and the distribution of digital products.
Transfer Attacks Reveal SLM Vulnerabilities and Effective Noise Defenses
Part 1: Abstract & Introduction
Part 2: Background
Part 3: Attacks & Countermeasures
Part 4: Experimental Setup
Part 5: Datasets & Evaluation
Part 6: Attack, Countermeasure Parameters, & Baseline: Random Perturbations
Part 7: Results & Discussion
Part 8: Transfer Attacks & Countermeasures
Part 9: Conclusion, Limitations, & Ethics Statement
Part 10: Appendix: Audio Encoder Pre-training & Evaluation
Part 11: Appendix: Cross-prompt attacks, Training Data Ablations, & Impact of random noise on helpfulness
Part 12: Appendix: Adaptive attacks & Qualitative Examples
5.3 Transfer attacksIn this section, we report the results of crossmodel attacks, where perturbations generated by white-box attacks on a surrogate model are applied directly on the victim models. Similar to Section 5.2, we consider only the set of originally safe audios for the jailbreak analysis. From Table 4, we see that the models exhibit varying amount of vulnerability to cross-model perturbations. In
\
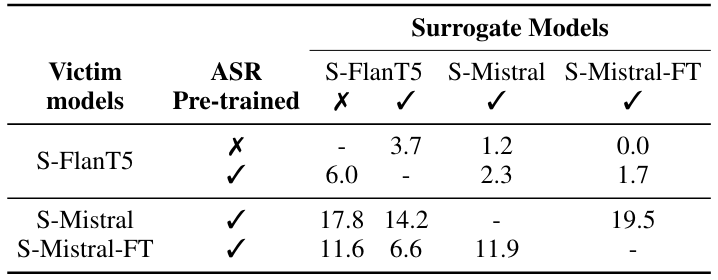
\ general, the FlanT5-based models are more robust to such perturbations even when the surrogate model uses similar architecture. This finding aligns with the sample-specific results we showed earlier in Section 5.2. Note that these experiments were conducted on internally developed models that use similar training strategies and data. Therefore, this is a “grey-box” scenario, where attacker has access to a limited knowledge about the victim models.
\ To evaluate the effectiveness of the generated perturbations in a true black-box setting, we also apply the perturbations on the publicly available SpeechGPT model. The number of audio samples evaluated is much fewer for this model because of the relatively smaller number of originally safe audios. From the results in Table 5, first we see that random perturbations cause significant jailbreaks. Further, we observe that adversarial perturbations are not as effective in this setting. This demonstrates the need for characterizing the models’ safety from several angles including random perturbations. We also evaluated cross-prompt attacks, and observed that it yielded successful attacks only on par with random noise (see results in Appendix A.3).
\

\
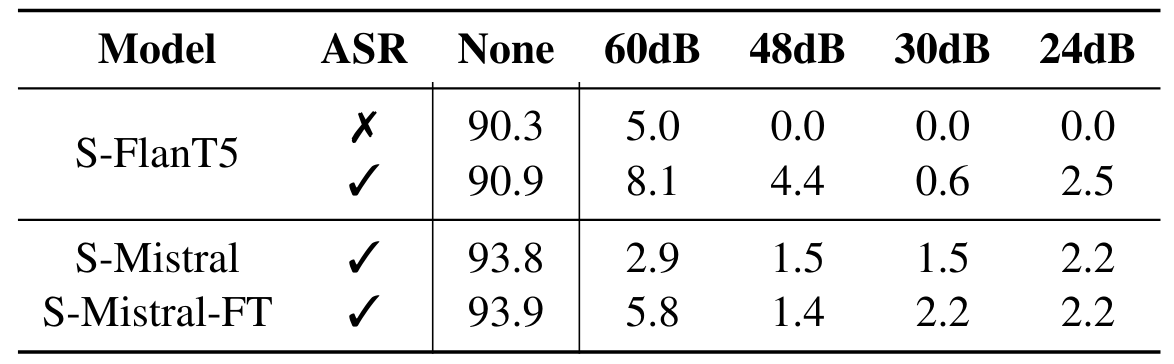
In Table 6, we report the results of applying the proposed TDNF defense that injects random noise (at 4 different SNRs) to the audios. We observe that in all the cases, the TDNF defense reduces the %JSR by a substantial margin compared to no defense (shown in column “None”). Such noise addition does not significantly impact the helpfulness of our systems (see Appendix A.5 for more details). Combined with the results on random noise presented in Table 3, we can conclude that a simple pre-processing defense is a viable solution to thwart adversarial jailbreaking threats, with minimal impact on the utility.
\ We also performed adaptive attacks, where the attacker has knowledge of the defense. We found that an adaptive attacker can evade the defense, albeit with reduced success and at a much lower SPR, rendering the perturbations more perceptible.[14]
\
:::info Authors:
(1) Raghuveer Peri, AWS AI Labs, Amazon and with Equal Contributions ([email protected]);
(2) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon and with Equal Contributions;
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Anshu Bhatia, AWS AI Labs, Amazon;
(5) Karel Mundnich, AWS AI Labs, Amazon;
(6) Saket Dingliwal, AWS AI Labs, Amazon;
(7) Nilaksh Das, AWS AI Labs, Amazon;
(8) Zejiang Hou, AWS AI Labs, Amazon;
(9) Goeric Huybrechts, AWS AI Labs, Amazon;
(10) Srikanth Vishnubhotla, AWS AI Labs, Amazon;
(11) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(12) Sundararajan Srinivasan, AWS AI Labs, Amazon;
(13) Kyu J Han, AWS AI Labs, Amazon;
(14) Katrin Kirchhoff, AWS AI Labs, Amazon.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\