Your resource for web content, online publishing
and the distribution of digital products.
and the distribution of digital products.
A Data-centric Approach to Class-specific Bias in Image Data Augmentation: Appendices A-L
:::info Authors:
(1) Athanasios Angelakis, Amsterdam University Medical Center, University of Amsterdam - Data Science Center, Amsterdam Public Health Research Institute, Amsterdam, Netherlands
(2) Andrey Rass, Den Haag, Netherlands.
:::
Table of Links- Abstract and 1 Introduction
- 2 The Effect Of Data Augmentation-Induced Class-Specific Bias Is Influenced By Data, Regularization and Architecture
- 2.1 Data Augmentation Robustness Scouting
- 2.2 The Specifics Of Data Affect Augmentation-Induced Bias
- 2.3 Adding Random Horizontal Flipping Contributes To Augmentation-Induced Bias
- 2.4 Alternative Architectures Have Variable Effect On Augmentation-Induced Bias
- 3 Conclusion and Limitations, and References
- Appendices A-L
[32x32, 31x31, 30x30,
29x29, 28x28, 27x27,
26x26, 25x25, 24x24,
22x22, 21x21, 20x20,
19x19, 18x18, 17x17,
16x16, 15x15, 14x14,
13x13, 12x12, 11x11,
10x10, 9x9, 8x8,
6x6,5x5, 4x4, 3x3]
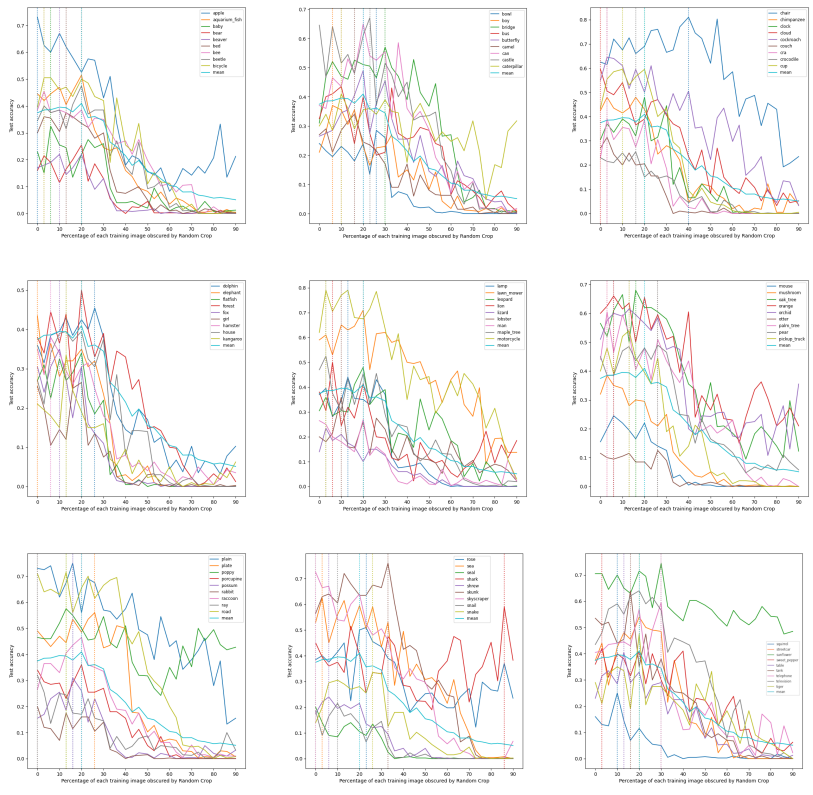
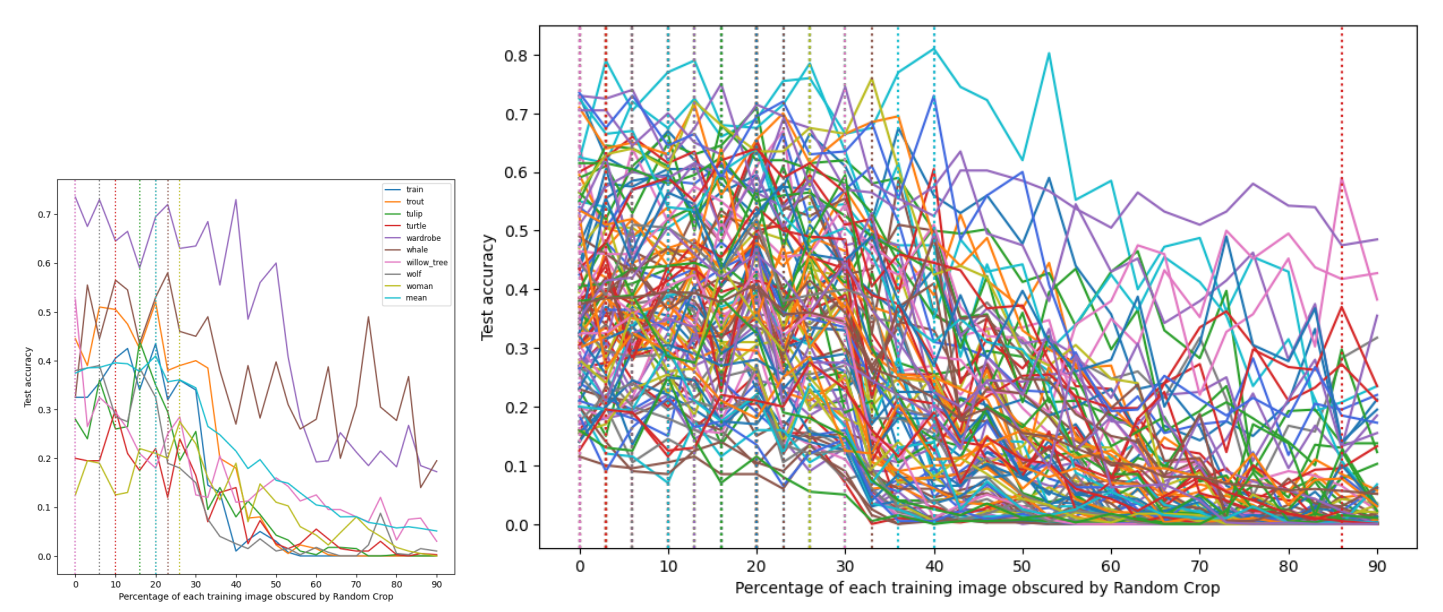
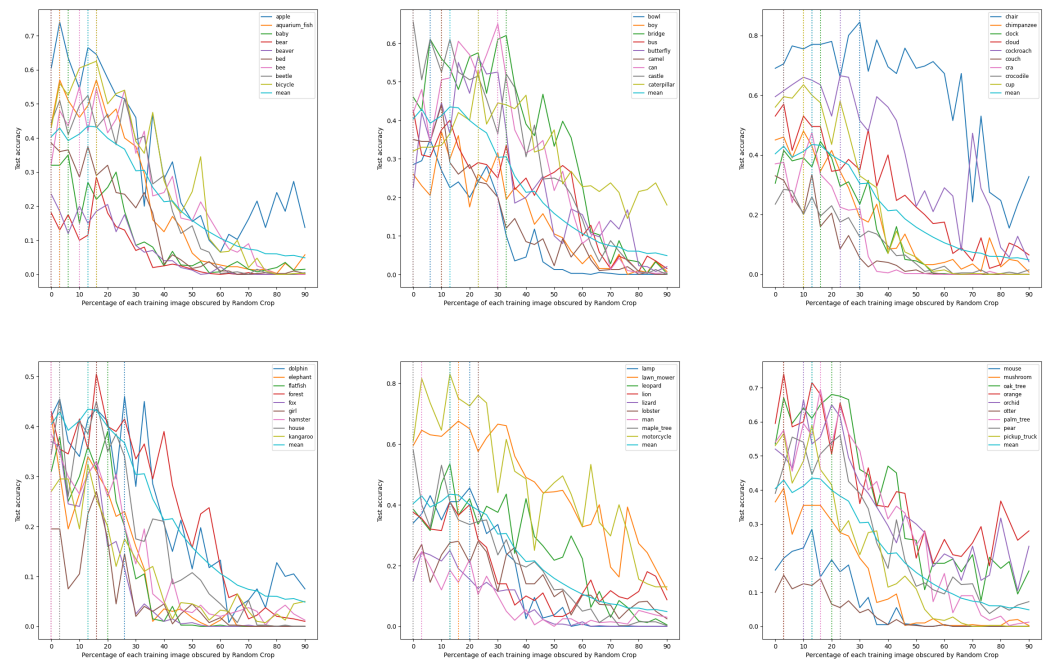
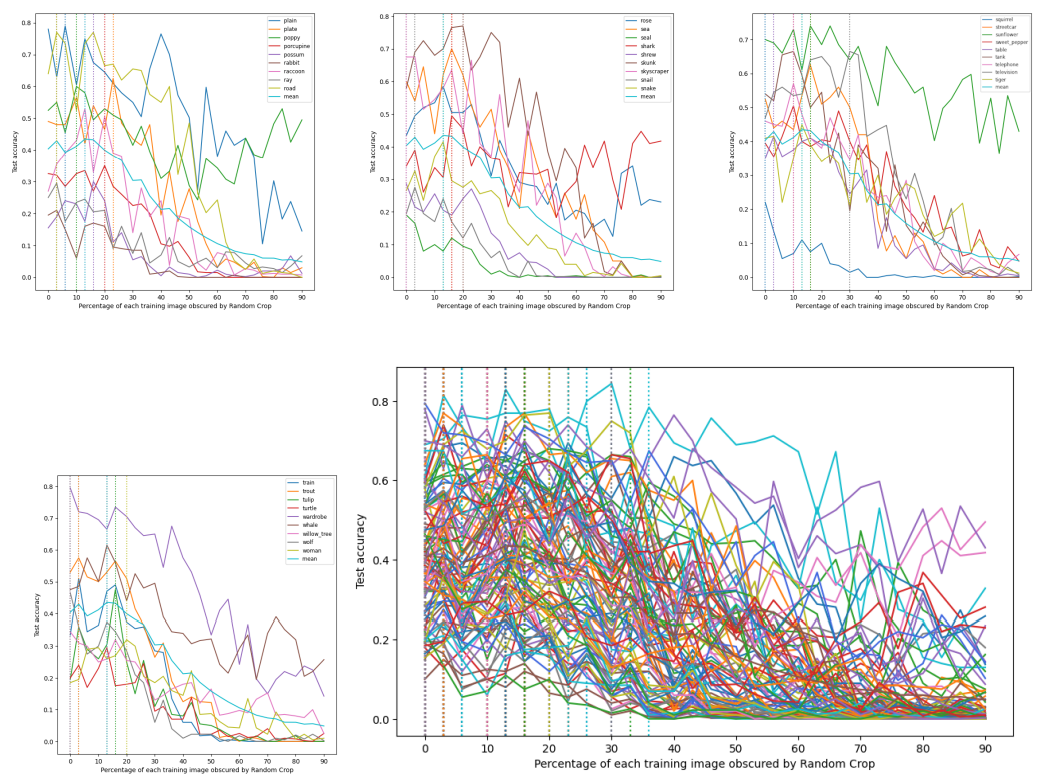
