and the distribution of digital products.
The Many Layers of Caching: All the Places Data Lives in Modern Systems
The speed of modern software systems depends on caching as it’s an essential performance-enhancing factor. The discussion about caching extends beyond Redis and Memcached implementations. Data caching occurs across multiple overlapping layers, which start at the browser level of end users and extend through database internals and search indexes. Each caching layer provides distinct advantages while dealing with its own set of tradeoffs. The proper understanding of these interactions becomes essential for developing applications that achieve both speed and scalability, and resilience.
A Multi-Layered View of CachingCaching is not a monolith; caching exists as a network of strategically deployed optimizations which serve different purposes and caching system functions through multiple optimization levels. We will examine each caching layer by providing concrete examples.
\
Browser Cache: The Browser Cache serves as the initial cache system in the hierarchy. The first loading of web pages enables browsers to store CSS, JS, and image files within their local storage system. For example, users who return to Gmail experience almost instant login screen loads because the application stores fonts and script files locally. Developers must handle headers including Cache-Control, ETag, and Last-Modified to achieve a proper balance between content freshness and performance speed.
\
CDN (Content Delivery Network): CDNs cache data at locations that are near the users’ geographical positions. The caching of HTML and images, together with API response,s typically takes place within CDNs. Through edge computing technology, dynamic content can now be processed and cached near users’ locations. For example, through the use of Akamai and CloudFront, Netflix streams video content efficiently to users spread across the entire world.
\
Application Memory Cache: The applications often use memory cache system libraries like Caffeine or Guava (Java) to store recently accessed objects in memory. For example, an e-commerce platforms use memory caching to store product catalogs because it reduces database access. The response times are much faster with microsecond speeds but the data disappears from memory when system restarts.
\
Distributed Cache: A distributed cache systems that includes Redis or Memcached maintains shared objects which different application services can access. The distributed cache systems offer fast performance with data sharing capabilities but requires continuous monitoring of time-to-live values and memory consumption. For example, Instagram uses Redis to cache session tokens and user metadata. The Redis features like sorted sets used as a storage mechanism for caching ranked feeds.
\
Database Buffer Pools and Indexes and Materialized Views: PostgreSQL maintains a shared buffer pool to store the pages which users have accessed recently. Queries that retrieve the same data multiple times access the buffer pool to avoid time consuming disk I/O operations. In general the application layer cannot detect this internal caching system.
Amazon Redshift materialized views precompute complex joins and aggregations such as top-selling products per region through hourly updates. The speed of dashboard and reporting queries becomes significantly faster after implementing this layer.
\
Search Engines: The implementation of result caching using systems like Elasticsearch for query facets and filters enhances the overall user experience. The technology works best when handling denormalized data which requires heavy reading operations. For example, Shopify enables fast product search across millions of items through its use of Elasticsearch.
\
Message Brokers: Systems like Kafka and RabbitMQ operate as message brokers instead of traditional caches although they provide temporary storage for events. For example, trip logs of Uber operate as events that enables real-time analytics and fraud detection before their eventual deletion.
\
Caching enables scalability beyond speed benefits. Here’s why:
Reduce Latency: The local and edge node caching of personalized playlists by Spotify enables users to access their content instantly.
Improve Throughput: Amazon uses cache storage for shopping cart and recommendation data to manage high traffic volumes.
Lower Operational Cost: Twitter uses timeline caching to reduce operational costs by minimizing the need for expensive distributed joins at read time
Enhance Resilience: The news site maintains user access to read-only articles through cached content when the database becomes unavailable.
\
The Hardest problem and difficulty of caching exists in determining when to remove or update stored data. Here are some common patterns:
- Time-to-Live (TTL): News APIs generally implement a 5-minute TTL to prevent outdated content from appearing.
- Write-through: Financial applications such as Stripe maintain database consistency through simultaneous Redis and Postgres updates.
- Write-behind: Analytics pipelines delay DB updates to reduce write amplification.
- The Cache-aside (Lazy Loading): This approach enables Netflix to obtain show metadata only when needed and store it for future requests.
- Pub/Sub Invalidation: Airbnb implements event-based invalidation to instantly remove outdated user reviews from their cache system.
\
Consistency ModelsCaching introduces trade-offs between consistency and performance. Here are some common consistency patterns:
- Strong Consistency: Banking applications like Chase implement strong consistency to maintain accurate account balance information.
- Eventual Consistency: Social feeds accept brief delays before showing new likes and comments because they operate with eventual consistency.
- Read-Your-Writes: Slack uses local cache updates to make your sent message visible right away.
