and the distribution of digital products.
Impossible Cloud Network: Rethinking AI Data Infrastructure
- ICN offers a decentralized alternative designed for AI-scale workloads. Its modular architecture supports high throughput and regionally distributed storage across Web2 and Web3 environments.
- Storage is the overlooked bottleneck in AI infrastructure. Most solutions prioritize compute, but scalable and reliable storage is essential for reproducibility, throughput, and collaboration.
- Traditional cloud storage introduces critical limitations such as unpredictable costs, vendor lock-in, and opaque governance. These issues make it poorly suited for modern AI data workflows.
- ICN’s infrastructure combines ScalerNodes, HyperNodes, and the Satellite Network to ensure service reliability, performance verification, and low-latency data access across regions.
- With 1,000 ecosystem customers and $7 million in ecosystem ARR, ICN is already demonstrating meaningful adoption in the enterprise infrastructure market beyond purely Web3 applications.
The Impossible Cloud Network (ICN) is a decentralized infrastructure protocol that integrates compute, storage, and networking into a unified system. Designed to serve as an open alternative to centralized cloud providers, ICN enables users to deploy modular services without relying on any single point of control. Its architecture is structured around two core node types: HyperNodes, which monitor and coordinate protocol activity, and ScalerNodes, which provide the underlying hardware capacity. This system supports permissionless participation while allowing infrastructure users to tailor deployments to specific workload requirements. By distributing service provisioning across independent operators, ICN creates a more flexible and transparent backend for modern internet infrastructure.
The protocol is secured by ICN’s native token, ICNT. Network participants can stake tokens to HyperNodes and ScalerNodes, contributing to operational security and earning performance-based rewards. This token mechanism also allows access to network services, aligning incentives between infrastructure providers and users. ICN is currently oriented toward enterprise adoption, with its infrastructure already serving traditional cloud clients. As demand grows for configurable, open alternatives to proprietary cloud environments, ICN offers a composable architecture positioned to support both current and emerging use cases.
Website / X (Twitter) / Discord / LinkedIn
ICN Current UsageImpossible Cloud Network's ecosystem currently serves more than 1,000 enterprise customers and generates approximately $7 million in ecosystem annual recurring revenue, based on figures provided by the ICN team. The majority of users are traditional businesses that use ICN for storage workloads such as object storage, file sharing, and edge delivery. ICN's infrastructure is described as up to 80% more cost-efficient than services offered by providers such as AWS, particularly for high throughput or multi-region deployments.
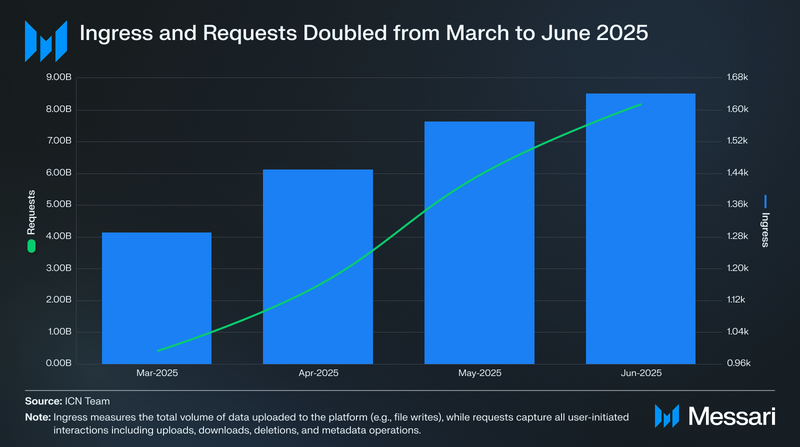
Operational usage data from March to June 2025 indicates increasing platform activity. Ingress, defined as the volume of data uploaded to the network, increased from 993 terabytes in March to 1,614 terabytes in June. Over the same period, customer requests, which include uploads, downloads, deletions, and metadata operations, rose from 4.1 billion to 8.5 billion. These metrics reflect growing adoption and sustained utilization of ICN’s storage infrastructure.
While usage today is primarily focused on conventional storage operations, the platform’s architecture is built to accommodate emerging workloads, including those related to AI infrastructure, where storage demand continues to expand.
 The Forgotten Half of AI Infrastructure: Storage
The Forgotten Half of AI Infrastructure: StorageIn discussions about AI infrastructure, compute dominates the narrative with new projects like Nosana, IO, and Akash. Whether in centralized environments or in emerging decentralized ecosystems, the primary focus tends to be access to high-performance GPUs, optimized training runtimes, and cost-efficient inference. While these components are critical, they represent only one part of the AI pipeline. Storage is equally foundational, yet frequently underemphasized, especially in decentralized infrastructure contexts where complete cloud functionality is still maturing.
