and the distribution of digital products.
Behind the Scenes of Self-Hosting a Language Model at Scale
Large Language Models (LLMs) are everywhere, from everyday apps to advanced tools. Using them is easy. But what if you need to run your own model? Whether you’ve fine-tuned one or are dealing with privacy-sensitive data, the complexity increases. In this post, we’ll share what we learned while building our own LLM inference system. We’ll cover storing and deploying models, designing the service architecture, and solving real-world issues like routing, streaming, and managing microservices. The process involved challenges, but ultimately, we built a reliable system and gathered lessons worth sharing.
IntroductionLLMs are powering a wide range of applications — from chatbots and workflow agents to smart automation tools. While retrieval-augmented generation, tool-calling, and multi-agent protocols are important, they operate at a level above the core engine: a foundational LLM.
Many projects rely on external providers, such as OpenAI, Gemini, or Anthropic, which is sufficient for most use cases. But for certain applications, it quickly becomes a problem. What if the provider goes down? What if you need full control over latency, pricing, or uptime? Most importantly — what if you care about privacy and can’t afford to send user data to a third party?
That’s where self-hosting becomes essential. Serving a pretrained or fine-tuned model provides control, security, and the ability to tailor the model to specific business needs. Building such a system doesn’t require a large team or extensive resources. We built it with a modest budget, a small team, and just a few nodes. This constraint influenced our architectural decision, requiring us to focus on practicality and efficiency. In the following sections, we’ll cover the challenges faced, the solutions implemented, and the lessons learned along the way.
General overviewThese are the core components that form the backbone of the system.
- Formats and Encoding. A shared language across services is essential. That means consistent request/response formats, generation parameter schemas, dialogue history structures, and serialization that works everywhere — from frontend to backend to model runners.
- Streaming and Routing. Handling multiple models, request types, and host priorities requires deliberate routing decisions. We’ll outline how incoming user requests are routed through the system — from initial entry point to the appropriate worker node — and how responses are streamed back.
- Model storage and deployment. Where do models live, and how are they prepared for production use?
- Inference. We’ll discuss the key tests to perform, including ensuring the model’s reliability.
- Observability. How do you know things are working? We’ll show what metrics we track, how we monitor for failures, and the probes we use to ensure system health and reliability.
Choosing the right schema for data transfer is crucial. A shared format across services simplifies integration, reduces errors, and improves adaptability. We aimed to design the system to work seamlessly with both self-hosted models and external providers — without exposing differences to the user.
Why Schema Design MattersThere’s no universal standard for LLM data exchange. Many providers follow schemas similar to OpenAI’s, while others — like Claude or Gemini — introduce subtle but important differences. Many of these providers offer OpenAI-compatible SDKs that retain the same schema, though often with limitations or reduced feature sets (e.g., Anthropic’s OpenAI-compatible SDK, Gemini’s OpenAI compatibility layer). Other projects such as OpenRouter aim to unify these variations by wrapping them into an OpenAI-compatible interface.
Sticking to a single predefined provider’s schema has its benefits:
- You get a well-tested, stable API.
- You can rely on existing SDK and tools.
But there are real downsides too:
- It creates vendor lock-in, making it harder to support multiple providers.
- It limits flexibility to extend the schema with custom features required for business needs or data science team requirements.
- You’re exposed to breaking changes or deprecations outside your control.
- These schemas often carry legacy constraints that restrict fine-grained control.
To address this, we chose to define our own internal data model — a schema designed around our needs, which we can then map to various external formats when necessary.
Internal Schema DesignBefore addressing the challenges, let’s define the problem and outline our expectations for the solution:
- Easy conversion to formats required by external providers and in reverse.
- Full support for features specific to our business and data science teams.
- Ensure the schema is easily extendable to accommodate future requirements.
We began by reviewing major LLM schemas to understand how providers structure messages, parameters, and outputs. This allowed us to extract core domain entities common across most systems, including:
- Messages (e.g., prompt, history)
- Generation Parameters (e.g., temperature, top_p, beam_search)
We identified certain parameters, such as service_tier, usage_metadata, or reasoning_mode, as being specific to the provider's internal configuration and business logic. These elements lie outside the core LLM domain and are not part of the shared schema. Instead, they are treated as optional extensions. Whenever a feature becomes widely adopted or necessary for broader interoperability, we evaluate integrating it into the core schema.
