and the distribution of digital products.
Where does In-context Translation Happen in Large Language Models: Further Analysis
:::info Authors:
(1) Suzanna Sia, Johns Hopkins University;
(2) David Mueller;
(3) Kevin Duh.
:::
Table of Links- Abstract and 1. Background
- 2. Data and Settings
- 3. Where does In-context MT happen?
- 4. Characterising Redundancy in Layers
- 5. Inference Efficiency
- 6. Further Analysis
- 7. Conclusion, Acknowledgments, and References
- A. Appendix
In the following sections, we focus on GPTNEO and BLOOM to conduct deeper analysis on the main phenomena presented in the paper.
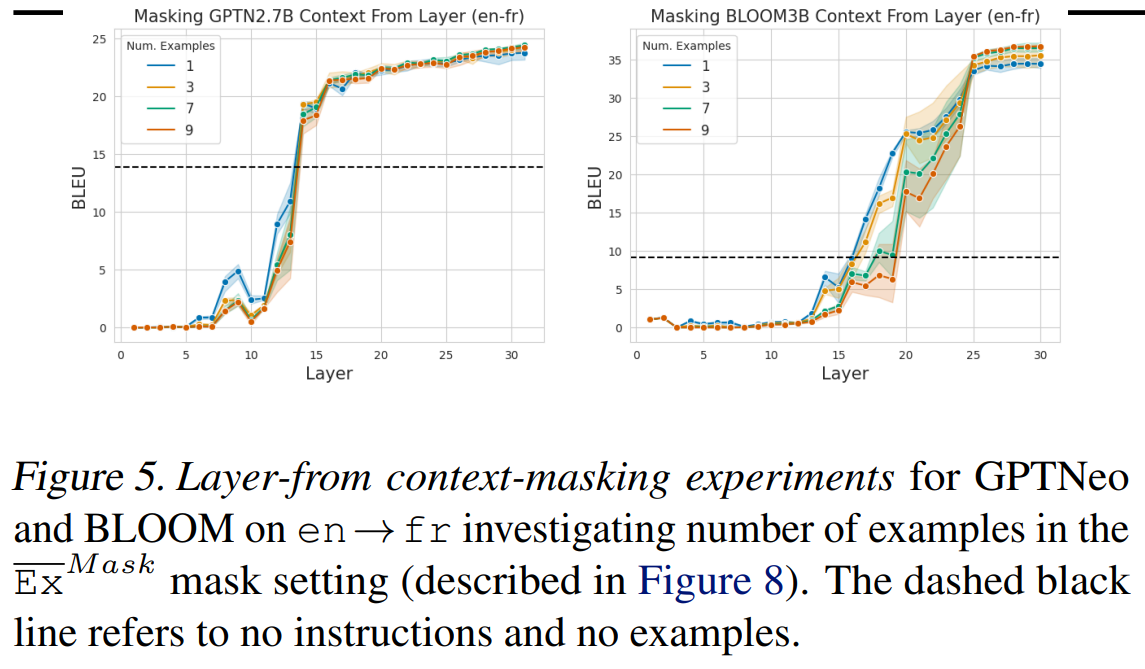
6.1. Does the Number of Prompts Affect Task Recognition?In Section 3 we study context-masking with a fixed number of prompts. However, it is not clear if the number of prompts affects how fast, layer-wise, the model is able to recognize the task. We plot these results for en→fr in Figure 5, for both GPTNEO and BLOOM. In general, we find that the number of prompt examples has little effect on which layer the task is recognized at. While there is some variation in performance when the context is masked around the middle layers of the model, the final performance plateau occurs at the same layer regardless of the number of prompts.
\
\
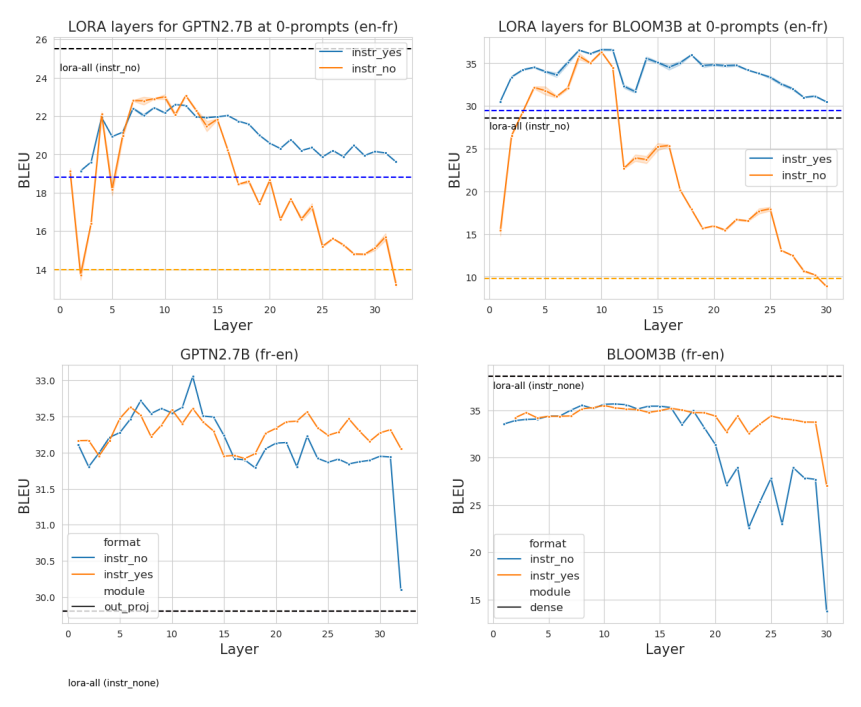
Intuitively, the layers prior to "task recognition" should contain information about locating the MT task. To test this intuition, we further explore the adaptability of these layers by lightweight fine-tuning experiments. We trained a single Low-rank Adaptation matrix (LoRA; Hu et al. (2021)) for each layer of the output projection while keeping the rest of the network frozen.[4] The model was shown parallel sentences as input, and layers were trained with no explicit translation instructions. We split the dev set of FLORES into 800 training examples and 200 dev examples. Note that this setup is designed to tune the layers for task location. It is highly unlikely that the model can learn translation knowledge from this small amount of supervision. The LoRA layers were trained for up to 50 epochs with early stopping patience= 5 and threshold= 0.001, with α = 32, r = 32 and dropout= 0.1. The cross-entropy loss was computed only on the target sentence (see Section A.5 for details) and we used the best checkpoint on the 200 held out dev examples for evaluation.
