gained popularity as an effective means of combining the benefits of policy-based approaches with value-based approaches. In this framework, the ‘actor’ (policy) estimates the target policy and take an action under a specific state, while the ‘critic’ network (value function) approximates the statevalue function to evaluate the current policy. One notable development [73] in the context of actor-critic algorithms is deterministic policy gradients (DPGs) [74], which extend the standard policy gradient theorems for stochastic policies to deterministic policies. Following the success of using deep convolutional neural networks to approximate the optimal action-value function in Deep Q-Networks (DQN) [58], the Deep Deterministic Policy Gradient (DDPG) [75] utilizes neural networks within the DPG framework to operate on high-dimensional visual state spaces.
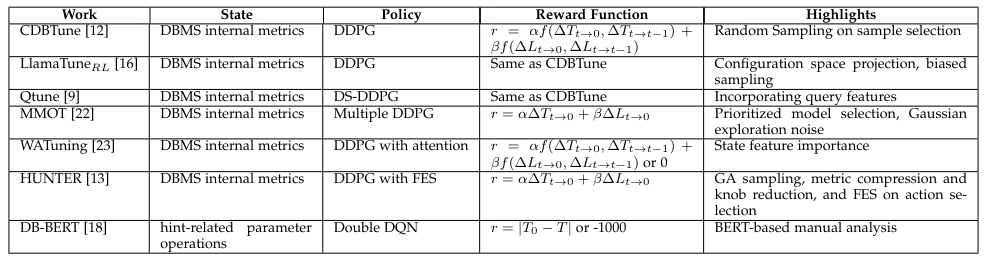
\ To address the challenge of optimizing performance in large configuration spaces with limited historical data, researchers have proposed RL-based methods. These approaches leverage RL’s capability to explore the configuration space through trial-and-error strategies without being constrained by the number of configuration parameters. The main challenge of using RL in knob tuning is to design the five modules in RL as shown in Table 4. Generally, the DBMS instance is normally considered as the environment, and the DBMS configuration is treated as the action in the environment, agent can be seen as the tuning model which receives reward, (DBMS performance, such as throughout T and latency L) and state (a set of pre-selected database monitors) from DBMSs and updates the policy to guide how to adjust the knobs for getting higher reward (higher performance). and the DBMS configuration vector represents the state resulting from each action. These configurations will be evaluated based on the tuning performance objective, serving as the reward. Table 5 provides an overview of stateof-the-art RL-based configuration tuning solutions applied in DBMS and BDAF.
\ 7.3.1 RL-based Solutions
\ CDBTune [12] handles the continuous parameter space and unseen dependencies among parameters by adopting DDPG. In CDBtune, the DBMS instance to be tuned is treated as the environment, with the DBMS internal metric vector (such as INNODB METRICS [24]) representing the state from the environment and each DBMS configuration vector as an action. Then, the tuning agent generates a configuration and receives a reward (consisting of objective performance metrics) after deploying it on the DBMS instance. CDB designs its reward function by considering both throughput and latency across different phases, including the initial tuning state, the previous action, as well as the current action. In this framework, DDPG has a parameterized policy neural network that maps the state to the action, and the critic neural network aims to represent the value (score) associated with a specific action and state, guiding the learning of the actor. Meanwhile, CDBtune can learn from past experiences through experience replay in DDPG, which stores past experiences (state, action, reward, next state) in a replay buffer and samples them randomly during the learning process.
\ LlamaTuneRL [16] introduces a framework aimed at leveraging domain knowledge to enhance the sample efficiency of existing BO-based automatic DBMS configuration solutions. Similar to its BO-based solutions, LlamaTuneRL employs HeSBO to project the configuration space into a low-dimensional subspace and conducts the same biased sampling knob selection and knob discretization strategies. It integrates the RL framework from CDBTune [12], utilizing DDPG as its policy function. The converted knob features serve as its states, while throughput/latency metrics are utilized as the reward in the RL framework.
\ Qtune [9] provides a query-level parameter tuning system with a RL-based framework to tune the database configurations. QTune first featurizes the SQL queries by considering rich features of the SQL queries, including query type (insert/delete/update/select), tables, and query cost (generated from the query optimizer in terms of scan, hash join, aggregate, etc.). Then QTune feeds the query features into the DRL model to dynamically choose suitable configurations. A Double-State Deep Deterministic Policy Gradient (DS-DDPG) model is applied to enable queryaware database configuration tuning, which utilizes the actor-critic networks to tune the database configurations based on both the query vector and database states.
