and the distribution of digital products.
Can DreamLLM Surpass the 30% Turing Test Requirement?
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
4.3 MULTIMODAL JOINT CREATION & COMPREHENSIONFree-form Interleaved Document Creation Instruction tuning endows DREAMLLM to act as a multimodal generalist that performs various kinds of tasks by following instructions. Leveraging the interleaved generative modeling from I-GPT, DREAMLLM can now generate interleaved documents in a free-form manner. In Fig. 3, we showcase the generated interleaved contents based on human
\
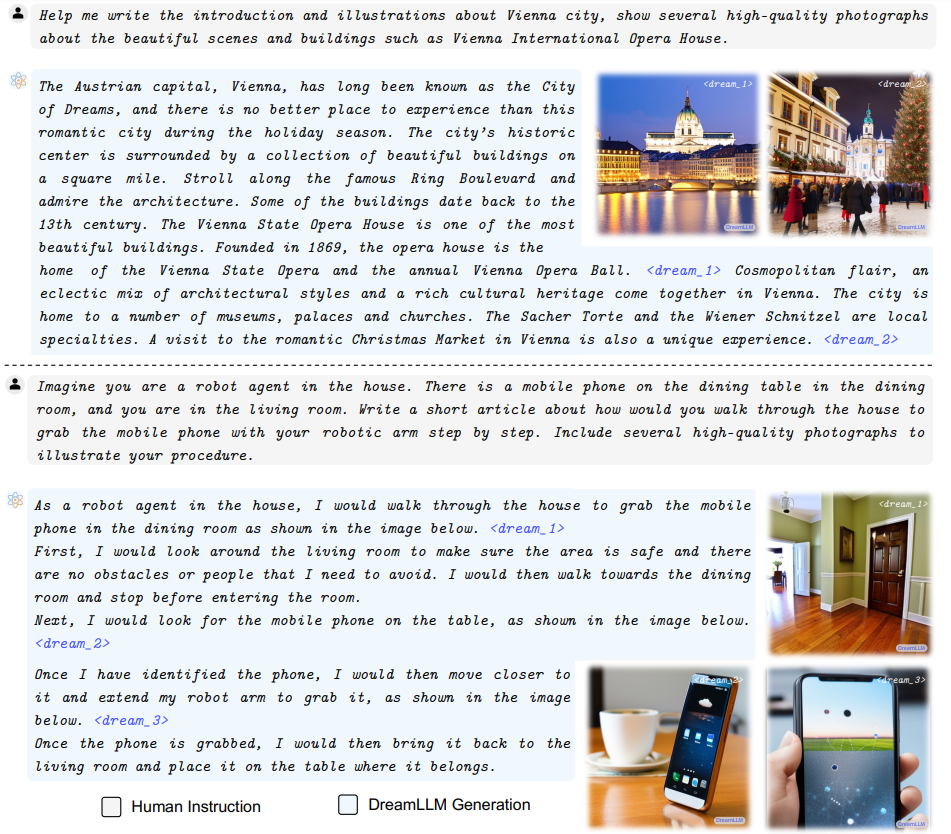
\ instructions. It demonstrates that: i) DREAMLLM can generate meaningful responses in accordance with the given instructions. ii) The system can autonomously create images at any specified location by predicting the proposed tokens, thereby eliminating the need for additional human intervention. This is a more user-friendly approach compared to systems like Emu, which necessitate human input for image generation locations. iii) The images generated by DREAMLLM accurately correspond to the associated text, a vital attribute for interleaved documents.
\ Image Quality Document quality can be influenced by factors such as text content, image quality (including image-text alignment), and illustration positioning. To assess the quality of generated documents, we utilized a held-out instruction-following subset from the constructed InstrcutMMC4 as a demonstrative tool.
\ This subset comprises 15K documents across 30 MMC4-defined topics, with 500 samples per topic. We began by evaluating image quality using FID on this subset, generating each image based on the corresponding ground truth texts. The results revealed that when using only matched text inputs for image synthesis, SD achieved an FID score of 74.77. In contrast, our DREAMLLM significantly outperforms SD with an FID score of 36.62.
\ Human Evaluation We perform a comprehensive human evaluation to assess the quality of the generated samples. We randomly selected 150 samples (5 per topic) for instruction-following document generation, mixing the generated and ground truth MMC4 documents without any identifying information. Five unbiased volunteers were then asked to determine whether the given samples were supported. Given the presence of duplicate and low-quality images in MMC4, the supportive rate for MMC4 was only 77.24%.
\ In contrast, our DREAMLLM model achieves a supportive rate of 60.68%, surpassing the 30% Turing test requirement. This result indicates that the generated documents contain high-quality images placed logically, demonstrating the effectiveness of our model.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
:::info Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.
:::
\