At a high level, our input schema is structured with these key components:
- Model — Used as a routing key, acts as a routing identifier, allowing the system to direct the request to the appropriate worker node.
- Generation Parameters — Core model settings (e.g., temperature, top_p, max_tokens).
- Messages — Conversation history and prompt payloads.
- Tools — Definitions of tools that the model may use.
This leads us to the following schema, represented in a Pydantic-like format. It illustrates the structure and intent of the design, though some implementation details are omitted for simplicity.
class ChatCompletionRequest(BaseModel): model: str # Routing key to select the appropriate model or service messages: list[Message] # Prompt and dialogue history generation_parameters: GenerationParameters # Core generation settings tools: list[Tool] # Optional tool defenitions class GenerationParameters(BaseModel): temperature: float top_p: float max_tokens: int beam_search: BeamSearchParams # Optional, non-core fields specific to certain providers provider_extensions: dict[str, Any] = {} ... # Other parametersWe deliberately moved generation parameters into a separate nested field instead of placing them at the root level. This design choice makes a distinction between constant parameters (e.g., temperature, top-p, model settings) and variable components (e.g., messages, tools). Many teams in our ecosystem store these constant parameters in external configuration systems, making this separation both practical and necessary.
We include an additional field called provider_extensions within the GenerationParameters class. These parameters vary significantly across different LLM providers, validation and interpretation of these fields is delegated to the final module that handles model inference—the component that knows how to communicate with a specific model provider. Thus, we avoid unnecessary pass-through coupling caused by redundant data validation across multiple services.
To ensure backward compatibility, new output schema features are introduced as explicit, optional fields in the request schema. These fields act as feature flags — users must set them to opt into specific behaviors. This approach keeps the core schema stable while enabling incremental evolution. For example, reasoning traces will only be included in the output if the corresponding field is set in the request.
These schemas are maintained in a shared Python library and used across services to ensure consistent request and response handling.
Working with Third-Party providersWe began by outlining how we built our own platform — so why bother with compatibility across external providers? Despite relying on our internal infrastructure, there are still several scenarios where external models play a role:
- Synthetic data generation for prototyping and experimentation by our data science teams.
- General-purpose tasks where some proprietary models perform better out of the box.
- Non-sensitive use cases where privacy, latency, or infrastructure control are less critical.
The overall communication flow with external providers can be summarized as follows:
\n 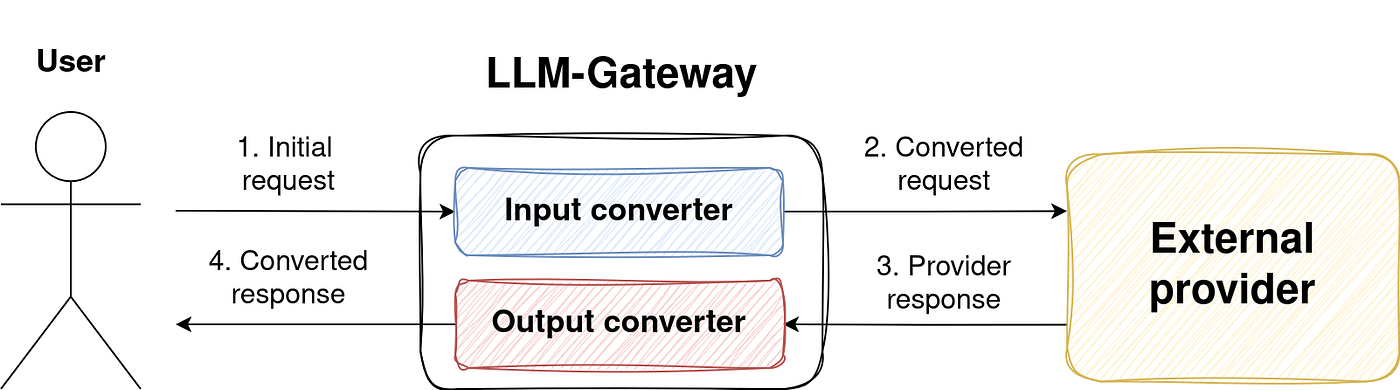
This process involves the following steps:
- Special LLM-Gateway Service responsible for communication with provider receives user request in our schema-format.
