and the distribution of digital products.
Why Your Browser Knows What You Want Before You Do: A Deep Dive Into Caching
Caching is a technique in software development to temporarily store application resources, data at a nearby accessible location for efficient retrieval when required. Generally, the resources or data that are frequently used but doesn’t change often are considered good candidates for caching in software design. Caching is implemented to achieve several benefits in software system such as
\
- Reduce latency in response of a request
- Reduce number of network calls thereby using less network bandwidth
- Reduce chances of failure in software system by serving data from cache instead of making call to actual backend system
\ There are several articles in the web that talks about caching and it’s various implementation strategy. This article doesn’t reiterate those in some other fashion. Instead, this article presents a holistic picture of different type of caching we implement in a large software system, conceptually how do we accomplish that for each types and how is it typically done in a system that is hosted on-premise in dedicated hardware vs how is it done in modern cloud platforms.
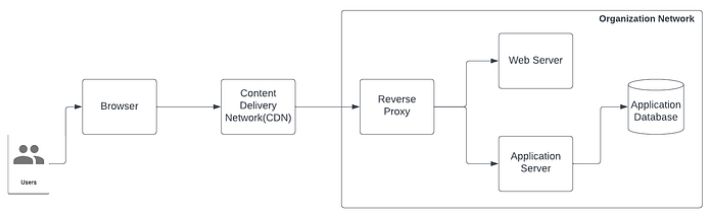
General Caching StrategyThe below diagram(Diagram 1) represents a typical web application architecture hosted in on-premise data center of an organization. Diagram 2 represents the specific type of caching that each of the architecture components contributes in caching implementation.
\
\
\
\
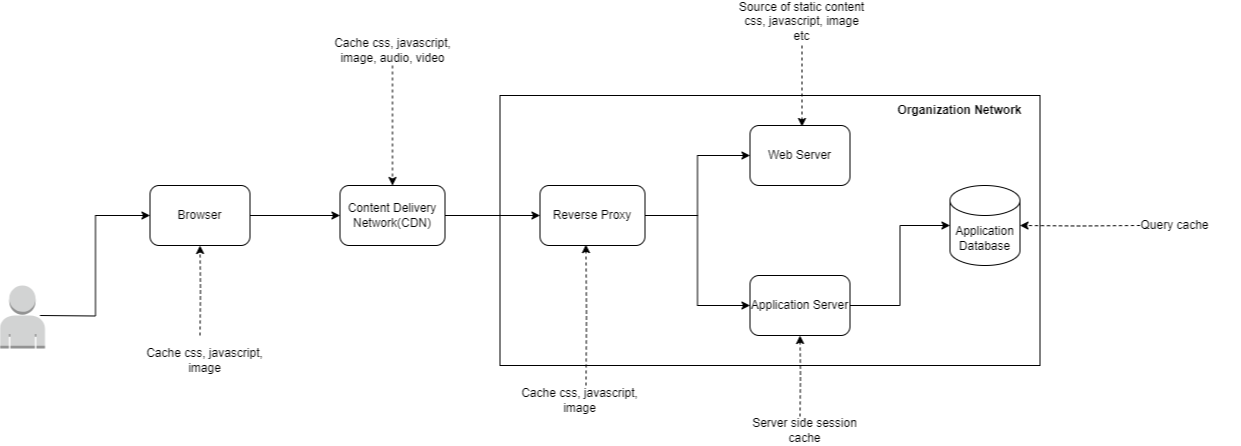
\ \ Before we start with explanation of the above diagram(Diagram 2), let’s first talk about categorization of caching in a web application. It can be done based on two different dimensions — what is cached and where is it cached.
What is cached?- Application resource — By application resource caching, we primarily mean static contents such as CSS, JavaScript, images etc. which are used to design the look & feel of a webpage. Application resource also includes media files though such as audio, video.
- Application data — By application data caching, we mean caching data that primarily resides in backend databases of an application
Generally application resources are cached at the infrastructure level(e.g. CDN, reverse proxy etc.) or on the client side(e.g. browser, device).
Whereas application data is cached on the server side(e.g. memory, disk or dedicated caching tool).
\
Let’s decompose Diagram 2 which shows the different layers of caching and explain how in a traditional on-premise application caching is implemented. A typical web application is composed of 3 different tiers — a web tier hosting the frontend web application running in an web server, a backend services tier running in application server and a database tier.
\ Traffic from internet through a web browser doesn’t hit the web and application server directly. Typically a Web Application Firewall(WAF)/DDoS mitigation tool sits in front of the network. This tool often also work as content delivery network(CDN). Traffic from the WAF/DDoS/CDN tool hits the reverse proxy of the network. The reverse proxy layer works as the interface to accept all traffic from the internet, hides identity of the actual backend servers from the external world where application is running. The reverse proxy server finally routes the traffic to appropriate backend server based on the resource path in the request URL.
\n If the request from the browser is for the web application then reverse proxy layer forwards the traffic to the web server. If the request is for a backend service, then traffic is routed to the application server.
