and the distribution of digital products.
Traditional Monitoring Is Dead. Long Live Data Observability
Traditional monitoring no longer meets the needs of complex data organizations. Instead of relying on reactive systems to identify known issues, data engineers must create interactive observability frameworks that help them quickly find any type of anomaly.
\ While observability can encompass many different practices, in this article, I'll share a high-level overview and practical tips from our experience building an observability framework in our organization using open-source tools.
\ So, how to build infrastructure that has good data health visibility and ensures data quality?
What is data observability?Overall, observability defines how much you can tell about an internal system from its external outputs. The term was first defined in 1960 by Hungarian-American engineer Rudolf E. Kálmán, who discussed observability in mathematical control systems.
\ Over the years, the concept has been adapted to various fields, including data engineering. Here, it addresses the issue of data quality and being able to track where the data was gathered and how it was transformed.
\ Data observability means ensuring that data in all pipelines and systems is integral and of high quality. This is done by monitoring and managing real-time data to troubleshoot quality concerns. Observability assures clarity, which allows action before the problem spreads.
What is a data observability framework?Data observability framework is a process of monitoring and validating data integrity and quality within an institution. It helps to proactively ensure data quality and integrity.
\ The framework must be based on five mandatory aspects, as defined by IBM:
\
- Freshness. Outdated data, if any, must be found and removed.
- Distribution. Expected data values must be recorded to help identify outliers and unreliable data.
- Volume. The number of expected values must be tracked to ensure data is complete.
- Schema. Changes to data tables and organization must be monitored to help find broken data.
- Lineage. Collecting metadata and mapping the sources is a must to aid troubleshooting.
\ These five principles ensure that data observability frameworks help maintain and increase data quality. You can achieve these by implementing the following data observability methods.
How to add observability practices into the data pipelineOnly high-quality data collected from reputable sources will provide precise insights. As the saying goes: garbage in, garbage out. You cannot expect to extract any actual knowledge from poorly organized datasets.