- The request is converted into the provider-specific format, including any provide_extensions.
- The external provider processes the request and returns a response.
- The LLM-Gateway Service receives the response and maps it back into our standardized response schema.
This is a high-level schematic that abstracts away some individual microservices. Details about specific components and the streaming response format will be covered in the following sections.
Streaming formatLLM responses are generated incrementally — token by token — and then aggregated into chunks for efficient transmission. From the user’s perspective, whether through a browser, mobile app, or terminal, the experience must remain fluid and responsive. This requires a transport mechanism that supports low-latency, real-time streaming.
There are two primary options for achieving this:
- WebSockets: A full-duplex communication channel that allows continuous two-way interaction between client and server.
- Server-Sent Events (SSE): A unidirectional, HTTP-based streaming protocol that is widely used for real-time updates.
While both options are viable, SSE is the more commonly used solution for standard LLM inference — particularly for OpenAI-compatible APIs and similar systems. This is due to several practical advantages:
- Simplicity: SSE runs over standard HTTP, requiring no special upgrades or negotiation.
- Compatibility: It works natively in all major browsers without additional libraries.
- Unidirectional Flow: Most LLM responses flow only from server to client, which aligns with SSE’s design.
- Proxy-Friendliness: SSE plays well with standard HTTP infrastructure, including reverse proxies.
Because of these benefits, SSE is typically chosen for text-only, prompt-response streaming use cases.
However, some emerging use cases require richer, low-latency, bidirectional communication — such as real-time transcription or speech-to-speech interactions. OpenAI’s Realtime API addresses these needs using WebSockets (for server-to-server). These protocols are better suited for continuous multimodal input and output.
Since our system focuses exclusively on text-based interactions, we stick with SSE for its simplicity, compatibility, and alignment with our streaming model.
Response Stream ContentWith SSE selected as the transport layer, the next step was defining whatdata to include in the stream. Effective streaming requires more than just raw text — it needs to provide sufficient structure, metadata, and context to support downstream consumers such as user interfaces and automation tools. The stream must include the following information:
- Header-Level Metadata. Basic identifying information such as request ID.
- Actual Content Chunks. The core output — the tokens or strings generated by the model — is delivered incrementally as sequences (n) are streamed back, chunk-by-chunk. Each generation can consist of multiple sequences (e.g., n=2, n=4) .These sequences are generated independently and streamed in parallel, each broken into its own set of incremental chunks.
- Usage and Token-Level Metadata. This includes number of tokens generated, timing data, and optional diagnostics like logprobs or reasoning traces. These may be used for billing, debugging, or model evaluation.
After defining the structure of the streamed response, we also considered several non-functional requirements essential for reliability and future evolution.
Our stream design is intended to be:
- Structured — clearly distinguishing between content types and event boundaries.
- Extensible — capable of carrying optional metadata without breaking existing clients.
- Robust — resilient to malformed, delayed, or partial data.
In many applications — such as side-by-side comparison or diverse sampling — multiple sequences (completions) are generated in parallel as part of a single generation request.
The most comprehensive format for streaming responses is defined in the OpenAI API reference. According to the specification, a single generation chunk may include multiple sequences in the choices array:
choices
array
A list of chat completion choices. Can contain more than one element if n is greater than 1. Can also be empty for the last chunk.
Although, in practice, individual chunks usually contain only a single delta, the format allows for multiple sequence updates per chunk. It’s important to account for this, as future updates might make broader use of this capability. Notably, even the official Python SDK is designed to support this structure.
