and the distribution of digital products.
How Logical Clocks Keep Distributed Systems in Sync
\n  Photo by Ales Krivec on Unsplash
Photo by Ales Krivec on Unsplash
\
Background Context - The need for logical clocksIn the intricate world of distributed systems, synchronizing time and maintaining consistency is a formidable challenge. As different distributed systems communicate with each other, there is a need to maintain order across events - as they occur - to guarantee consistency.
\ For example, consider a distributed chat application designed for real-time communication among users. If one user, Bob, sends a message to another user, Alice, it is crucial that both parties observe the messages in the same order. Discrepancies in message ordering can lead to confusion and misinterpretation. Imagine a scenario where Alice's response—"I am doing great"—appears before Bob's initial greeting—"Hey, what's up?". Such an anomaly highlights the essential need for mechanisms that ensure consistent event ordering across distributed systems.
\ To fix event ordering and consistency issues in Distributed systems - we can consider using a Global Physical clock. Physical clocks, despite their ubiquity in individual systems, fall short in distributed environments due to the impossibility of perfectly synchronizing time across multiple machines. This is because of factors like - clock drift, network latency, and varying processing speeds lead to discrepancies in timekeeping - which can add up over time. These inconsistencies make it unreliable to use physical timestamps for ordering events globally in a distributed system.
\ Logical clocks emerge as a solution by providing a method to order events based on causality rather than physical time, ensuring consistency and coordination without relying on synchronized clocks. Leslie Lamport's logical clock revolutionized this space by introducing a method to order events causally[1]. This article goes deep into Lamport's logical clock, explores the nuances between causal and total message ordering, and examines their profound impact on distributed systems.
\
Lamport's Logical Clock - Orchestrating Event Ordering Without TimeIn 1978, Leslie Lamport proposed the concept of logical clocks to address the absence of a global time reference in distributed systems[1]. Logical clocks don't measure physical time; instead, they provide a way to capture the sequence of events and infer causal relationships.
The Happens-Before RelationAt the heart of Lamport's logical clock is the happens-before relation, denoted as →. This relation defines a partial ordering of events:
- Local Ordering: If two events occur in the same process, the one that occurs first happens-before the one that follows.
- Message Passing: If an event a is the sending of a message by one process, and event b is the receipt of that message by another process, then a → b.
- Transitivity: If a → b and b → c, then a → c.
\ This relation helps establish a causal link between events across distributed processes.
Implementing Logical ClocksEach process maintains a logical clock counter[1]:
- Event Execution: Before a process executes an event, it increments its counter.
- Message Sending: When sending a message, the process includes its updated counter value.
- Message Receiving: Upon receiving a message, the process updates its counter to the maximum of its own value and the received value, then increments it.
\ This mechanism ensures that if event a causally affects event b, then the timestamp of a is less than that of b. However, the converse isn't necessarily true due to the possibility of concurrent events.
\ Let’s take a look at basic pseudo-code and below diagram[15] to understand above steps a bit further-
\
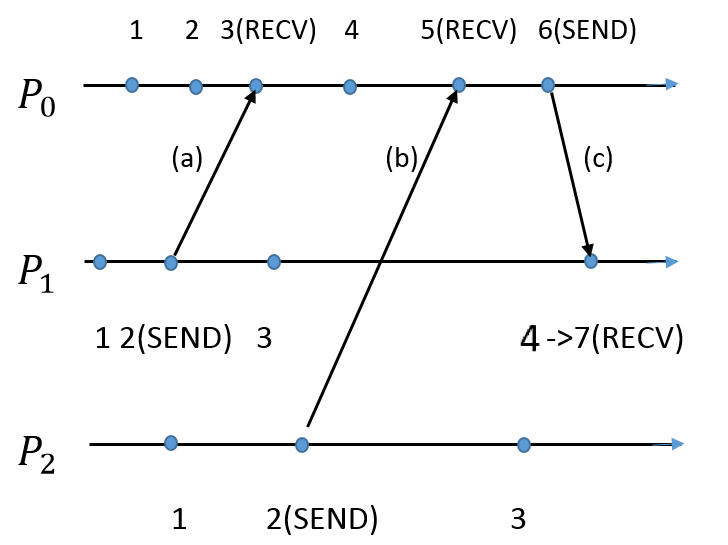
Image reference[15] - Link
\
Pseudo-code for send() algorithm # event is known time = time + 1; # event happens send(message, time);\
Pseudo-code for receive() algorithm (message, timestamp) = receive(); time = max(timestamp, time) + 1;\ As we can see above, process P1 receives message (c) from process P0. P1’s own ‘logical time’ is 4, but since the ‘timestamp’ included from P0 is 6, it chooses the max between the two - max (4,6) = 6. Then, it adds 1 to the max value, and resets its own ‘logical clock’ to max (4, 6) + 1 = 7. This example shows how the order of “happens before” relationship between P0 and P1 is maintained using Lamport’s logical clock.