\ So, how do we ensure the quality of data at Coresignal? It all comes down to adding better observability methods into each data pipeline stage – from ingestion and transformation to storage and analysis. Some of these methods will work across the entire pipeline while others will be relevant in only one stage of it. Let's take a look:
\
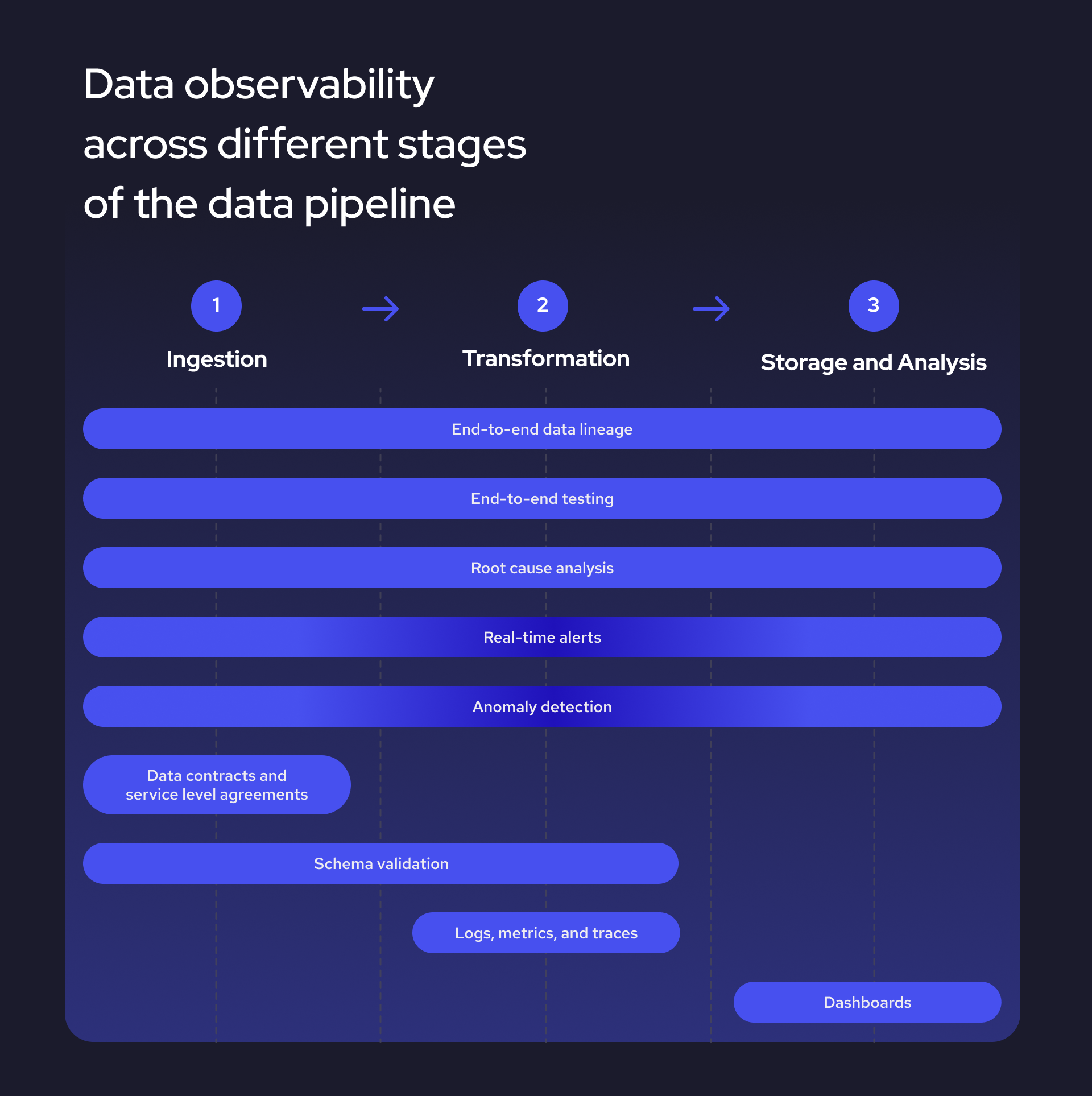
\ First off, we have to consider five items that cover the entire pipeline:
\
- End-to-end data lineage. Tracking lineage lets you quickly access database history and follow your data from the original source to the final output. By understanding the structure and its relationships, you will have less trouble finding inconsistencies before they become problems.
- End-to-end testing. A validation process that checks data integrity and quality at each data pipeline stage helps engineers determine if the pipeline functions correctly and spot any untypical behaviors.
- Root cause analysis. If issues emerge at any stage of the pipeline, engineers must be able to pinpoint the source precisely and find a quick solution.
- Real-time alerts. One of the most important observability goals is to quickly spot emerging issues. Time is of the essence when flagging abnormal behaviors, so any data observability framework has to be able to send alerts in real time. This is especially important for the data ingestion as well as storage and analysis phases.
- Anomaly detection. Issues such as missing data or low performance can happen anywhere across the data pipeline. Anomaly detection is an advanced observability method that is likely to be implemented later in the process. In most cases, machine learning algorithms will be required to detect unusual patterns in your data and logs.
\ Then, we have five other items that will be more relevant in one data pipeline stage than the other:
\
- Service level agreements (SLAs). SLAs help set standards for the client and the supplier and define the data quality, integrity, and general responsibilities. SLA thresholds can also help when setting up an alert system, and typically, they will be signed before or during the ingestion phase.
- Data contracts. These agreements define how data is structured before it enters other systems. They act as a set of rules that clarify what level of freshness and quality you can expect and will usually be negotiated before the ingestion phase.
- Schema validation. It guarantees consistent data structures and ensures compatibility with downstream systems. Engineers usually validate the schema during the ingestion or processing stages.
