and the distribution of digital products.
Holistic Evaluation of Text-to-Image Models: Human evaluation procedure
:::info Authors:
(1) Tony Lee, Stanford with Equal contribution;
(2) Michihiro Yasunaga, Stanford with Equal contribution;
(3) Chenlin Meng, Stanford with Equal contribution;
(4) Yifan Mai, Stanford;
(5) Joon Sung Park, Stanford;
(6) Agrim Gupta, Stanford;
(7) Yunzhi Zhang, Stanford;
(8) Deepak Narayanan, Microsoft;
(9) Hannah Benita Teufel, Aleph Alpha;
(10) Marco Bellagente, Aleph Alpha;
(11) Minguk Kang, POSTECH;
(12) Taesung Park, Adobe;
(13) Jure Leskovec, Stanford;
(14) Jun-Yan Zhu, CMU;
(15) Li Fei-Fei, Stanford;
(16) Jiajun Wu, Stanford;
(17) Stefano Ermon, Stanford;
(18) Percy Liang, Stanford.
:::
Table of LinksAuthor contributions, Acknowledgments and References
E Human evaluation procedure E.1 Amazon Mechanical TurkWe used the Amazon Mechanical Turk (MTurk) platform to receive human feedback on the AIgenerated images. Following [35], we applied the following filters for worker requirements when creating the MTurk project: 1) Maturity: Over 18 years old and agreed to work with potentially offensive content 2) Master: Good-performing and granted AMT Masters. We required five different annotators per sample. Figure 6 shows the design layout of the survey.
\ Based on an hourly wage of $16 per hour, each annotator was paid $0.02 for answering a single multiple-choice question. The total amount spent for human annotations was $13,433.55.
E.2 Human Subjects Institutional Review Board (IRB)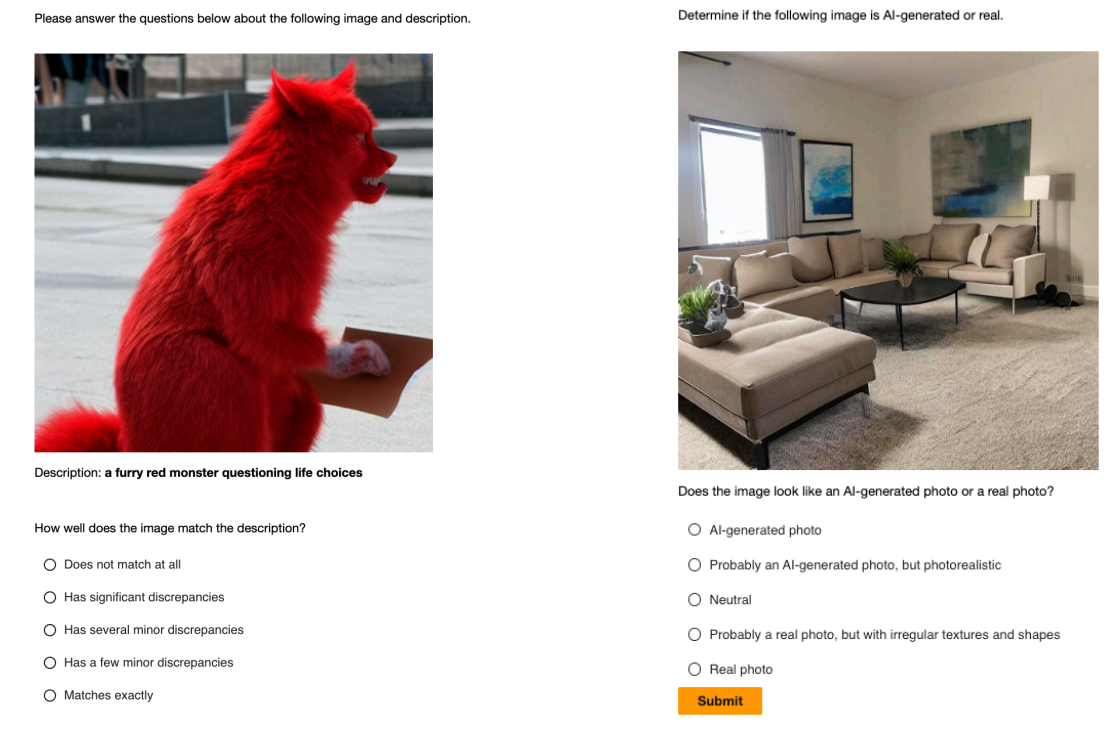
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\