and the distribution of digital products.
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis: Qualitative Results
:::info (1) Feng Liang, The University of Texas at Austin and Work partially done during an internship at Meta GenAI (Email: [email protected]);
(2) Bichen Wu, Meta GenAI and Corresponding author;
(3) Jialiang Wang, Meta GenAI;
(4) Licheng Yu, Meta GenAI;
(5) Kunpeng Li, Meta GenAI;
(6) Yinan Zhao, Meta GenAI;
(7) Ishan Misra, Meta GenAI;
(8) Jia-Bin Huang, Meta GenAI;
(9) Peizhao Zhang, Meta GenAI (Email: [email protected]);
(10) Peter Vajda, Meta GenAI (Email: [email protected]);
(11) Diana Marculescu, The University of Texas at Austin (Email: [email protected]).
:::
Table of Links- Abstract and Introduction
- 2. Related Work
- 3. Preliminary
- 4. FlowVid
- 4.1. Inflating image U-Net to accommodate video
- 4.2. Training with joint spatial-temporal conditions
- 4.3. Generation: edit the first frame then propagate
- 5. Experiments
- 5.1. Settings
- 5.2. Qualitative results
- 5.3. Quantitative results
- 5.4. Ablation study and 5.5. Limitations
- Conclusion, Acknowledgments and References
- A. Webpage Demo and B. Quantitative comparisons
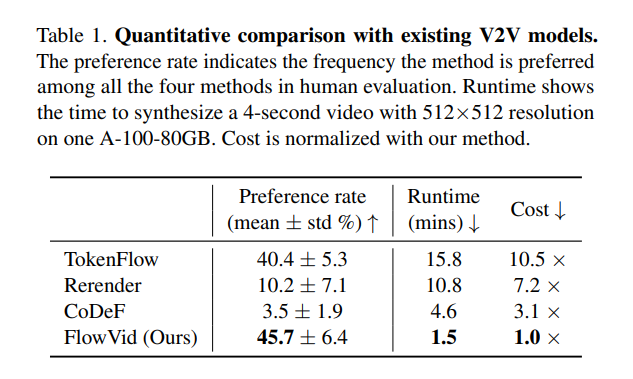
In Figure 5, we qualitatively compare our method with several representative approaches. Starting with a per-frame baseline directly applying I2I models, ControlNet, to each frame. Despite using a fixed random seed, this baseline often results in noticeable flickering, such as in the man’s clothing and the tiger’s fur. CoDeF [32] produces outputs with significant blurriness when motion is big in input video, evident in areas like the man’s hands and the tiger’s face. Rerender [49] often fails to capture large motions, such as the movement of paddles in the left example. Also, the color of the edited tiger’s legs tends to blend in with the background. TokenFlow [13] occasionally struggles to follow the prompt, such as transforming the man into a pirate in the left example. It also erroneously depicts the tiger with two legs for the first frame in the right example, leading to flickering in the output video. In contrast, our method stands out in terms of editing capabilities and overall video quality, demonstrating superior performance over these methods. We highly encourage readers to refer to more video comparisons in our supplementary videos.
\
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
\