\ Now, let’s look at different ways (total v/s causal) of establishing order of events in distributed systems, leveraging logical clocks.
Causal Message Ordering - Preserving the Fabric of CausalityCausal message ordering ensures that messages are delivered in a manner that respects the causal relationships among events[2] in a distributed system.
Achieving Causal OrderingImplementing causal ordering requires mechanisms that preserve the causality of events without enforcing a total order. Common approaches include:
- Piggybacking Dependencies: Processes include information about previously sent or received messages when transmitting new messages. This helps recipients reconstruct the causal history and deliver messages in the correct order.
- Causal Broadcast Protocols: These protocols enforce that a message is not delivered to the application layer until all causally preceding messages have been delivered. This may involve holding back messages until their dependencies are met.
- Dependency Tracking: Systems maintain a record of message dependencies, ensuring that messages are processed only after all messages they depend on have been processed.
Implementing causal ordering introduces several challenges:
- Overhead: Additional metadata is required to track dependencies, increasing the size of messages and the complexity of the system.
- Latency: Messages might need to be delayed until all causally prior messages are received, potentially impacting performance.
- Complexity: Designing protocols that efficiently handle causal ordering without introducing bottlenecks can be complex.
Causal ordering is critical in applications where the sequence of operations affects system correctness[3]:
- Collaborative Editing: Ensuring updates are applied in a causally consistent manner prevents conflicts and maintains a coherent state across all users.
- Distributed Databases: Maintaining causal consistency helps in conflict resolution during data replication, ensuring that causally related updates are applied in the correct order.
\
Total Message Ordering - Establishing a Global SequenceIn contrast to causal ordering, total message ordering enforces a global sequence on all events, ensuring that every process observes messages in the same order, regardless of causal relationships[4].
Achieving Total OrderingImplementing total ordering requires coordination mechanisms[4]:
- Sequencer-Based Approach: A central sequencer assigns sequence numbers to messages, dictating the delivery order.
- Distributed Agreement Protocols: Algorithms like Paxos[5] or Raft[6] enable processes to agree on a message order without a central coordinator.
Total ordering provides strong consistency guarantees but introduces challenges[4]:
Latency: Additional coordination increases message delivery times.
Scalability: Centralized sequencers or extensive consensus protocols can become bottlenecks in large systems.
Fault Tolerance: The system must handle sequencer failures without violating ordering guarantees.
\
As we can see now, understanding the implications of message ordering is pivotal for designing robust distributed systems.
Consistency Models shaped by Ordering- Causal Consistency: Operations that are causally related must be seen in the same order by all processes. This model is weaker than sequential consistency but provides a good balance between consistency and performance[3].
- Sequential Consistency: All processes see all operations (whether causally related or not) in the same order. This requires total ordering and is stricter, often impacting system performance[7].
- Application Requirements: Not all applications require total ordering. Understanding the specific needs allows for optimized system design[8].
- Hybrid Approaches: Some systems use causal ordering for most operations and total ordering for critical sections, balancing consistency and efficiency[9].