We chose to follow the same structure to ensure compatibility with a wide range of potential features. The diagram below illustrates an example from our implementation, where a single generation consists of three sequences, streamed in six chunks over time:
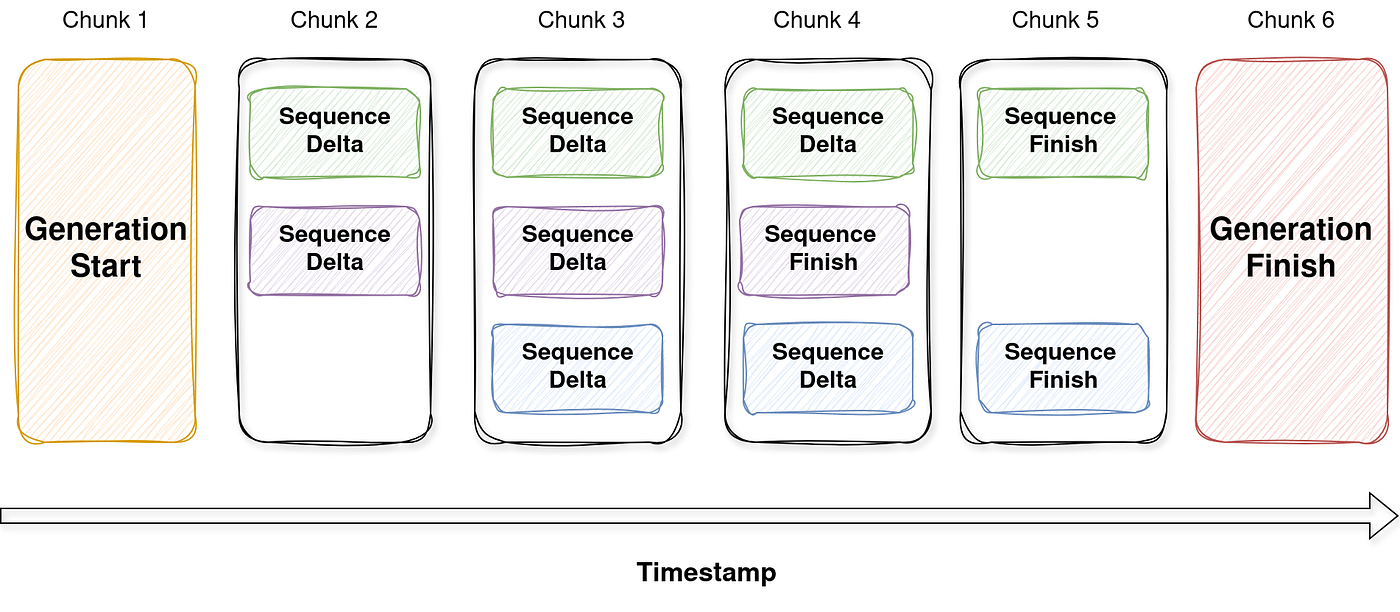
- Chunk 1 — Generation Start. This chunk marks the beginning of the entire generation. It doesn’t contain any actual content but includes shared metadata, such as the generation ID, timestamp, and role (e.g., assistant, etc.).
- Chunk 2 — Sequence Start (Green & Purple). Two sequences begin streaming in parallel. Each is tagged with a unique identifier to distinguish it from others.
- Chunk 3 — Sequence Start (Blue) & Sequence Delta. The third sequence starts (blue), while the first two sequences (green and purple) stream incremental content via delta events.
- Chunk 4 — Midstream Updates & Finish (Purple). The green and blue sequences continue streaming deltas. The purple sequence finishes — this includes a structured finish_reason (like stop, length, etc.).
- Chunk 5 — Remaining Sequence Finishes. Both the green and blue sequences complete. Each sequence’s lifecycle is now fully enclosed between its respective start and finish markers.
- Chunk 6 — Generation Finish. This chunk closes the generation and may include global usage statistics, final token counts, latency info, or other diagnostics.
As you see, to make the stream robust and easier to parse, we opted to explicitly signal Start and Finish events for both the overall generation and each individual sequence, rather than relying on implicit mechanisms such as null checks, EOFs, or magic tokens. This structured approach simplifies downstream parsing, especially in environments where multiple completions are streamed in parallel, and also improves debuggability and fault isolation during development and runtime inspection.
Moreover, we introduce an additional Error chunk that carries structured information about failures. Some errors — such as malformed requests or authorization issues — can be surfaced directly via standard HTTP response codes. However, if an error occurs during the generation process, we have two options: either abruptly terminate the HTTP stream or emit a well-formed SSE error event. We chose the latter. Abruptly closing the connection makes it hard for clients to distinguish between network issues and actual model/service failures. By using a dedicated error chunk, we enable more reliable detection and propagation of issues during streaming.
