and the distribution of digital products.
LLaVA-Phi: The Training We Put It Through
3. LLaVA-Phi and 3.1. Training
5. Conclusion, Limitation, and Future Works and References
3. LLaVA-PhiOur overall network architecture is similar to LLaVA-1.5. We use the pre-trained CLIP ViT-L/14 with a resolution of 336x336 as the visual encoder. A two-layer MLP is adopted to improve the connection of the visual encoder and LLM.
3.1. TrainingSupervised fine-tuning on Phi-2. The publicly released Phi-2 model has not undergone fine-tuning. Previous research indicates that even a small amount of high-quality data can significantly enhance performance in areas such as mathematics, language reasoning, and coding tasks. In light of this, we employed supervised fine-tuning to further train Phi-2 using a select set of premium data. This data was organized in the Vicuna format. For our Supervised Fine-Tuning (SFT) data, we utilized ShareGPT from an open-source platform. The training was conducted over two epochs, beginning with an initial learning rate of 3e-5, which was linearly decreased over time. Our findings suggest that while this step might be optional, applying SFT to Phi-2 does result in modest improvements across most benchmarks.
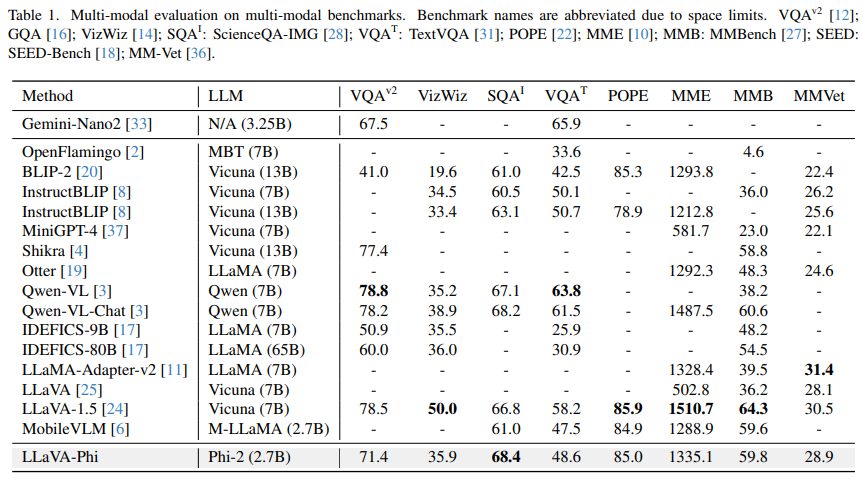

Training LLaVA-Phi. Our training approach follows the pipeline used for LLaVA1.5, consisting of a pretraining stage and a subsequent instruction tuning phase. Initially, we kept the vision encoder and Phi-2 static, focusing exclusively on training the efficient projector. This step is followed by a comprehensive fine-tuning of both the projector and the language model (LLM), aiming to enhance their capabilities in visual comprehension and language processing.
\ For pre-training, we utilize a filtered subset of the CC-595K dataset [24] over one epoch, applying an initial learning rate of 1e-3 and a batch size of 256. Then, we finetune the model on LLaVA-Instruct-150K dataset for 1 epoch at a learning rate of 2e-5 and a batch size of 256. We implement a weight decay of 0.1 and utilize the Adam optimizer, characterized by momentum parameters of 0.9 and 0.98, and an epsilon value of 1e-7. We fine-tune all parameters in LLM instead of using LoRA.
\ Computational Cost. Similar to LLaVA1.5, our training process is structured in two stages. For LLaVA-Phi, the pretraining phase takes 1.5 hours, followed by 8 hours dedicated to visual instruction tuning, utilizing 8 A100 GPUs. The integration of techniques such as LoRA [15] and QLoRA [9] has the potential to significantly reduce training time, a possibility we plan to explore in future work.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
:::info Authors:
(1) Yichen Zhu, Midea Group;
(2) Minjie Zhu, Midea Group and East China Normal University;
(3) Ning Liu, Midea Group;
(4) Zhicai Ou, Midea Group;
(5) Xiaofeng Mou, Midea Group.
:::
\