and the distribution of digital products.
Introducing ZeroShape's Baselines: The 5 State-of-the-Art Baselines We Considered
3. Method and 3.1. Architecture
3.2. Loss and 3.3. Implementation Details
4. Data Curation
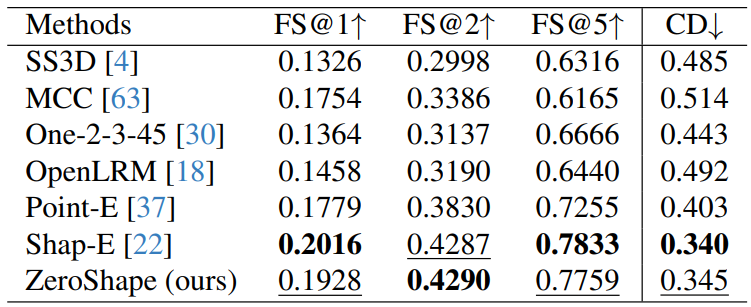
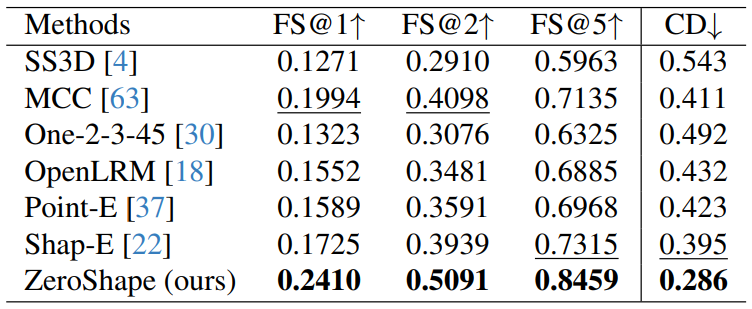
5. Experiments and 5.1. Metrics
5.3. Comparison to SOTA Methods
5.4. Qualitative Results and 5.5. Ablation Study
\ A. Additional Qualitative Comparison
B. Inference on AI-generated Images
5.2. BaselinesWe consider five state-of-the-art baselines for shape reconstruction, SS3D [4], MCC [63], Point-E [37], Shap-E [22], One-2-3-45 [30] and OpenLRM [17, 18].
\ SS3D learns implicit shape reconstruction by first pretraining on ShapeNet GT, and then finetuning on real-world single-view images. The finetuning is performed in a category specific way, and then a single unified model is distilled from all category-specific experts. We compare our model with their final distilled model.
\ MCC learns shell occupancy reconstruction using multiview estimated point clouds from CO3D [47]. Their model assumes known depth and intrinsics during inference. To evaluate their model on RGB images, we use the DPTestimated depth and fixed intrinsics as MCC’s input following their pipeline.
\ Point-E is a point cloud diffusion model that generates point clouds from text prompts or RGB images. They additionally train a separate model that converts point clouds into meshes. We compare our model with Point-E by combining their image-to-point and point-to-mesh models.
\ Shap-E is another diffusion model that learns conditioned shape generation from text or images. Different from PointE, Shap-E uses a latent diffusion setup and can directly generate implicit shapes. The final mesh reconstruction are extracted with marching cubes.
\ One-2-3-45 learns implicit shape reconstruction by breaking it down into a generative view synthesis step and a multiview-to-3D reconstruction step. The view synthesis is achieved with Zero-123 [31], a diffusion model that generates novel-view images conditioned on the original images and poses. Based on the synthesized multi-view images, a cost-volume-based module reconstructs the full 3D mesh of the object.
\ LRM is a concurrent work that learns to predict NeRF [36] from single images using transformer-based architecture. Since the authors have not released the code, we use the
\
\
\ code and weights from OpenLRM [5]. The mesh is extracted via Marching Cubes [32] from the triplane NeRF.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[5] https://github.com/3DTopia/OpenLRM
:::info Authors:
(1) Zixuan Huang, University of Illinois at Urbana-Champaign and both authors contributed equally to this work;
(2) Stefan Stojanov, Georgia Institute of Technology and both authors contributed equally to this work;
(3) Anh Thai, Georgia Institute of Technology;
(4) Varun Jampani, Stability AI;
(5) James M. Rehg, University of Illinois at Urbana-Champaign.
:::
\