Backend Services and Request FlowAt the center of the system is a single entrypoint: LLM-Gateway. It handles basic concerns like authentication, usage tracking and quota enforcement, request formatting, and routing based on the specified model. While it may look like the Gateway carries a lot of responsibility, each task is intentionally simple and modular. For external providers, it adapts requests to their APIs and maps responses back into a unified format. For self-hosted models, requests are routed directly to internal systems using our own unified schema. This design allows seamless support for both external and internal models through a consistent interface.
Self-Hosted ModelsAs mentioned earlier, Server-Sent Events (SSE) is well-suited for streaming responses to end users, but it’s not a practical choice for internal backend communication. When a request arrives, it must be routed to a suitable worker node for model inference, and the result streamed back. While some systems handle this using chained HTTP proxies and header-based routing, in our experience, this approach becomes difficult to manage and evolve as the logic grows in complexity.
Our internal infrastructure needs to support:
- Priority-aware scheduling — Requests may have different urgency levels (e.g., interactive vs. batch), and high-priority tasks must be handled first.
- Hardware-aware routing — Certain nodes run on higher-performance GPUs and should be preferred; others serve as overflow capacity.
- Model-specific dispatching — Each worker is configured to support only a subset of models, based on hardware compatibility and resource constraints.
To address these requirements, we use a message broker to decouple task routing from result delivery. This design provides better flexibility and resilience under varying load and routing conditions. We use RabbitMQ for this purpose, though other brokers could also be viable depending on your latency, throughput, and operational preferences. RabbitMQ was a natural fit given its maturity and alignment with our existing tooling.
Now let’s take a closer look at how this system is implemented in practice:
We use dedicated queues per model, allowing us to route requests based on model compatibility and node capabilities. The process is as follows:
- Client Sends Request. The LLM-Gateway service (represented as the user) initiates an HTTP request to trigger a text generation task. Scheduler service starts a new Request Handler to manage this request.
- Task Routing via Scheduler service. The request is handled by the Scheduler, which selects the appropriate queue (marked in green on the image) based on the requested model and appends the message to it.
- Worker Picks Up Task. An appropriate Inference Worker (only one worker is shown for simplicity, but there are many) subscribed to the queue picks up the task and begins processing. This worker runs the selected model locally.
- Streaming the Response. The worker streams the response chunk-by-chunk into the Response Queue, to which the Scheduler replica handling the request is subscribed.
- Receiving Response Chunks. The Scheduler listens to the reply queue and receives the response chunks as they arrive.
- SSE Streaming. The chunks are converted to SSE format and streamed to the client.
To handle large payloads, we avoid overwhelming the message broker:
- Instead of embedding large input or output data directly in the task, we upload it to an external S3-compatible store.
- A reference (such as a URL or resource ID) is included in the task metadata, and the worker retrieves the actual content when needed.
When it comes to routing and publishing messages, each Request Queue is a regular RabbitMQ queue, dedicated to handling a single model type. We require priority-aware scheduling, which can be achieved using message priorities. In this setup, messages with higher priority values are delivered and processed before lower priority ones. For hardware-aware routing, where messages should be directed to the most performant available nodes first, consumer priorities can help. Consumers with higher priority receive messages as long as they are active; lower-priority consumers only receive messages when the higher-priority ones are blocked or unavailable.
If message loss is unacceptable, the following must be in place:
- Publisher confirms to ensure the broker has received and stored the message.
- Durable queues and persistent messages so data survives restarts.
- Quorum queues for stronger durability through replication. These also support simplified message and consumer priorities as of RabbitMQ 4.0.
So far, we’ve covered how tasks are published — but how is the streamed response handled? The first step is to understand how temporary queueswork in RabbitMQ. The broker supports a concept called exclusive queues, which are bound to a single connection and automatically deleted when that connection closes. This makes them a natural fit for our setup.
We create one exclusive queue per Scheduler service replica, ensuring it’s automatically cleaned up when the replica shuts down. However, this introduces a challenge: while each service replica has a single RabbitMQ queue, it must handle many requests in parallel.