AI development workflows generate, transform, and rely on large volumes of data, including everything from raw input datasets to final model outputs. Without scalable and performant storage, even the most powerful compute clusters are unable to maintain full throughput, reproducibility, or operational efficiency.
Typical AI storage requirements include:
- Raw and processed datasets: Training starts with high-volume datasets that must be stored both before and after preprocessing. This data is often split into shards for distributed training, requiring fast, parallel access across systems.
- Checkpointing and rollback: Intermediate model checkpoints are saved throughout training to allow resumption after interruption or to evaluate model performance at different stages.
- Final model artifacts: The trained model, including weights, configurations, and architecture definitions, must be stored for deployment, future tuning, or reproducibility.
- Logs and telemetry: Real-time diagnostics, validation metrics, and resource usage logs are stored to support debugging, tuning, and audit trails.
In practice, if the underlying storage infrastructure fails to deliver sufficient bandwidth, consistency, or cost-efficiency, these processes slow down or break. Compute nodes idle, training pipelines are fragmented, and teams face operational inefficiencies. These risks are magnified in collaborative or multi-tenant environments, where reproducibility and access consistency are essential.
Despite its importance, most decentralized infrastructure projects prioritize compute over storage. Storage is rarely treated as a first-class component, and few protocols offer end-to-end tooling for dataset management, versioning, synchronization, and archival. As a result, decentralized AI projects often depend on centralized storage providers, creating technical and governance inconsistencies.
There is a structural gap in the ecosystem: a need for storage systems that support AI-scale workloads and integrate cleanly with both Web2 and Web3 workflows. The following section examines why existing centralized solutions are not sufficient to fill this gap.
Why Traditional Cloud Storage Falls ShortTraditional cloud providers such as Amazon Web Services, Google Cloud, and Microsoft Azure offer mature and highly integrated storage services. Amazon S3, in particular, is widely adopted for machine learning workloads and is often the default storage backend for AI teams operating at scale. These platforms provide global availability, API access, and built-in support for streaming, archiving, and data lake formation.
However, this dominance introduces structural drawbacks that impact both cost and flexibility. Several limitations make these providers poorly suited for the next generation of AI development, especially for teams seeking open, composable, or decentralized infrastructure.
Key limitations include:
- High and unpredictable costs: While initial pricing may appear affordable, usage-based billing models introduce volatility. Costs rise sharply with increased Input and Output, frequent API calls, or cross-region data access. This challenge is exacerbated by the structure of the cloud market itself, where a small number of dominant providers have the ability to set prices with limited competition. Several companies have publicly cited the financial burden of cloud dependence, including Basecamp, which projected seven million dollars in savings by moving off the cloud, and others highlighted in broader industry critiques, such as a16z’s analysis of long-term cloud costs.
- Vendor lock-in: Centralized clouds use proprietary APIs and storage formats that complicate data migration. Integrations are often optimized for their own internal tooling, limiting portability and interoperability with external systems.
- Single points of failure: Centralized control over infrastructure introduces the risk of downtime, service throttling, or unplanned disruptions. These risks impact time-sensitive training jobs and collaborative research workflows.
- Opaque ownership and limited composability: Data access, permissions, and retention policies are managed through internal interfaces. These abstractions reduce transparency and limit visibility for audit, compliance, or external orchestration.
These limitations are problematic not only for decentralized or Web3-native projects. Startups and small Web2 companies, especially those pursuing edge AI, multi-cloud deployments, or cost control, also face constraints under the traditional cloud model.
This is where an alternative storage solution like the Impossible Cloud Network can position itself. ICN is not only a decentralized infrastructure protocol, but it is also building a complete alternative cloud suite. Its architecture supports AI-scale storage operations and offers deployment paths compatible with both enterprise and permissionless environments.
By serving as a backend for model data, checkpoints, telemetry, and archive management, ICN fills a growing market gap. It does not compete as a narrow storage plugin or single-purpose project. Instead, it introduces a modular and extensible platform that can support full-stack AI training and inference workflows.
ICN’s Architecture for Scalable AI Data InfrastructureThe Impossible Cloud Network offers a decentralized infrastructure model that includes both compute and storage provisioning. Its architecture is designed to support large-scale data operations without relying on centralized control. The system is composed of three main node types, each serving a specialized role:
- HyperNodes are responsible for orchestrating workloads and maintaining the coordination layer across the network. They manage service delivery and ensure availability across regions.
- ScalerNodes provide compute and storage capacity at scale. These nodes are used to fulfill high-volume tasks, such as dataset delivery, model checkpointing, and telemetry archiving. ScalerNodes form the core of the network’s performance layer.
- Satellite Network provides distributed edge presence and relay functionality. They extend the reach of the network and allow for low-latency operations in geographically diverse regions.
