and the distribution of digital products.
Datasets and Evaluation Methods for Open-Vocabulary Segmentation Tasks
:::info Authors:
(1) Zhaoqing Wang, The University of Sydney and AI2Robotics;
(2) Xiaobo Xia, The University of Sydney;
(3) Ziye Chen, The University of Melbourne;
(4) Xiao He, AI2Robotics;
(5) Yandong Guo, AI2Robotics;
(6) Mingming Gong, The University of Melbourne and Mohamed bin Zayed University of Artificial Intelligence;
(7) Tongliang Liu, The University of Sydney.
:::
Table of Links3. Method and 3.1. Problem definition
3.2. Baseline and 3.3. Uni-OVSeg framework
4. Experiments
6. Broader impacts and References
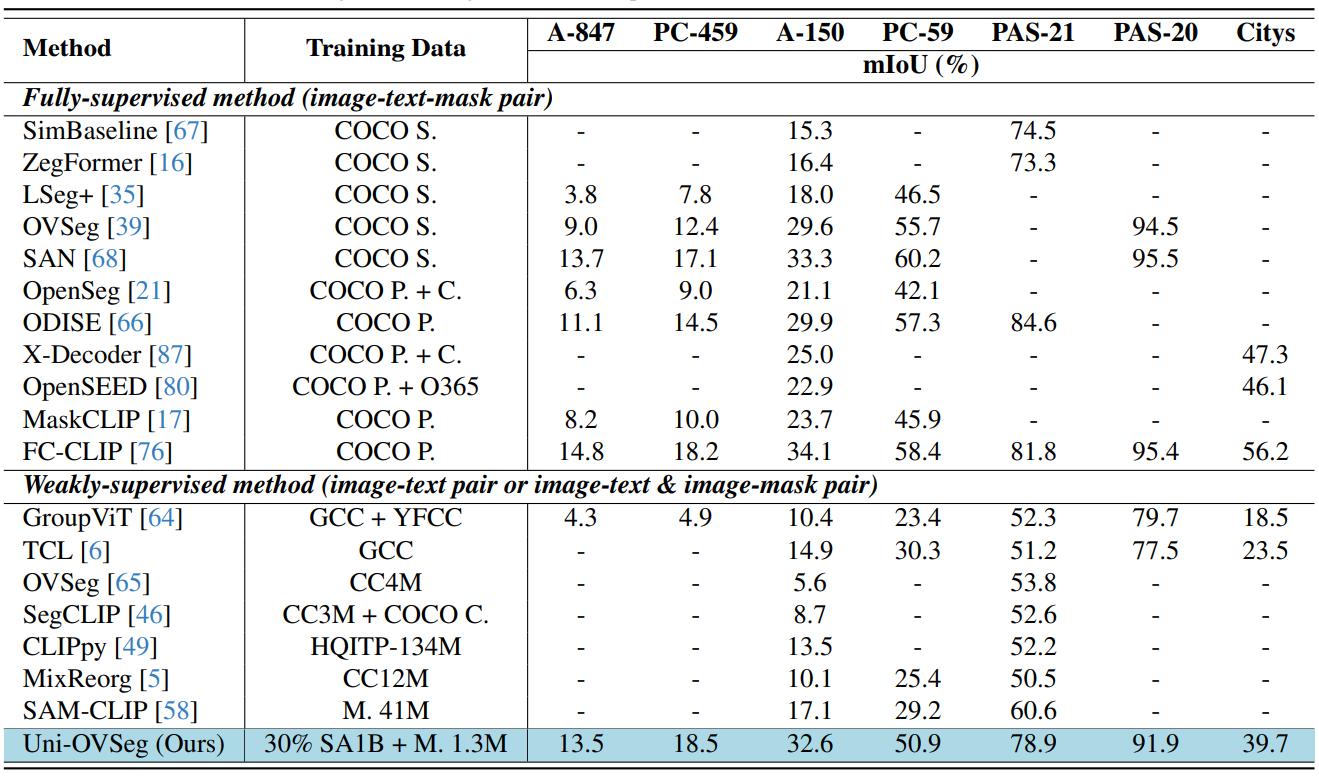
4.1. Implementation detailsDatasets. During training, we randomly sample the 30% subset from the SA-1B dataset [34], which contains ∼ 3 million images and ∼ 0.3 billion masks. Although this supervision provides diverse binary masks, it lacks the semantic class for each mask. In addition, following Chen et al. [8], we collect about 1.3 million image-text pairs and use a large vision-language model to refine them. Afterward, we use the ChatGPT-based parser to extract entities with descriptive words from these text descriptions.
\

\ Evaluation & metrics. We evaluate our model mainly on three tasks, including open-vocabulary semantic segmentation, open-vocabulary panoptic segmentation, and promptable segmentation. Following previous work [76], we adopt prompt engineering from [21, 66] and prompt templates from [22, 37]. For open-vocabulary semantic segmentation, we zero-shot evaluate the model on the COCO [40], ADE20K [84], PASCAL [18] datasets. The open-vocabulary semantic segmentation results are evaluated with the mean Intersection-over-Union (mIoU). For open-vocabulary panoptic segmentation, we evaluate the model on the COCO, ADE20K, and Cityscapes [15] datasets. We report the panoptic quality (PQ), semantic quality (SQ), and recognition quality (RQ) for open-vocabulary panoptic segmentation. For promptable segmentation, we report the 1-Point and 1-Box IoU (Oracle) on a wide range of datasets. Oracle denotes that we select the output mask with the max IoU by calculating the IoU between the prediction and target mask. More details can be found in Appendix B.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\