- Eventual Consistency: In systems where immediate consistency isn't critical, causal ordering aids in reconciling states over time without the overhead of total ordering[10].
Following are a few real-life examples where message/event ordering and logical clocks play a foundational role-
\
Distributed File Systems: Systems like Google File System (GFS)[11] and Hadoop Distributed File System (HDFS)[12] make trade-offs between ordering guarantees and throughput.
Messaging Systems: Apache Kafka[13] provides configurable ordering guarantees, allowing applications to choose between performance and consistency.
Blockchain Technologies: Consensus algorithms ensure total ordering of transactions, which is essential for the integrity of the Bitcoin ledger[14].
\
Lamport's logical clock and the concepts of causal and total message ordering are foundational in distributed computing. They address the core challenge of coordinating processes without a shared temporal reference, enabling systems to maintain consistency and coherence.
By leveraging these concepts:
Developers can design systems that meet the specific consistency and performance needs of their applications.
Researchers continue to explore optimized algorithms that reduce the overhead of ordering while maintaining necessary guarantees.
Industry benefits from distributed systems that are both robust and efficient, powering everything from cloud services to blockchain networks.
\
In the ever-evolving landscape of distributed systems, understanding and applying the principles of event ordering is essential. It allows us to build systems that are not only functionally correct but also performant and scalable, meeting the demands of today's interconnected world. By embracing the temporal dynamics outlined by Lamport and further refined through causal and total ordering, we can navigate the complexities of distributed systems, ensuring they operate seamlessly even as they scale across the globe.
\
References- Lamport, L. (1978). Time, Clocks, and the Ordering of Events in a Distributed System. Communications of the ACM, 21(7), 558–565.
- Birman, K. P., & Joseph, T. A. (1987). Reliable communication in the presence of failures. ACM Transactions on Computer Systems, 5(1), 47–76.
- Ahamad, M., Neiger, G., Burns, J. E., Kohli, P. W., & Hutto, P. W. (1995). Causal memory: Definitions, implementation, and programming. Distributed Computing, 9(1), 37–49.
- Défago, X., Schiper, A., & Urbán, P. (2004). Total order broadcast and multicast algorithms: Taxonomy and survey. ACM Computing Surveys, 36(4), 372–421.
- Lamport, L. (1998). The part-time parliament. ACM Transactions on Computer Systems, 16(2), 133–169.
- Ongaro, D., & Ousterhout, J. (2014). In search of an understandable consensus algorithm. In 2014 USENIX Annual Technical Conference (pp. 305–319).
- Lamport, L. (1979). How to make a multiprocessor computer that correctly executes multiprocess programs. IEEE Transactions on Computers, 28(9), 690–691.
- Tanenbaum, A. S., & van Steen, M. (2007). Distributed Systems: Principles and Paradigms. Prentice Hall.
- Chandy, K. M., & Lamport, L. (1985). Distributed snapshots: Determining global states of distributed systems. ACM Transactions on Computer Systems, 3(1), 63–75.
- Vogels, W. (2009). Eventually consistent. Communications of the ACM, 52(1), 40–44.
- Ghemawat, S., Gobioff, H., & Leung, S.-T. (2003). The Google file system. In Proceedings of the 19th ACM Symposium on Operating Systems Principles (pp. 29–43).
- Shvachko, K., Kuang, H., Radia, S., & Chansler, R. (2010). The Hadoop distributed file system. In 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST) (pp. 1–10).
- Kreps, J., Narkhede, N., & Rao, J. (2011). Kafka: A distributed messaging system for log processing. In Proceedings of the NetDB (pp. 1–7).
- Nakamoto, S. (2008). Bitcoin: A Peer-to-Peer Electronic Cash System. Retrieved from https://bitcoin.org/bitcoin.pdf
- Tong, Zhou & Pakin, Scott & Lang, Michael & Yuan, Xin. (2018). Fast classification of MPI applications using Lamport’s logical clocks. Journal of Parallel and Distributed Computing. 120. 10.1016/j.jpdc.2018.05.005.
\