Application Resource CachingWhen the request is to render a webpage, the static resources such as JavaScript, CSS, images used to render the webpage can be cached in all 3 layers — the reverse proxy, CDN and browser. What can be cached and can’t be cached are determined by the various HTTP headers as set by the web application such as — last-modified-since/is-modified-since, cache-control etc.
\n When the browser makes another request for the same webpage or for a different webpage which is reusing some of the static assets(JavaScript, images, CSS) of an already accessed webpage, the browser first checks if the assets have been changed in the application or not(using last-modified-since/is-modified-since header). If no change is found, then the cached asset in the browser is used to render the webpage. Otherwise the browser makes a request to the application to download the updated asset. Once browser makes request to the backend, the request is first intercepted by the CDN/DDOs/WAF layer. This layer does the exact same thing that the browser did i.e. it will check if the copy of the asset it has in it’s cache is same as the asset in backend, if yes, it will not forward the request for the resource to the reverse proxy but return the cached copy of the resource to the browser.
\n If the asset is not cached in CDN layer, then CDN layer does the same thing that browser did i.e. it forwards the request of the asset to the reverse proxy layer. The reverse proxy layer will serve the asset from cache if it hasn’t been updated in the application, otherwise will reach out to the backend web server to retrieve the fresh copy of the asset. The fresh copy of the asset returned by the web server is then cached by all 3 caching layer — reverse proxy, CDN and browser.
\n If the end user decides to clear the browser cache for some reason, then even though the browser will reach out to backend to fetch the asset, the asset will actually be returned by the CDN and/or reverse proxy instead of the backend web application server. As a result of that the end client still experiences improved response time as the resource is served by some upstream infrastructure layer of the application instead of the actual backend server. Needless to say, this also reduces the amount of traffic that hits the actual backend server. \n
The diagram below(Diagram 3) demonstrates the flow of application resource caching in different layers as described above.

When we talk about application data caching, it would typically mean caching data which generally doesn’t change frequently and therefore are good candidate of caching to reduce number of calls that goes to the database. One good example of that could be list of countries or list of states in a country that are displayed in a webpage. These are lookup table type of data and can be cached safely after retrieving once to avoid calling database every time for data that is mostly static. Another example we can think of is modern day day social media application where we may want to cache the home page feed of a user so that when the user launches the home page, the user sees the home page feed right away instead of waiting for several seconds.
\n Until the advent of cloud based applications or emergence of modern caching tools like Memcached, Redis, on-premise applications used to rely on session caching in application server. That typically would mean data which are candidate of caching would live in session of the user that gets created after login but they would not be available for reuse during their next login.
\n Some application servers like WebSphere had a separate caching solution to get around the session caching limitation called Dynacache — a distributed map. Dynacache would allow an application to cache data as key-value storage which is not tied with an user session. WebSphere used to keep this data in server memory and also had the provision of offloading the data into a disk if needed. It worked well given the lack of modern day caching tool we had at that moment but it had the limitation of cache not surviving a restart of the server(unless offloaded into disk). There were also challenges of maintaining consistency of data in cache in a clustered environment as each application server in the cluster would have it’s own copy of cache. Technically there was a provision to replicate cache between application servers in a cluster to address the consistency problem but that wasn’t something easy to implement and would come at a cost of performance.
\n However as the Diagram 2 above demonstrates, caching data at the application server layer is one of the options to cache data on server side. Databases and object-relation-mapping(ORM) tool like Hibernate also provides option to cache data using something called query cache. Databases can cache the result as well the entire SQL query in memory and serves data from memory as long as the data hasn’t been updated. Pretty much most of the common databases like MySQL, Oracle, PostgreSQL, SQL Server etc. supports query cache.
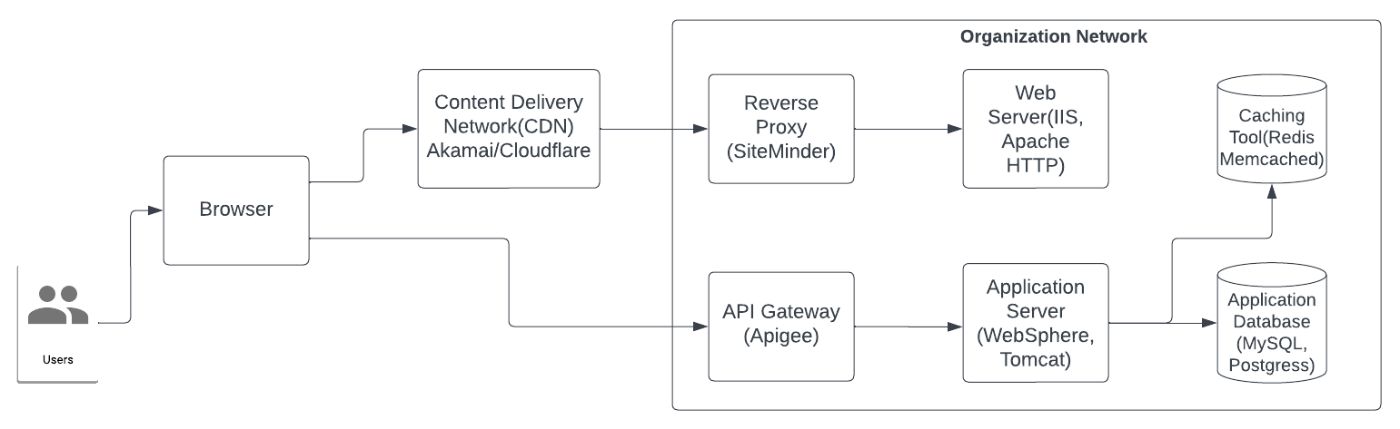
\ In modern day applications, the capability of data caching has improved significantly with advent of caching specialized technologies like Redis or Memcached. On top of that, modern day API Gateway layers that works as reverse proxies(along with providing tons of other features such as orchestration, rate limiting etc.) also provide ability to cache data for API calls. Though API Gateway(e.g. Apigee) and caching tool like Redis/Memcached can be implemented in an on-premise solution to power data caching, in reality, these toolsets are more popular for use in applications running in cloud platforms(e.g. AWS, Azure etc.).