\ MMOT [22] introduces a multi-model online tuning algorithm employing RL to effectively adapt to dynamic workloads, encompassing fluctuations in system resources, workload diversity, and database size. Initially, it curates a selection of trained DDPG-based RL models derived from historically similar workloads. In each training iteration, the algorithm selects the model with the highest probability of enhancing the reward from the repository and updates it with the current observations. Moreover, it maintains a fresh RL model trained exclusively on the target workload observations. To ensure optimal model selection, models from the repository are pitted against the fresh model. In the event of workload shifts, the most frequently selected model within the workload cycle is retained in the repository. Throughout the iterative process, all RL models employ DDPG as their policy function, utilizing 22 PostgreSQL metrics from three different perspectives to define the action space. Its reward function is deigned to incorporate initial throughput and latency, along with current observed performance in each iteration. Meanwhile and it adds Gaussian action space exploration noise using the Ornstein-Uhlenbeck processes.
\

\
\ Workload characterization is facilitated through the application of a 3-layer autoencoder, enabling both similarity model selection and model shift detection.
\ WATuning [23] is a workload-aware auto-tuning system specifically developed to tackle the adaptability challenges posed by changes in workload characteristics within CDBtune. It operates by using a multi-instance mechanism that dynamically employs different trained models to suggest parameter adjustments based on the workload’s write/read ratio during runtime. Each instance model is equipped with an attention-based DDPG network, which uses a deep neural network to create a weight matrix capturing the significance of each state characteristic to the current workload. This attention mechanism is integrated into the actor network, where it collaborates with the critic network to determine the most optimal parameter settings. The reward function is calculated based on performance improvements observed in throughput and latency in the initial and last time, while also considering deviations from optimal performance and server stability. Meanwhile, it also offers the flexibility to adjust weights for throughput and latency rewards according to user preferences.
\ HUNTER [13] proposed an online DBMS tuning system with a hybrid architecture, utilizing samples generated by Genetic Algorithm (GA) to select warm-start samples for the finer-grained exploration of deep reinforcement learning. Subsequently, it employs Principal Component Analysis and Random Forest for metric compression and knob selection, respectively. Deep Deterministic Policy Gradients (DDPG) are then applied to learn and recommend the optimal configuration based on dimension-reduced metrics and selected knobs. Additionally, HUNTER introduced a Fast Exploration Strategy (FES) for DDPG, involving a probabilistic action selection either on the action generated in the current step or on the action that yields the best performance. This strategy forces the model to select configurations with the best performance in the preliminary stage of tuning and encourages exploration based on relatively better configurations to reduce the update time of the learning model.
\ DB-BERT [18] introduces a RL-based solution for DBMS parameters tuning, leveraging insights extracted from textual sources such as manuals and relevant documents. In its initial data processing phase, DB-BERT employs a finetuned BERT Transformer model to identify and extract tuning hints from textual data, and prioritized these hints with a heuristic approach, favoring parameters frequently mentioned while ensuring a balanced consideration of hints for each parameter. During the subsequent learning phase, DBBERT iteratively learns to translate, adapt, prioritize, and aggregate hints to optimize DBMS performance through RF. In each iteration, DB-BERT considers a batch of tuning hints. For each hint, it translates the hint text into a simple equation, assigning a value to a parameter, and then decides whether to deviate from the recommended value (adopt) and assigns a weight to the hint (prioritize). Then, it aggregates them into a small set of configurations, mediating between inconsistent recommendations using hint weights. From the perspective of RL, the environment is defined by workload and system properties. Actions within this environment empower the agent to adapt hints, prioritize between different hints, and aggregate hints for evaluation in trial runs. The performance observed during these trial runs, measured against user-defined benchmarks, serves as a reward signal. This reward signal is then utilized by the Double Deep Q-Networks (DDQN) reinforcement learning algorithm to guide the selection of configurations in future iterations.
\ 7.3.2 Summary
\ Compared to BO-based solutions and NN-based solutions, RL-based solutions alleviate the difficulty of collecting data for models owing to their reward-feedback mechanism. They learn the tuning strategy through interactions between the database and tuning model, iteratively improving decision-making over time. This makes RL particularly suitable for optimizing performance in large configuration spaces with limited historical data, offering robust performance in complex and uncertain environments.
\ Existing RL-based DBMS parameter tuning solutions primarily elucidate the model design through four key aspects, as detailed in Table 5: the policy function for identifying optimal knob settings, the reward function for evaluating selected configurations, candidate configuration searching, and model training. To summarize, DDPG stands out as the predominant policy function, given its proficiency in managing continuous parameter spaces. Regarding reward function design, some researchers adhere to the CDBTune reward function, which assesses the performance change of both throughput and latency across various phases. Conversely, others may focus solely on performance alterations during the initial phase or concentrate on a singular performance metric. In terms of searching for candidate configurations, Hunter introduced probabilistic action selection, either on the action generated in the current step or on the action that yields the best performance. Furthermore, researchers propose various methodologies concerning model training, such as sample selection, configuration space transformation, and the integration of supplementary information like tuning experience and state importance into RL models.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED.
:::
\