and the distribution of digital products.
Kasada Anti-Bot Bypass Techniques: Save Money with These Open-Source Solutions
Bypassing anti-bots is one of the major pain points a professional web scraper faces during their career. Luckily enough, the market offers several solutions for bypassing them, but delegating the heavy-duty work always comes with a price tag attached, which is not for every pocket.
\ As the saying goes, 'If you want something done right, do it yourself.' So, let’s continue the series of articles about bypassing well-known anti-bot protections with Open-Source tools.
\ After doing the same with Cloudflare, today is the turn of Kasada, the Australian anti-bot company. If you’re interested in learning more, you can watch a nice talk with Nick Rieniets, Kasada's CTO, on the TWSC YouTube channel about the anti-bot industry and its evolution.
\ So, let’s see which open-source tools we can use to bypass the Kasada anti-bot in 2025, keeping some dollars in our pockets.
\
Open Source tools for bypassing KasadaAs always, we need to choose a website on which to test our solutions. Today, it’s Canada Goose, the e-commerce site of the famous outerwear brand.
\ The easiest way to detect when a website is using Kasada is by asking it for Wappalyzer, which has a browser extension you can use while visiting a website to detect its tech stack.
\ As a double check, since the Wappalyzer data can be stale, you can visit the website with the network tab of the Developers Tools open (but first, tick the “preserve log” box).
\ If you notice that the website first returns a 429 error and then loads correctly, this is the typical behavior of a Kasada-protected website.
\

\ This is also confirmed by the presence of this access control header on the following calls: x-kpsdk-ct,x-kpsdk-r, and x-kpsdk-c and x-kpsdk-ct token.
\n 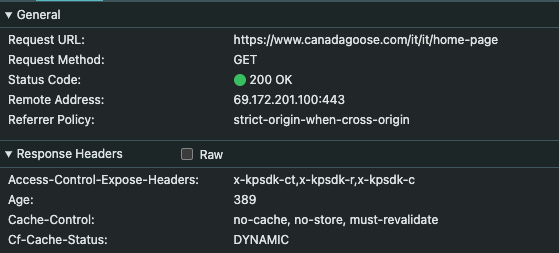
I often hear this from people trying to bypass an anti-bot solution: We need to generate a valid token to get clearance to scrape the website's data.
\ While it could be interesting to learn to reverse engineer a commercial solution like Kasada, this is not the best approach if you need data soon. It takes time, and you must restart after every change in the anti-bot software. Despite the difficulties, several repositories on GitHub are trying to do it.
\
\ My preferred approach, instead, is to create a human-like request that mixes with the actual website traffic and goes unnoticed by the crowd.
\ Of course, this approach is slower since it requires a browser automation tool, but it’s also more ethical than bombarding the target server with hundreds of requests per second.
\ In this article, we’ll see three different open-source tools that allow you to bypass Kasada using Playwright and a modified browser.
\
Standard Playwright ❌Before trying more undetected tools, let’s start with a simple script using a standard version of Playwright and Brave Browser.
from playwright.sync_api import sync_playwright import time CHROMIUM_ARGS= [ '--no-sandbox', '--disable-setuid-sandbox', '--no-first-run', '--disable-blink-features=AutomationControlled', '--start-maximized' ] with sync_playwright() as p: browser = p.chromium.launch_persistent_context(user_data_dir='./userdata/',channel='chrome',no_viewport=True,executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"]) all_pages = browser.pages page = all_pages[0] page.goto('https://www.canadagoose.com/', timeout=0) time.sleep(10) page.goto('https://www.canadagoose.com/it/it/shop/donna/capispalla/giacche-imbottite/shop-womens-puffers', timeout=0) time.sleep(10) browser.close()\ I often use Brave in these examples because it’s a browser that adds some noise to the WebGL fingerprint, even though it’s not as powerful as a real anti-detect browser.
\ The test miserably fails, as we get a blank screen for both URLs, another distinguishing mark of Kasada.
\
Patchright ✅A stealthier version of Playwright is Patchright, which modifies some of its default arguments and fixes well-known flaws that make it more detectable by an anti-bot.
\ The best part of the game?
\ You just need to change the imported package; the scraper is the same as the Playwright one. I just added the proxies and used the default browser installed with the library.
from patchright.sync_api import sync_playwright import time import os proxies = { 'server': 'http://ENDPOINT:PORT', 'username': 'USER', 'password': 'PWD' } CHROMIUM_ARGS= [ '--no-first-run', '--disable-blink-features=AutomationControlled', '--force-webrtc-ip-handling-policy' ] with sync_playwright() as p: browser = p.chromium.launch(headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"]) context = browser.new_context(proxy=proxies, ignore_https_errors=True, permissions=['geolocation']) page = context.new_page() page.goto('https://www.canadagoose.com/', timeout=0) time.sleep(10) page.goto('https://www.canadagoose.com/it/it/shop/donna/capispalla/giacche-imbottite/shop-womens-puffers', timeout=0) time.sleep(10) HTML_text = page.content() print(HTML_text) browser.close()\ Now, the scraper works like a charm.
\
Zendriver ✅Another package I tested is Zendriver (which is a fork of Nodriver, the successor of undetected-chromedriver). \n I chose it instead of Nodriver because it is updated more often, and I was curious to test it.
\ It uses the Chrome Developer Protocol to interact with the browser, rather than a webdriver, and Python Async API to speed up the crawling.
import asyncio import zendriver as zd import time proxies = { 'server': 'http://ENDPOINT:PORT', 'username': 'USER', 'password': 'PWD' } async def main(): async with await zd.start(browser_executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser', proxy=proxies) as browser: await browser.get('https://www.canadagoose.com/') time.sleep(10) await browser.get('https://www.canadagoose.com/it/it/shop/donna/capispalla/giacche-imbottite/shop-womens-puffers') time.sleep(10) await browser.stop() if __name__ == "__main__": asyncio.run(main())\ The small script can bypass Kasada and show us the pages without requiring us to set any particular options. Great discovery!
\
Camoufox ✅Last but not least, one of the most mentioned libraries on these pages is Camoufox.
\ It’s an open-source anti-detect browser run by Playwright. It adds important features, such as human-like mouse movement and the ability to forge real fingerprints.
\ In this case, we just forged a new fingerprint of a Windows machine but didn’t move the mouse around the page, but that was enough to load the requested pages correctly.
from camoufox.sync_api import Camoufox import time import os proxies = { 'server': 'http://ENDPOINT:PORT', 'username': 'USER', 'password': 'PWD' } with Camoufox(humanize=True,os="windows", geoip=True, proxy=proxies) as browser: page = browser.new_page() page.goto('https://www.canadagoose.com/', timeout=0) time.sleep(5) page.goto('https://www.canadagoose.com/it/it/shop/donna/capispalla/giacche-imbottite/shop-womens-puffers', timeout=0) time.sleep(5) HTML_text = page.content() print(HTML_text) browser.close()\
Final remarksThe open-source community is always amazing and creates such great tools that sometimes don’t get the right appreciation.
Camoufox is a great example of a product that is on the same level as a commercial one.
\ What’s the best open-source tool you use for scraping? Please write it in the comment section!
\
:::info The article is part of “The Lab” series by Pierluigi Vinciguerra. Check out his Substack page for more knowledge on Web Scraping.
:::
\