Appendix B: Dataset samples corresponding to the Fashion-MNIST segment used in training


\
\
\
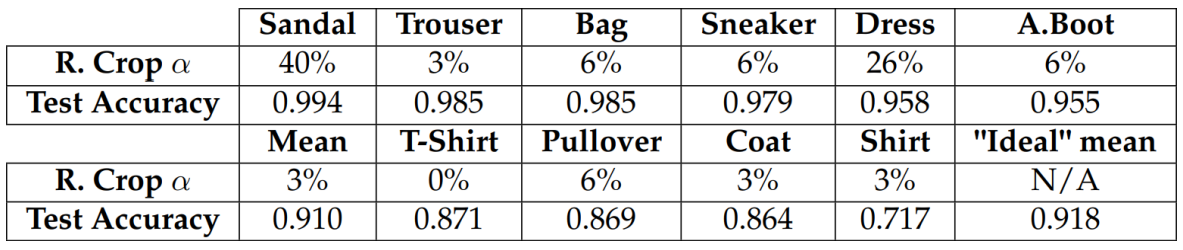
Without Random Horizontal Flip:
\
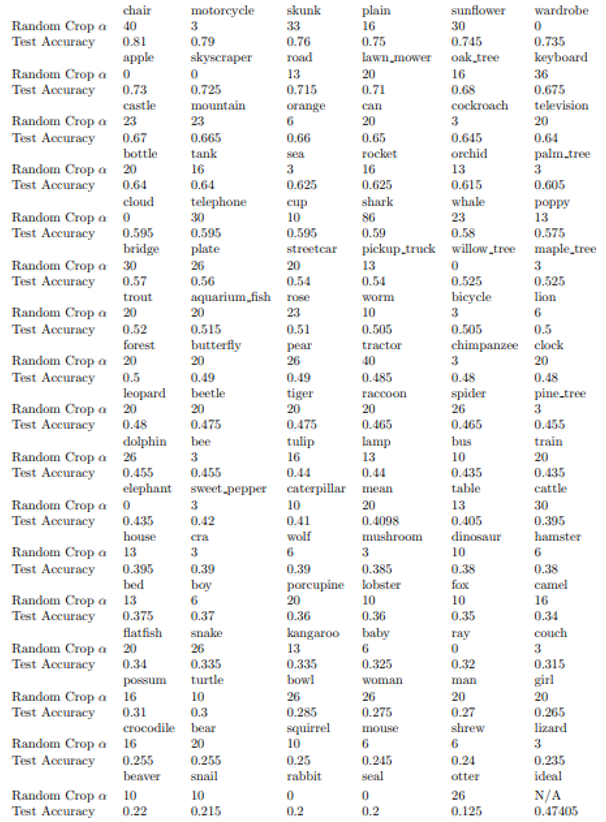
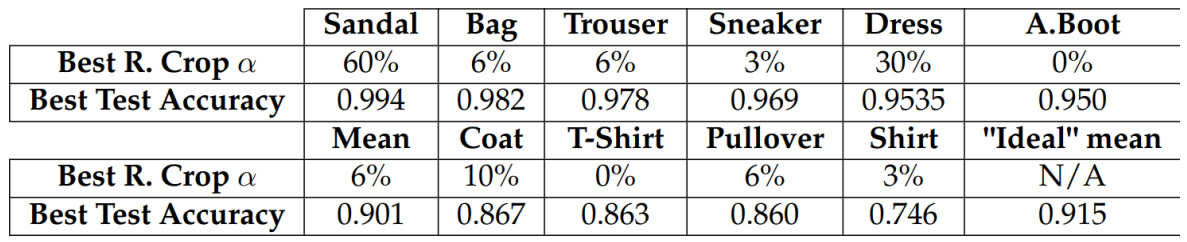
\ With Random Horizontal Flip
\
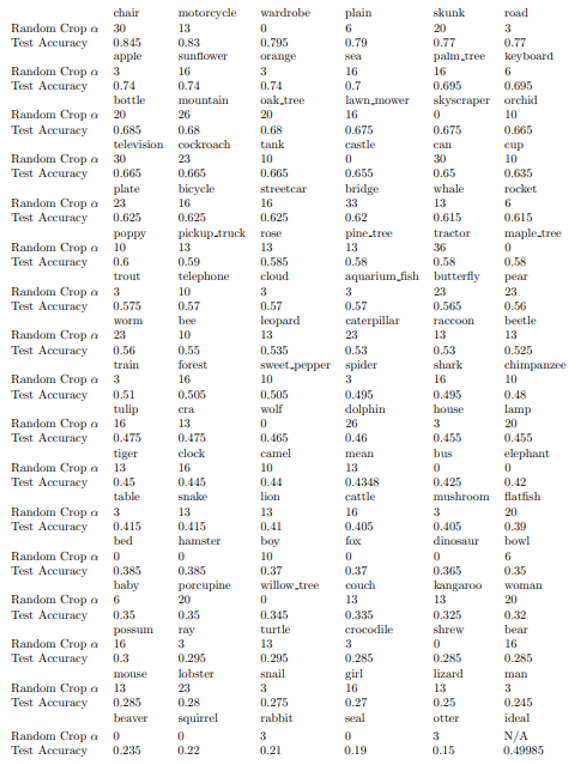
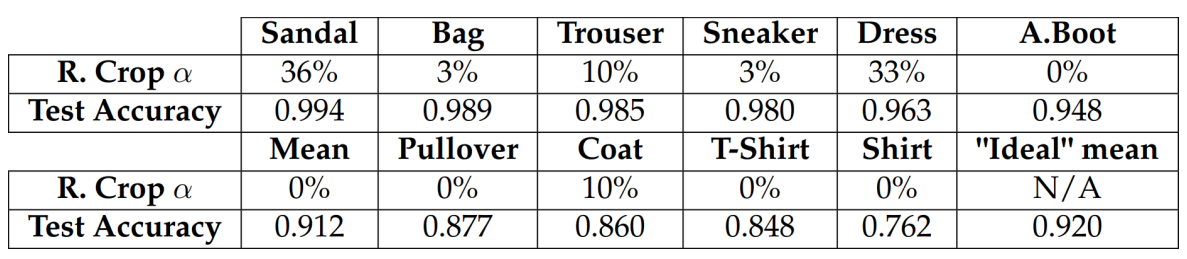
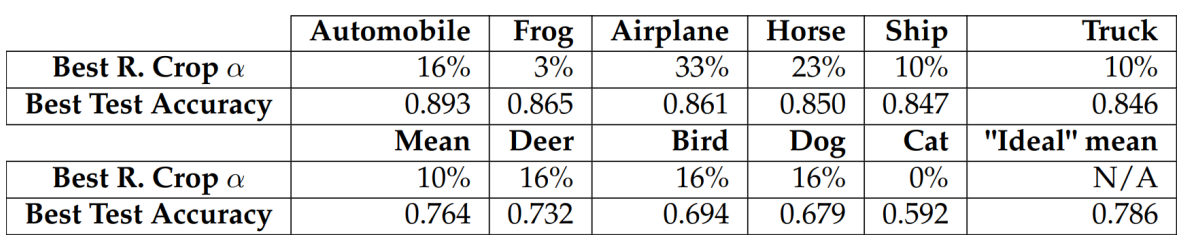


\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\