- Logs, metrics, and traces. While essential for monitoring performance, collecting and easily accessing this crucial information will become a helpful tool in a crisis—it allows one to find the root cause of a problem faster.
- Data quality dashboards. Dashboards help monitor the overall health of the data pipeline and have a high-level view of possible problems. They ensure that the data gathered using other observability methods is presented clearly and in real time.
\ Finally, data observability cannot be implemented without adding self-evaluation to the framework, so constant auditing and reviewing of the system is a must for any organization.
\ Next, let's discuss the tools you might want to try to make your work easier.
Data observability platforms and what can you do with themSo, which tools should you consider if you are beginning to build a data observability framework in your organization? While there are many options out there, in my experience, your best bet would be to start out with the following tools.
\ As we were building our data infrastructure, we focused on making the most out of open source platforms. The tools listed below ensure transparency and scalability while working with large amounts of data. While most of them have other purposes than data observability, combined, they provide a great way to ensure visibility into the data pipeline.
\ Here is a list of five necessary platforms that I would recommend to check out:
\
- Prometheus and Grafana platforms complement each other and help engineers collect and visualize large amounts of data in real time. Prometheus, an open-source monitoring system, is perfect for data storage and observation, while the observability platform Grafana helps track new trends through an easy-to-navigate visual dashboard.
- Apache Iceberg table format provides an overview of database metadata, including tracking statistics about table columns. Tracking metadata helps to better understand the entire database without unnecessarily processing it. It's not exactly an observability platform, but its functionalities allow engineers to get better visibility into their data.
- Apache Superset is another open-source data exploration and visualization tool that can help to present huge amounts of data, build dashboards, and generate alerts.
- Great Expectations is a Python package that helps test and validate data. For instance, it can scan a sample dataset using predefined rules and create data quality conditions that are later used for the entire dataset. Our teams use Great Expectations to run quality tests on new datasets.
- Dagster data pipeline orchestration tool can help ensure data lineage and run asset checks. While it was not created as a data observability platform, it provides visibility using your existing data engineering tools and table formats. The tool aids in figuring out the root causes of data anomalies. The paid version of the platform also contains AI-generated insights. This application provides self-service observability and comes with an in-built asset catalog for tracking data assets.
\ Keep in mind that these are just some of the many options available. Make sure to do your research and find the tools that make sense for your organization.
What happens if you ignore the data observability principlesOnce a problem arises, organizations usually rely on an engineer's intuition to find the root cause of the problem. As software engineer Charity Majors vividly explains in her recollection of her time at MBaaS platform Parse, most traditional monitoring is powered by engineers who have been at the company the longest and can quickly guess their system's issues. This makes senior engineers irreplaceable and creates additional issues, such as high rates of burnout.
\ Using data observability tools eliminates guesswork from troubleshooting, minimizes the downtime, and enhances trust. Without data observability tools, you can expect high downtime, data quality issues, and slow reaction times to emerging issues. As a result, these problems might quickly lead to loss of revenue, customers, or even damage brand reputation.
\ Data observability is vital for enterprise-level companies that handle gargantuan amounts of information and must guarantee its quality and integrity without interruptions.
What’s next for data observability?Data observability is a must for every organization, especially companies that work with data collection and storage. Once all the tools are set in place, it’s possible to start using advanced methods to optimize the process.
\ Machine learning, especially large language models (LLMs), is the obvious solution here. They can help to quickly scan the database, flag anomalies, and help to improve the overall data quality by spotting duplicates or adding new enriched fields. At the same time, these algorithms can help keep track of the changes in the schema and logs, improving the data consistency and improving data lineage.
\ However, it is crucial to pick the right time to implement your AI initiatives. Enhancing your observability capabilities requires resources, time, and investment. Before starting to use custom LLMs, you should carefully consider whether this would truly benefit your organization. Sometimes, it might be more efficient to stick to the standard open-source data observability tools listed above, which are already effective in getting the job done.