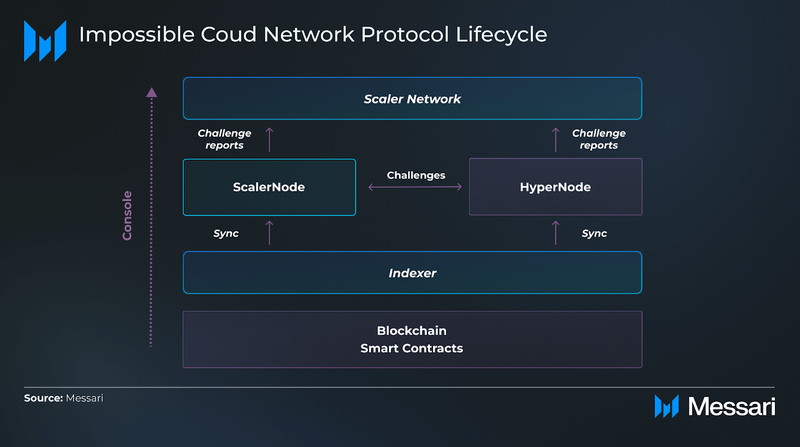
Hardware providers contribute resources to the ICN network by operating nodes that participate in the Scaler Network, which forms the core service layer. Both ScalerNodes and HyperNodes are required within this network to coordinate availability, submit service reports, and interact with the Satellite Network. These components work together to ensure storage integrity and enforce service-level expectations. Reports are stored offchain via the Satellite Network for a defined period before being securely deleted. Contributors are rewarded through a token-based system tied to verifiable performance metrics such as uptime, throughput, and service consistency.
Infrastructure users can configure their storage deployments by selecting parameters that match workload requirements. These parameters may include:
- Required storage throughput and volume
- Redundancy and replication policies
- Preferred latency zones for geographic proximity
- Lifecycle policies for retention, archival, and deletion
This level of configurability allows developers and enterprise users to tailor deployments for specific workflows without depending on vendor-specific implementations.
ICN’s service design targets performance consistency at the level of traditional hyperscale providers while maintaining a decentralized control plane. Rather than centralizing pricing, service discovery, and access permissions, ICN distributes these functions through a protocol-governed marketplace. This structure reduces pricing pressure from single providers and enables more efficient resource allocation.
The result is a storage system that supports large-scale data workflows, including those associated with AI datasets, collaborative pipelines, and dynamic workload environments. It also provides visibility into data operations, cost structures, and system behavior; features that are often abstracted in centralized cloud systems.
Applications of ICN in AI Data WorkflowsICN can be integrated into artificial intelligence pipelines as a backend for data-intensive infrastructure. These workflows span a wide range of activities, including model development, distributed processing, dataset versioning, and long-term data management. By operating as a decentralized storage layer, ICN addresses several pain points faced by both centralized and decentralized teams managing large-scale AI data environments.
Relevant applications include:
- Dataset storage: ICN supports the storage of multi-terabyte datasets used to train language models, computer vision systems, speech processing pipelines, and multimodal agents. These datasets can be sharded, versioned, and accessed concurrently across nodes.
- Checkpoint storage: During distributed model development, intermediate model checkpoints are saved and loaded repeatedly. ICN provides consistent access to these files across nodes and geographies, reducing delay and increasing fault tolerance.
- Model registry hosting: Research environments that require public or version-controlled access to model artifacts can use ICN to host these assets with built-in support for redundancy and availability. This supports reproducible workflows and collaborative experiments.
- Edge coordination and geographic distribution: AI systems that operate at the edge, including decentralized inference agents and federated learning setups, require data infrastructure that spans multiple regions. ICN’s node architecture supports regional access and coordination without relying on a central provider.
- Agent-based AI architectures: Autonomous AI agents operating across distributed environments require synchronized access to shared memory, cached datasets, and updated checkpoints. ICN provides the backend necessary for these agents to coordinate tasks without depending on a centralized data store.
By combining configurable infrastructure templates with protocol-level governance, ICN provides a data storage platform that supports a broad spectrum of deployment models. This includes enterprise-scale systems, research institutions, and open collaborative networks focused on distributed machine learning and autonomous systems.
ConclusionAI data infrastructure is one of several emerging use cases that require more than just scalable compute. As model complexity increases and workloads become distributed, storage often becomes the limiting factor. Without fast, reliable, and accessible storage, AI pipelines face inefficiencies in training, collaboration, and reproducibility.
ICN addresses these challenges with a decentralized architecture that supports configurable storage deployments across both Web2 and Web3 environments. Its infrastructure includes verifiable performance guarantees, modular service templates, and a marketplace-based incentive model for hardware providers. This allows ICN to deliver high-throughput, fault-tolerant storage without reliance on centralized control.