and the distribution of digital products.
he Baseline and Uni-OVSeg Framework for Open-Vocabulary Segmentation
:::info Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
:::
Table of Links3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
3.2. BaselineWe introduce a straightforward baseline using the knowledge of image-text and image-mask pairs. Specifically, we employ a CLIP model as the visual and text encoder, which is trained on a large amount of image-text pairs. Afterward, we use the image-mask pairs to obtain a branch of mask generation, predicting a set of binary masks. To perform open-vocabulary segmentation, we crop and pool the CLIP image features based on these predicted masks, which are further classified by the CLIP text embeddings. Although this straightforward baseline enables open-vocabulary segmentation, it exhibits an obvious knowledge gap between the image-level and pixel-level tasks.
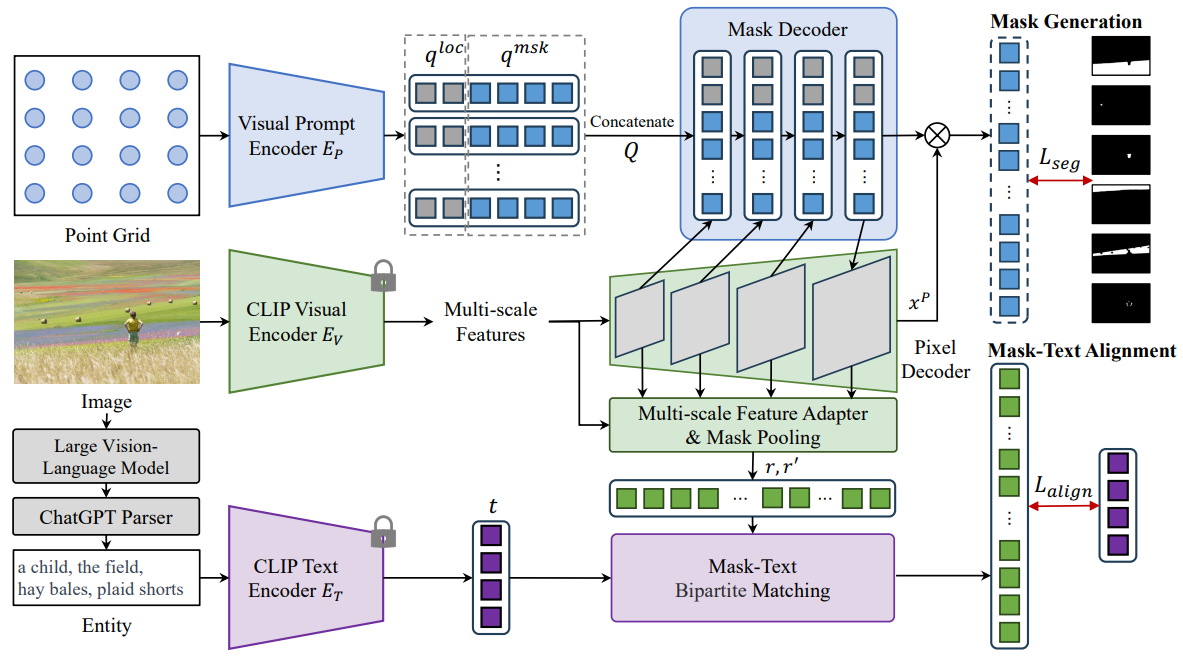
3.3. Uni-OVSeg frameworkOverview. An overview of our framework Uni-OVSeg, for weakly-supervised open-vocabulary segmentation is illustrated in Fig. 2. On a macro level, Uni-OVSeg contains a CLIP model to extract features of both images and text descriptions. With the image-mask pairs, a branch of mask generation, including a visual prompt encoder, a pixel decoder and a mask decoder, is employed to predict a set of binary masks of an input image. With the image-text pairs, mask-text bipartite matching is used to exploit confident pairs between predicted masks and entities in text descriptions. Afterward, we adopt a multi-scale feature adapter to enhance the mask-wise visual embeddings, which are further aligned with associated entity embeddings based on the confident pairs. Finally, we perform open-vocabulary segmentation with the above-mentioned parts. More details can be found in Appendix A.
\

\
\
\

\ Mask-text alignment. To enable the model categorising the predicted masks from an open set of vocabulary, given the image-text pairs, we build the correspondence between objects in the image and entities in the text description. Once a set of binary masks m are generated from the input image, we obtain the region embeddings ri by employing a mask pooling layer P and the CLIP visual projector Fv,
\

\ Open-vocabulary inference. During inference, given the test categories Ctest, we conduct prompt engineering [21] and use the CLIP text encoder to extract text embeddings 1https://openai.com/chatgpt for open-vocabulary segmentation. For each input image, we input an uniform point grid as the visual prompt to predict a set of binary masks, and compute the cosine similarity with the text embeddings to predict the category with the maximum similarity as the label of the corresponding mask.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[1] https://openai.com/chatgpt