and the distribution of digital products.
Revolutionizing Petabyte-Scale Data Processing on AWS: Advanced Framework Unveiled
Abstract:
This article presents an advanced framework for processing petabyte-scale datasets using AWS Glue Interactive Sessions, custom libraries, and Amazon Athena. The framework addresses significant challenges in scalability, cost-efficiency, and performance for massive data volumes. Our results demonstrate substantial improvements in processing efficiency and cost reduction, with up to 60% decrease in processing costs and 40% improvement in processing times for compressed datasets.
Introduction:The exponential growth of data across industries has created an urgent need for robust processing frameworks capable of handling petabyte-scale datasets. Traditional data processing methods often struggle with scalability, cost-efficiency, and performance when applied to such massive volumes of data. Moreover, the diversity of data formats and compression types introduces additional complexity to data processing pipelines.
\ This article explores the development of a scalable data processing framework utilizing AWS Glue Interactive Sessions and custom libraries, supplemented by Amazon Athena for specific use cases. The framework aims to address the challenges associated with petabyte scale data processing, including efficient handling of various file compression formats, cost effective resource management, maintenance of processing speed of scale, and reliable processing across diverse data formats.
BackgroundPrevious research has highlighted the limitations of traditional data processing systems in handling large-scale data efficiently. Cloud based solutions, particularly AWS services like Amazon Athena and AWS Glue are two services which provide big data processing and querying. However, there is a need for a cohesive framework that intelligently leverages these services based on data characteristics to optimized performance and cost.
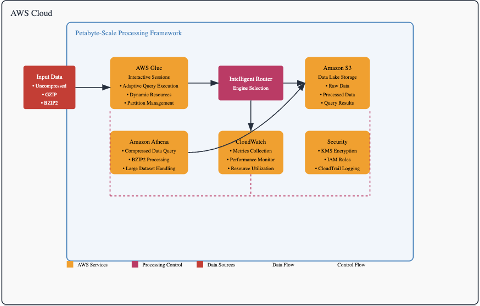
MethodologyThe proposed data processing framework integrates AWS Glue Interactive Sessions as the primary processing engine, with Amazon Athena utilized for specific compression scenarios. The architecture is designed to provide:
\
Interactive Development Capabilities: Allowing data engineers to rapidly iterate and develop data processing skills.
Flexible Processing Options: Selecting the optimal processing engine based on data characteristics such as size and compression type.
Cost optimization: Dynamically allocating compute resources to balance cost and resources.
Scalability: Ensure the framework can handle petabyte scale datasets efficiently.
\
\
Implementation DetailsCore Processing Class: The framework centers around a processing class that orchestrates workloads across AWS Glue and Amazon Athena. This class initializes a SparkSession specifically configured for AWS Glue, which is crucial for handling large scale data processing tasks. It also establishes connections to AWS services by creating clients for Athena- used for querying data-and Glue, which handles data processing operations.
\ Intelligent Processing Selection: A standout feature of the framework is its ability to select the most appropriate processing engine based on the characteristics of the dataset, such as compression type and size. The selection criteria include:
\
- Gzip-Compressed Data: If the data is compressed with ‘gzip’ and surpasses a certain size threshold, the framework opts for Amazon Athena.
- Bzip2-Compressed Data: Datasets compressed with ‘bzips2’ are always processed using Athena.
- Snappy and Uncompressed Data: For data compressed with ‘snappy’ or uncompressed data, AWS Glue is typically the chosen engine.
\ Cost Optimized Resource Allocation:
\ To maintain a balance between performance and cost, the framework dynamically adjusts computing resources based on the size of the dataset. Larger datasets are allocated more powerful computing resources, while smaller ones use standard resources. This strategy involves setting the number of involves setting the number of workers and memory requirements in proportion to the data size, ensuring that resources are effectively matched to the workload.
\ Performance Optimization Techniques:
\ The framework incorporates several optimization strategies:
\
Adaptive Query Execution:
i) Enables Spark to optimize queries dynamically based on the data being processed.
ii) Results in improved query performance.
\
Smart Partition Management:
i) Analysis data partitions to identify optimization opportunities.
ii) Adjusts partitions to enhance processing efficiency when beneficial.
\ Monitoring and Observability:
\ Effective monitoring is essential for maintaining high performance and quickly identifying any issues during processing. The framework integrates with AWS CloudWatch to track metrics related to processing efficiency, such as bytes processed per second. This integration provides valuable insights into the systems’ performance and aids in troubleshooting when necessary.
\ Results:
\ Implementation of the proposed framework has demonstrated significant benefits:
\
- Cost reduction: Up to 60% reduction in processing costs through intelligent selection of the processing engine and dynamic resource allocation.
- Performance Improvement: Approximately 40% improvement in processing times for compressed datasets, particularly when using Amazon Athena for suitable scenarios.
- Scalability: The framework efficiently handles petabyte-scale datasets, providing near real time processing capabilities.
- Simplified Development Workflow: Interactive sessions and modular code design simplify the development and maintenance of data processing jobs.
The framework’s intelligent processing selection ensures that datasets are processed using the most efficient engine based on their characteristics. By leveraging AWS Glue for uncompressed or lightly compressed data and Amazon Athena for heavily compressed data or specific compression types (e.g., bzip2), the framework optimizes both performance and cost. Dynamic resource allocation aligns computing resources with workload demands, preventing over-provisioning and underutilization of resources. The adaptive query execution and smart partition management further enhance performance by optimizing data processing operations at runtime.
Future Work:Several enhancements are proposed for future iterations of the framework:
\
- Integration with AWS Lake Formation: To provide fine grained access control and data governance capabilities.
- Automated Testing Frameworks: Implementation of comprehensive testing to ensure reliability and robustness.
- Support for Streaming Data Processing: Extending the framework to handle real-time data streams using technologies such as Apache Kafka and AWS Kinesis.
- Complex Orchestration with AWS Step Functions: Integration for orchestrating complex workflows and handling dependencies between data processing tasks.
\ Conclusion:
This paper presents a robust and cost-effective solution for processing petabyte scale data by combining AWS Glue Interactive sessions, custom libraries, and Amazon Athena. The framework addresses the challenges of handling diverse data formats and compression types while maintaining optimal performance and cost efficiency. Organizations adopting this framework can expect significant improvements in processing efficiency, cost savings, and scalability.