and the distribution of digital products.
This New AI Model Is Excelling in Understanding and Interacting with Images
:::info Authors:
(1) Hanoona Rasheed, Mohamed bin Zayed University of AI and equally contributing first authors;
(2) Muhammad Maaz, Mohamed bin Zayed University of AI and equally contributing first authors;
(3) Sahal Shaji, Mohamed bin Zayed University of AI;
(4) Abdelrahman Shaker, Mohamed bin Zayed University of AI;
(5) Salman Khan, Mohamed bin Zayed University of AI and Australian National University;
(6) Hisham Cholakkal, Mohamed bin Zayed University of AI;
(7) Rao M. Anwer, Mohamed bin Zayed University of AI and Aalto University;
(8) Eric Xing, Mohamed bin Zayed University of AI and Carnegie Mellon University;
(9) Ming-Hsuan Yang, University of California - Merced and Google Research;
(10) Fahad S. Khan, Mohamed bin Zayed University of AI and Linköping University.
:::
:::tip Editor's Note: This is Part 2 of 10 of a study detailing the development of an AI model that is designed to describe images to users. Read the rest below.
:::
Table of Links- Abstract and 1 Introduction
- 2. Related Work
- 3. Method
- 4. Data Annotation Pipeline
- 5. Experiments
- 6. Conclusion and References
\ Supplementary Material (Part 1)
- A. Additional Implementation Details
- B. Additional Downstream Tasks
- C. Additional Qualitative Results
\ Supplementary Material (Part 2)
2. Related WorkLMMs provide a versatile interface for a diverse array of tasks, encompassing language and vision. Prominent models such as BLIP-2 [24], LLaVA [29], InstructBLIP [6] and MiniGPT-4 [61] first conduct image-text feature alignment followed by instruction tuning. Other representative works include Otter [22], mPLUG-Owl [52], LLaMaAdapter [56], Video-ChatGPT [32], InternGPT [31]. However, these approaches lack region-specific understanding.
\ Recent works like Kosmos-2 [35], Shikra [5], GPT4RoI [57], VisionLLM [44], Ferret [53] and All-Seeing [45] aim to allow region-specific conversation. Some methods [5, 35, 45, 53] input location bins and bounding boxes with image data for region-level understanding, relying on the LLM exclusively for interpreting these regions. GPT4RoI advances this by using spatial boxes and RoI-aligned features for input and training on region-text pairs. BuboGPT [59] utilizes an off-the-shelf grounding model [30] and matches the groundings with the language response. In contrast, LISA [21] utilizes embeddings from the vision language model and the SAM [18] decoder to generate output segmentation masks. However, LISA cannot comprehend specific image regions or handle multiple instances.
\ To classify the LMM landscape, methods can be partitioned into four distinct categories (see Tab. 1 - separated via dotted lines). The first encompasses models effective in textual responses but lacking in region-specific capabilities [6, 8, 22, 29, 51, 52, 61]. In contrast, among models that handle region inputs or offer visual grounding, three more categories emerge. The first of these incorporates external vision modules [31, 59], and the next relies exclusively on LMMs for region understanding [5, 35, 36, 44]. The last category combines specialized vision modules with LMMs, trained end-to-end for a comprehensive understanding of regions [21, 45, 57]. Our approach belongs to the
\
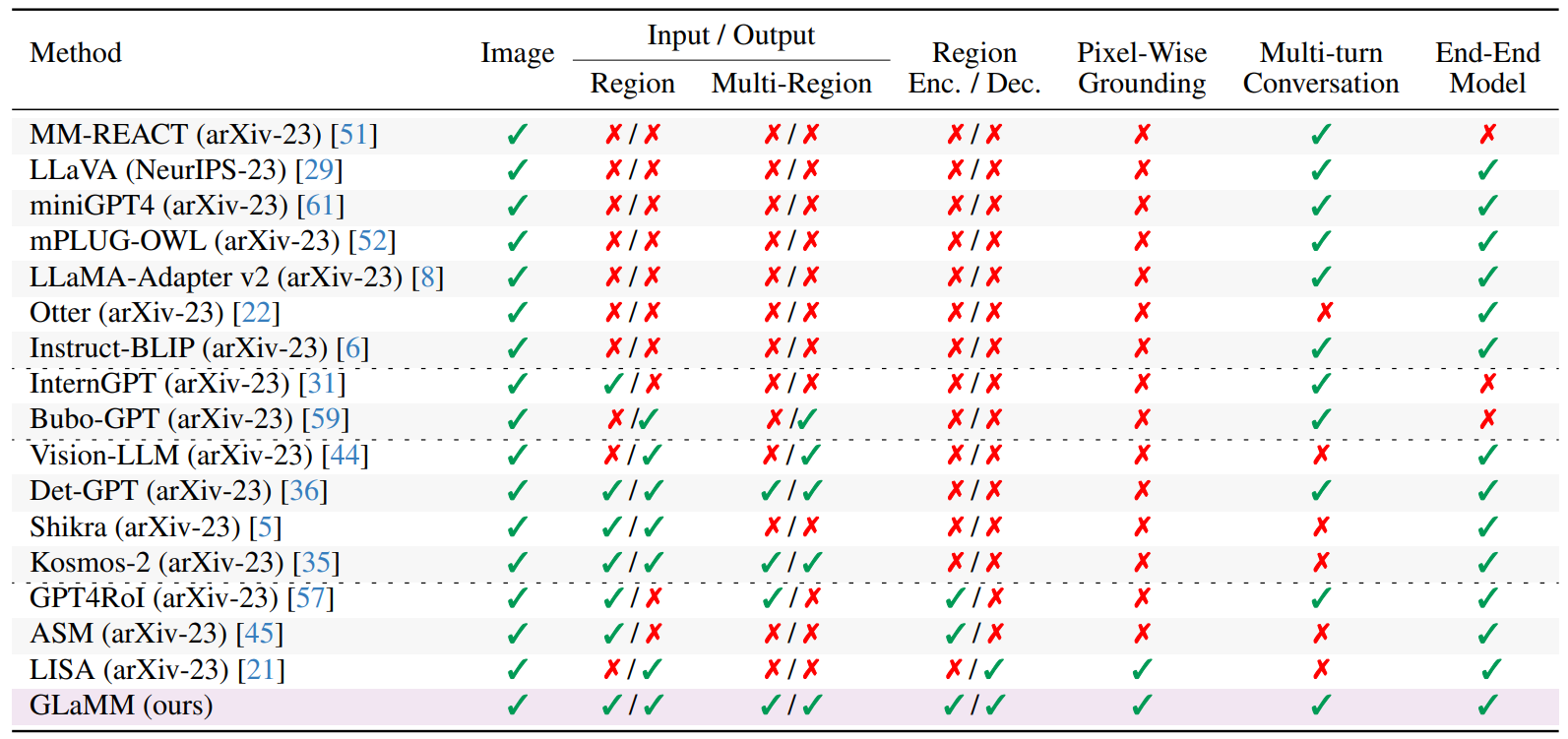
\ last category and distinctly offers pixel-level grounding together with multi-turn conversations and the flexibility to operate on both input images and specific regions. Further, we provide large-scale instance-level grounded visual understanding dataset that allows generalizability of GLaMM to multiple vision-language tasks.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\