To address this, we treat the RabbitMQ queue as a transport layer, routing responses to the correct Scheduler replica. Each user request is assigned a unique identifier, which is included in every response chunk. Inside the Scheduler, we maintain an additional in-memory routing layer with short-lived in-memory queues — one per active request. Incoming chunks are matched to these queues based on the identifier and forwarded accordingly. These in-memory queues are discarded once the request completes, while the RabbitMQ queue persists for the lifetime of the service replica.
Schematically this looks as follows:
A central dispatcher within the Scheduler dispatches chunks to the appropriate in-memory queue, each managed by a dedicated handler. Handlers then stream the chunks to users using SSE-protocol.
InferenceThere are several mature frameworks available for efficient LLM inference, such as vLLM and SGLANG. These systems are designed to process multiple sequences in parallel and generate response tokens in real time, often with features like continuous batching and GPU memory optimization. In our setup, we use vLLM as the core inference engine, with a few custom modifications:
- Custom beam search implementation — to better suit our generation logic and support structured constraints.
- Support for structured output schemas — allowing models to return outputs conforming to business-specific formats.
Through experience, we’ve learned that even minor library updates can significantly alter model behavior — whether in output quality, determinism, or concurrency behavior. Because of this, we’ve established a robust testing pipeline:
- Stress testing to uncover concurrency issues, memory leaks, or stability regressions.
- Determinism testing to ensure consistent outputs for fixed seeds and parameter sets.
- Parameter grid testing to cover a wide range of generation settings, without going overboard.
Most modern systems run in containerized environments — either in the cloud or within Kubernetes (K8s). While this setup works well for typical backend services, it introduces challenges around model weight storage. LLM models can be tens or even hundreds of gigabytes in size, and baking model weights directly into Docker images — quickly becomes problematic:
- Slow builds — Even with multi-stage builds and caching, transferring large model files during the build phase can dramatically increase CI time.
- Slow deployments — Each rollout requires pulling massive images, which can take several minutes and cause downtime or delays.
- Resource inefficiency — Neither Docker registries nor Kubernetes nodes are optimized for handling extremely large images, resulting in bloated storage usage and bandwidth strain.
To solve this, we separate model storage from the Docker image lifecycle. Our models are stored in an external S3-compatible object storage, and fetched just before inference service startup. To improve startup time and avoid redundant downloads, we also use local persistent volumes (PVCs) to cache model weights on each node.
ObservabilityA system like this — built on streaming, message queues, and real-time token generation — requires robust observability to ensure reliability and performance at scale.
In addition to standard service-level metrics (CPU, memory, error rates, etc.), we found it essential to monitor the following:
- Queue depth, message backlog, and consumer count — monitoring the number of pending messages, current queue size, and number of active consumers helps detect task distribution bottlenecks and imbalances in worker utilization.
- Token/chunk throughput — tracking the number of tokens or response chunks generated per second helps identify latency or throughput regressions.
- Distributed tracing — to pinpoint where requests fail or stall across components (gateway, broker, workers, etc.).
- Inference engine health checks — since inference processes can crash under rare conditions (e.g., bad input or extreme parameter values), proactive monitoring of liveness and readiness is critical.
While our system is production-ready, there are still important challenges and opportunities for optimization:
- Using a distributed KV-cache to boost inference performance.
- Supporting request cancellation to conserve compute when outputs are no longer needed.
- Creating a simple model delivery pipeline for data science teams.
While building a reliable and provider-independent LLM serving system can seem complex at first, it doesn’t require reinventing the wheel. Each component — streaming via SSE, task distribution through message brokers, and inference handled by runtimes like vLLM — serves a clear purpose and is grounded in existing, well-supported tools. With the right structure in place, it’s possible to create a maintainable and adaptable setup that meets production requirements without unnecessary complexity.
In the next post, we’ll explore more advanced topics such as distributed KV-caching, handling multiple models across replicas, and deployment workflows suited to ML-oriented teams.
AuthorsStanislav Shimovolos, Tochka
Maxim Afanasyev, Tochka
AcknowledgmentsDmitry Kryukov, work done at Tochka
\