\ The following pair of diagrams, demonstrates usage of API Gateway and caching tool(e.g. Redis, Memcached) for on-premise as well as cloud hosted applications.
\
\
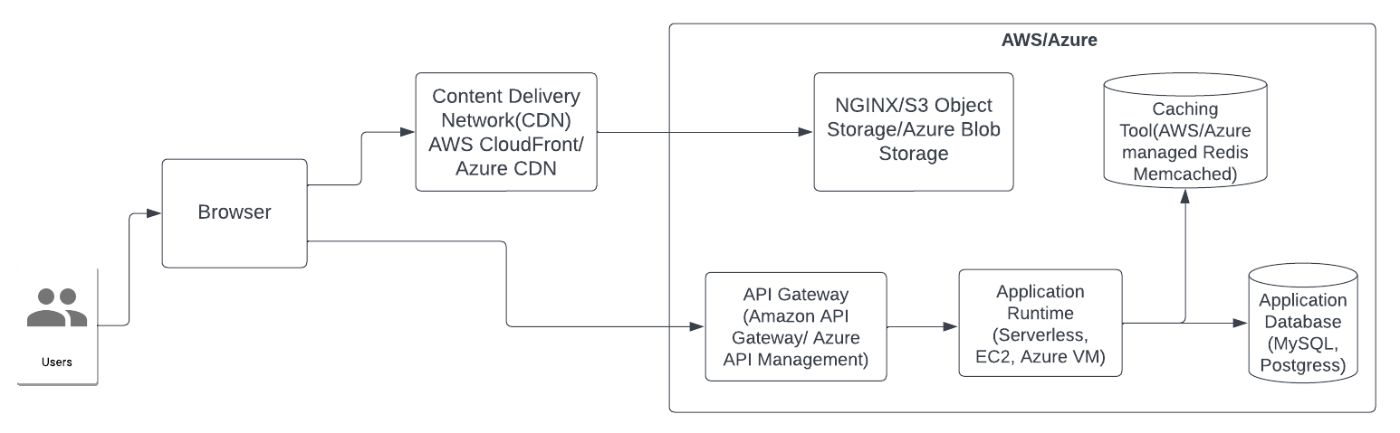
When the combination of database and caching tool is in place in architecture(common scenario in modern day applications), there are several techniques available to implement caching. There is no right or wrong techniques as all come with trade-offs. Depending on the nature of the use case, appropriate technique needs to be chosen.
\
- Cache aside — application reads from cache, if data not available in cache, then application reads from database and update cache. This is the caching pattern I have used mostly for the use cases I have personally encountered.
- Read through cache — application reads from cache and if data is not available in cache, then caching tool reads from database, updates cache and returns response.
- Write through cache — applications writes into cache, cache sends an acknowledgement immediately to reduce latency in client response and asynchronously writes data into database after that. This is a use case that can be adopted for a social media application where a post by a user can be made available for view to other users with sub-second latency. The actual operation of storing the data in a persistent store(database) happens asynchronously.
- Write back cache — data is written into cache only. Right before cache expires(typically after time-to-live aka TTL setting) data is written into the database for persistence. This technique can be used for a ride sharing system like Uber. Generally in a ride sharing system, a vehicle sends it’s current location every 30 seconds or so that a rider can get a real-time location update of the driver they are waiting for ride. In this caching pattern, the location of a car will only be updated in cache and before the cache expires the location data will be written to the database. This caching technique allows user/rider get to know the location of the driver instantaneously in the Uber app. If due to any reason the write to the database fails it results in a data loss. However generally this is acceptable if application doesn’t have history of location data for a car for a small interval of time(e.g. 5mins) in it’s persistent storage.
This wraps up the comprehensive exploration of various types of caching, encompassing where data is cached, the contrasting approaches employed in on-premise applications versus modern-day ones, and the diverse techniques utilized in this domain. As technology evolves, caching strategies will continue to adapt, offering new ways to balance speed, scalability, and consistency. Whether optimizing a small-scale application or architecting large distributed systems, leveraging caching effectively remains a key aspect of building high-performance solutions.