\ We show the results of this experiment in Figure 6; while each layer can be trained to perform better than no finetuning at all, tuning different layers have different impacts on performance. In particular, we find that high performing layers occur at the earlier to middle parts of the network, with the peak often occurring near the start of the "tasklocating" layers from Section 3. In contrast to common fine-tuning wisdom, additional tuning on the later layers has a much smaller impact on final performance for en → fr.
6.3. Are There Specialised Attention Heads?In Section 3, we found that the earlier part of the model is critical for task location from the prompt context, and in Section 4.1 we found both critical and redundant layers to the MT task. In this section, we increase the level of granularity to that of attention heads instead of layers.
\ A well established finding for supervised encoder-decoder MT models, is that up to 90% of the attention heads can be pruned while minimising fall in translation performance (Voita et al., 2019b; Behnke & Heafield, 2020; Michel et al., 2019). We note that asking about the extent of pruning is a slightly ill-formed research question, as it depends on the type of pruning technique used. However broad trends of highly prunable models have been observed in the supervised MT paradigm. In the in-context paradigm, there is no explicit supervision. Thus it is not clear if the task knowledge is spread across a much larger number of attention heads, or similarly specialised to a few heads. For instance, Bansal et al. (2023) studied attention-head importance for a broader set of ICL tasks, finding that the most important heads for ICL occur in the middle layers of the model.
6.4. Training Attention Head Gates with L0 regularisation
\
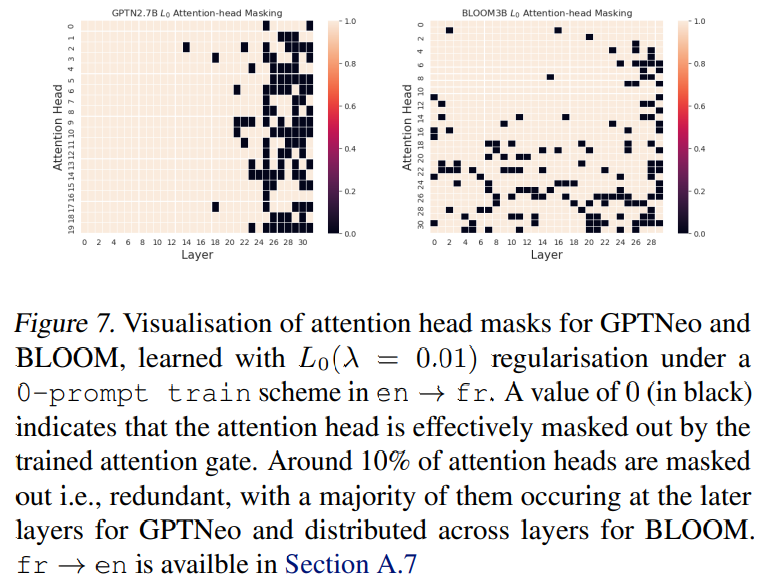
We noted that GPTNEO has some critical differences from BLOOM and LLAMA in terms of having critical layers (see Section 4.1). To what extent are there specialised attention heads for MT in the GPT-style models? If there were specialised heads, we would expect the model to be highly compressable/prunable to a select few heads. We plot a grid map of learned attention gate values for en → fr, where 0 indicates that the head is masked out (Figure 7). We find that most of the masked heads are distributed at the later layers for GPTNeo and are distributed across layers for BLOOM. This appears consistent with Section 4.1’s observations that redundancy is more focused at certain layers in GPTNeo, and more spread out across the layers for Bloom.
\ In addition, we note that there are no "few" specialised heads, which directly contrasts with the literature on compression in supervised MT models (Voita et al., 2019b; Michel et al., 2019). Potential reasons for this difference might include data distribution and model architecture, or cross-entropy loss associated with task tuning for MT vs non-specific training on large corpora. We leave this as an open question for future work.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[4] We also experimented with the training separate Key, Query and Value LoRA Layers but found this to be less effective.
\

\ [6] The class of Concrete distributions was invented to work around the problem of automatic differentiation of stochastic computation graphs.