\
Multi-Layer Cache Flow Architecture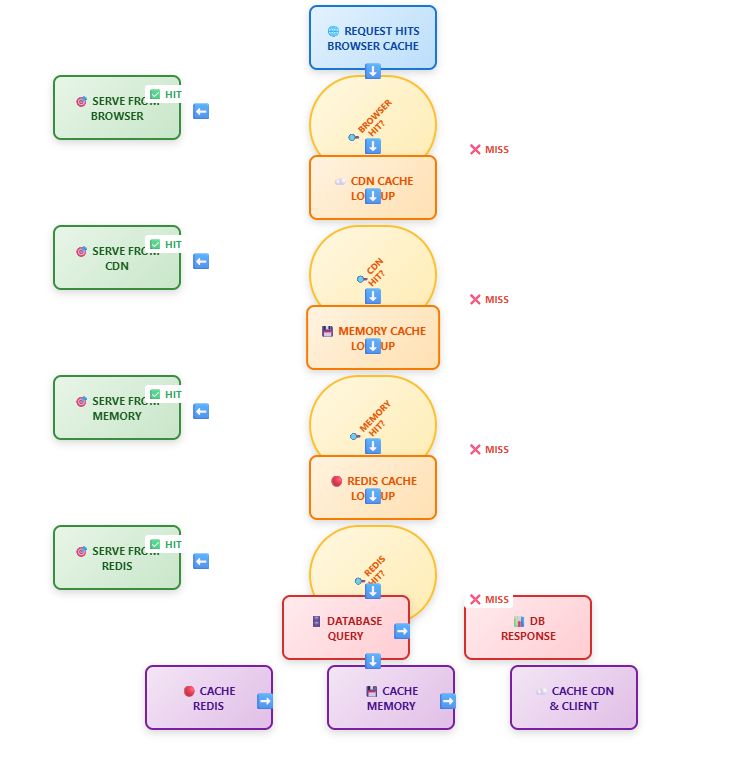
Cache Flow Summary:
Request Path: The request follows this path: Browser Cache → CDN Cache → Memory Cache → Redis Cache → Database Query.
Cache Misses: The system checks each cache level sequentially until it finds the requested content or it reaches the database query.
Database Response: The database executes the query and delivers new data when all cache levels fail to retrieve the information.
Cache Population: The response travels back through the entire cache hierarchy starting from Redis and ending at Browser.
Future Requests: Served from nearest available cache level to minimize database hits
Performance Goal: The performance goal of multi-tier caching aims to decrease both response times and database system load.
\
The implementation of complex cache strategies delivers major performance benefits but introduces additional system complexity. These five general failure modes include specific instances and their respective remedies:
\
Thundering Herd Example: The limited-time flash sale activated a massive user demand for the product page simultaneously. The simultaneous expiration of cached entries creates an overwhelming origin database load which results in system downtime.
Possible Solution: The solution implements two strategies to avoid this issue: First, add random time jitter to expiration times (TTL = 5±1 minutes) and second, implement request coalescing to delay filling the cache after a first cache miss until new content arrives.
\
Cache Penetration Example: Malicious bots create random or invalid product IDs which bypass cache mechanisms and attack the database directly. The database operates as a performance bottleneck due to the prolonged usage.
Possible Solution: Use a Bloom filter before the cache to efficiently eliminate keys that do not exist. Any key outside the Bloom filter will be discarded before it reaches the cache or database.
\
Hot Keys Example: When a major news story or viral hashtag generates sudden high traffic for one Redis key the resulting load causes a timeout in one cache shard.
Possible Solution: Use consistent hashing to distribute “hot” keys between multiple Redis instances. The system should use replicated cache tiers that direct user requests to less active replica nodes.
\
Stale Data Example: The e-commerce site's inventory count update after a purchase does not immediately invalidate the “stock” value in the cache which leads to customers seeing false “In Stock” indications for unavailable products.
Possible Solution: Publish cache-invalidation events via a message queue (e.g., Kafka) after every inventory change. Each app server subscribes to this system to immediately delete or modify cache entries containing affected data.
\
Version Mismatch Example: The deployment of a new API version results in JSON schema changes for user profiles yet cached entries from version 1 persist in their original format. Service deserialization errors occur because of this version mismatch.
Possible Solution: When you roll out new versions you should include version tags (e.g., v2:user:123) in cache keys to prevent format mixing between old and new versions. The system should wait for TTL expiration before retiring old versions.
\
Each cache layer should include backup fallback paths for operation.
Monitor cache performance through observability tools to track cache hit/miss ratios and latency and TTL behavior.
Bloom filters could be implemented to prevent cache misses when dealing with invalid keys.
Lazy-loading could be preferred unless your application needs strict consistency.
The combination of metrics and tracing enables cache issue diagnosis.
Your cache architecture should consist of three distinct layers which provide memory-based fast reads and Redis-based shared state and database-based durability.
\
The decision to implement caching exists on multiple levels rather than as a simple binary choice. The most effective systems use each cache layer to optimize particular tradeoffs between speed and cost and consistency and resilience. Understanding these multiple layers of caching and their interplay helps teams architect smarter, faster, and more dependable systems. Don’t just add a cache rather design one that matches your product's specific design and scale requirements.