and the distribution of digital products.
What Is DreamLLM? Everything You Need to Know About the Learning Framework
2 Background & Problem Statement
2.1 How can we use MLLMs for Diffusion Synthesis that Synergizes both sides?
3.1 End-to-End Interleaved generative Pretraining (I-GPT)
4 Experiments and 4.1 Multimodal Comprehension
4.2 Text-Conditional Image Synthesis
4.3 Multimodal Joint Creation & Comprehension
5 Discussions
5.1 Synergy between creation & Comprehension?
5. 2 What is learned by DreamLLM?
B Additional Qualitative Examples
E Limitations, Failure Cases & Future Works
ABSTRACTThis paper presents DREAMLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DREAMLLM operates on two fundamental principles.
\ The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained.
\ Second, DREAMLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DREAMLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DREAMLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DREAMLLM’s superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
1 INTRODUCTION“What I cannot create, I do not understand.”
Richard P. Feynman, on his blackboard at the time of his death, 1988
\ Content comprehension and creation in multimodality are crucial and among the ultimate courses of machine intelligence (Sternberg, 1985; Legg & Hutter, 2007). To this end, Multimodal Large Language Models (MLLMs) (Alayrac et al., 2022; Hao et al., 2022; Huang et al., 2023) have emerged as extensions of the successful GPT-style Large Language Models (LLMs) (Brown et al., 2020; Zhang et al., 2022; OpenAI, 2022; 2023; Chen et al., 2023b; Touvron et al., 2023a;b) into visual realm. Recognized as foundation models (Bommasani et al., 2021), MLLMs have achieved unprecedented progress in multimodal comprehension capabilities.
\ These advanced models typically enhance LLMs by incorporating images as multimodal inputs, such as CLIP features (Radford et al., 2021), to facilitate language-output multimodal comprehension. Their aim is to capture multimodal conditional or marginal distributions via a language posterior. However, multimodal creation, which involves generating images, texts, or both, necessitates a universal generative model that simultaneously learns language and image posteriors—currently underexplored.
\ Until very recently, some concurrent works have shown success in conditional image generation using MLLMs (Koh et al., 2023; Sun et al., 2023b). As depicted in Fig. 1, these methods compel MLLMs to produce either discrete or continuous conditional embeddings that explicitly align with a pretrained CLIP encoder, which could later be used by a pretrained Stable Diffusion (SD) (Rombach et al., 2022) model for image generation.
\ However, due to an inherent modality gap (Liang et al., 2022), CLIP semantics focus predominantly on modality-shared information, often overlooking modality-specific knowledge that could enhance multimodal comprehension. Consequently, these studies have not fully realized the potential learning synergy between multimodal creation and comprehension, have shown only marginal improvements in creativity, and remain deficient in multimodal comprehension.
\
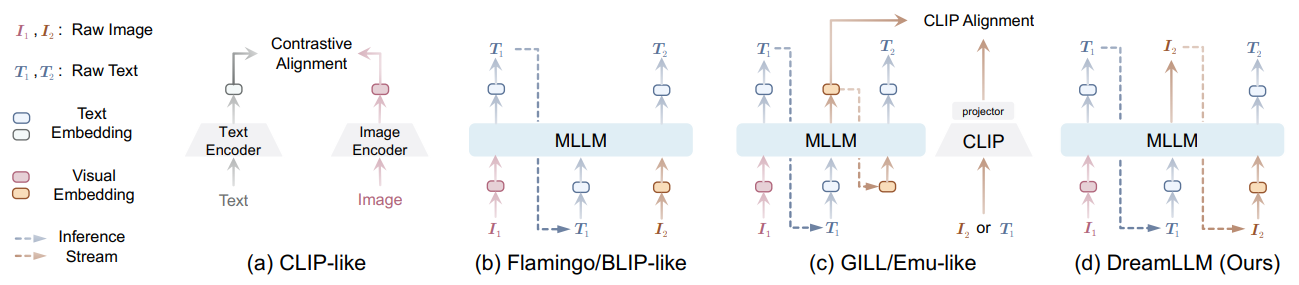
\ In this work, we introduce DREAMLLM, universally learning image and text posteriors with expected creation & comprehension synergy, based on the following two de-facto designing principles:
\ i. Generate Everything as It Is Different from existing works that generate intermediate image representations like CLIP embeddings during training, DREAMLLM not only takes all modalities raw data as inputs but also as outputs in a truly end-to-end fashion (i.e., outputs are identical to inputs, see Fig. 1).
\ The challenge lies in enabling MLLMs to learn the image posterior without compromising their comprehension capabilities. To address this, we introduce dream queries, a set of learnable embeddings that encapsulate the semantics encoded by MLLMs. This approach avoids altering the output space of MLLMs.
\ Raw images are then decoded by the SD image decoder conditioned on these semantics. In this fashion, the pretrained SD acts as the score function (Ho et al., 2020). The image posterior is thus modeled by direct sampling in the pixel space, facilitated by score distillation (van den Oord et al., 2018; Poole et al., 2023).
\ ii. Interleaved Generative Pre-Training (I-GPT) DREAMLLM is trained to generate interleaved multimodal corpora from the internet (Zhu et al., 2023b), both encoding and decoding interleaved image-text multimodal inputs. Unlike encoding multimodal inputs as in existing methods, decoding interleaved multimodal outputs is challenging due to the complex interleaving layout structures and the long-context requirement of image.
\ Our approach tackles the interleaved layout learning using a unique token that predicts the placement of images within texts. Harnessing DREAMLLM’s causal nature, all contents are generated with history multimodal contexts of any length. This interleaved generative pretraining (I-GPT) inherently forms all joint, marginal, and conditional distributions of images and texts in the document, leading to a learning synergy that grounds DREAMLLM’s comprehension in creation and vice versa.
\ Extensive experiments across various vision-language comprehension, content creation, and languageonly tasks demonstrate DREAMLLM’s superior performance as a zero-shot multimodal generalist. For instance, DREAMLLM-7B achieves an 8.46 FID on MS-COCO and sets a new standard with 49.1/35.9 scores on MMBench and MM-Vet evaluations, respectively.
\ Moreover, we delve into the learning synergy between comprehension and creation, revealing decent in-context generation capabilities.
\ With I-GPT pretraining, DREAMLLM generates interleaved documents following human prompts after supervised fine-tuning on instruction-following data, curated with GPT-4. To our knowledge, this work is the first to enable MLLMs to create free-form interleaved content with a learning synergy on both sides. As a foundational learning framework, DREAMLLM is adaptable across all modalities, laying a promising foundation for future multimodal learning research.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
:::
:::info Authors:
(1) Runpei Dong, Xi’an Jiaotong University and Internship at MEGVII;
(2) Chunrui Han, MEGVII Technology;
(3) Yuang Peng, Tsinghua University and Internship at MEGVII;
(4) Zekun Qi, Xi’an Jiaotong University and Internship at MEGVII;
(5) Zheng Ge, MEGVII Technology;
(6) Jinrong Yang, HUST and Internship at MEGVII;
(7) Liang Zhao, MEGVII Technology;
(8) Jianjian Sun, MEGVII Technology;
(9) Hongyu Zhou, MEGVII Technology;
(10) Haoran Wei, MEGVII Technology;
(11) Xiangwen Kong, MEGVII Technology;
(12) Xiangyu Zhang, MEGVII Technology and a Project leader;
(13) Kaisheng Ma, Tsinghua University and a Corresponding author;
(14) Li Yi, Tsinghua University, a Corresponding authors and Project leader.
:::
\