and the distribution of digital products.
Pretraining Task Analysis On LLM Video Generati
:::info Authors:
(1) Dan Kondratyuk, Google Research and with Equal contribution;
(2) Lijun Yu, Google Research, Carnegie Mellon University and with Equal contribution;
(3) Xiuye Gu, Google Research and with Equal contribution;
(4) Jose Lezama, Google Research and with Equal contribution;
(5) Jonathan Huang, Google Research and with Equal contribution;
(6) Grant Schindler, Google Research;
(7) Rachel Hornung, Google Research;
(8) Vighnesh Birodkar, Google Research;
(9) Jimmy Yan, Google Research;
(10) Krishna Somandepalli, Google Research;
(11) Hassan Akbari, Google Research;
(12) Yair Alon, Google Research;
(13) Yong Cheng, Google DeepMind;
(14) Josh Dillon, Google Research;
(15) Agrim Gupta, Google Research;
(16) Meera Hahn, Google Research;
(17) Anja Hauth, Google Research;
(18) David Hendon, Google Research;
(19) Alonso Martinez, Google Research;
(20) David Minnen, Google Research;
(21) Mikhail Sirotenko, Google Research;
(22) Kihyuk Sohn, Google Research;
(23) Xuan Yang, Google Research;
(24) Hartwig Adam, Google Research;
(25) Ming-Hsuan Yang, Google Research;
(26) Irfan Essa, Google Research;
(27) Huisheng Wang, Google Research;
(28) David A. Ross, Google Research;
(29) Bryan Seybold, Google Research and with Equal contribution;
(30) Lu Jiang, Google Research and with Equal contribution.
:::
Table of Links3. Model Overview and 3.1. Tokenization
3.2. Language Model Backbone and 3.3. Super-Resolution
4. LLM Pretraining for Generation
5. Experiments
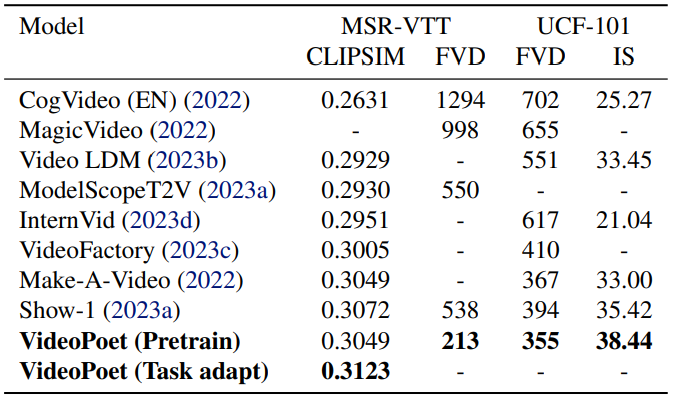
5.2. Pretraining Task Analysis
5.3. Comparison with the State-of-the-Art
5.4. LLM’s Diverse Capabilities in Video Generation and 5.5. Limitations
6. Conclusion, Acknowledgements, and References
5.2. Pretraining Task Analysis
\ For the analysis of pretraining tasks, we consider text-to-video (T2V), text-to-image (T2I), and four self-supervised learning (SSL) tasks: frame prediction (FP), central inpainting and central outpainting (Painting) (Yu et al., 2023a) and audio-video continuation (AVCont) where the model is provided with the first frame and its corresponding audio to predict the subsequent 16 frames and matching audio. For each video task, we uniformly select 20% of training samples from a random subset of 50 million videos. For the text-to-image task, we randomly sample 50 million text-image pairs from our training dataset. For tasks involving audio, our sampling is exclusive to videos that contain an audio track.
\ The evaluation results are presented in Table 1. We assess a model across the four tasks within the zero-shot evaluation benchmark: the T2V task on MSR-VTT (Xu et al., 2016) and UCF 101 (Soomro et al., 2012), the FP on K600 (Carreira et al., 2018), and central inpainting and outpainting on SSv2 (Goyal et al., 2017). In these experiments, we employ a single model to perform all the tasks. The model is not trained on the training data of these evaluation datasets, and thus it is a zero-shot evaluation.
\ The top rows of Table 1 depict each pretraining task configuration of the 300 million parameter model, which are comparable in their setups. Our evaluation benchmarks span diverse visual domains, posing a challenge to achieving consistent improvement across all of them. Nevertheless, incorporating all pretraining tasks results in the best overall performance, on average, across all evaluated tasks. Additionally, the significant disparity observed in the “SSL” row suggests the limitations of self-supervised training and underscores the necessity for text-paired data during training. The last row, “ALL (8B)”, is the model with 8 billion parameters, trained on the pretraining tasks as discussed in Section 3 and utilized significantly more compute.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\