and the distribution of digital products.
The Perplexity Puzzle: How Low-Bit Quantization Affects AI Accuracy
:::info Authors:
(1) Wanyun Cui, Shanghai University of Finance and Economics, with equal contribution;
(2) Qianle Wang, Shanghai University of Finance and Economics, with equal contribution.
:::
Table of Links3 Quantifying the Impact of Parameters on Model Performance & 4. Unified Mixed-Precision Training
5 Prevalence of Parameter Heterogeneity in LLMs
6 Quantization Experiments and 6.1 Implementation Details
6.2 Effect of Base LLM Quantization
6.3 Effect of Chat LLM Quantization
6.4 Comparison of Parameter Selection Criteria, Conclusion, & References
6.2 Effect of Base LLM QuantizationIn this section, we present the main experimental results demonstrating the effectiveness of CherryQ on LLaMA2 [23]. We evaluate CherryQ with both perplexity and downstream tasks, comparing its performance against state-of-the-art quantization methods.
6.2.1 Perplexity ResultsWe follow [8, 21] to evaluate the perplexity of CherryQ on two widely-used corpora: C4 and WikiText2 [19]. We use the validation split of C4 to avoid data leakage. We show the results of 3-bit quantization using different quantization approaches in Table 1. We show the results of different model scales and different group sizes.
\ From the results, CherryQ consistently outperforms all other approaches across both model sizes (7B and 13B) and grouping sizes (64 and 128), achieving the lowest perplexity on both the C4 and WikiText-2 datasets. Notably, CherryQ’s perplexity is significantly closer to the full-precision (FP16) baseline compared to other methods, highlighting its ability to preserve model performance after quantization.
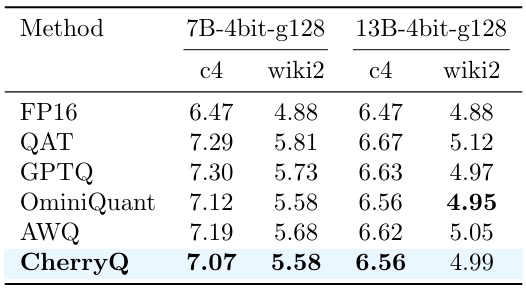
\ Table 2 compares different 4-bit quantization methods. Again, CherryQ achieves the lowest perplexity scores in most settings, demonstrating its effectiveness in higher-bit quantization settings.
6.2.2 Downstream Task PerformanceTo further validate the effectiveness on specific tasks, we evaluate the quantized models on various downstream tasks from the HuggingFace OpenLLM Leaderboard. Table 3 presents the performance comparison of different 3-bit quantization methods for LLaMA2. CherryQ consistently outperforms other methods across almost all tasks, achieving the highest average score. This showcases CherryQ’s ability to maintain the model’s generalization capabilities for downstream tasks.
\
![Perplexity (↓) of 3-bit quantization on LLaMA2 models . gX means the group size is X. The results of OminiQuant and AWQ are from [21]. The results of SqueezeLLM are from [13].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-me8319v.png)
\ Table 4 extends the comparison to 4-bit quantization. CherryQ continues to excel, achieving the highest scores on most individual tasks and the highest average score overall. These results highlight the generalization ability of CherryQ across different quantization bits and model sizes.
\
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\