and the distribution of digital products.
How IBIS Handles Model Licenses, Datasets, and Authorized Models
VII. Conclusion and References
VI. EVALUATION A. Experimental SetupOur proof-of-concept IBIS implementation was deployed on a private Canton blockchain comprising three nodes. All nodes were hosted on the same AWS EC2 t2.xlarge instance with four virtual CPUs and 16GB of RAM. While Daml provides a range of options for data storage, PostgresSQL, running within Docker containers, is chosen as the data storage to persist node data. Our source code of the performance test is available[6].
\ Our evaluation mainly focuses on three operations involving graph traversals: fetching model licenses using getModelLicenses, model datasets using getModelDatasets, and authorized models using getModelsByLicense. The former two operations pertain to copyright management, while the latter concerns data provenance. To enhance the accuracy of performance testing, for every parameter configuration, the operation of getModelLicenses is executed ten times on ten randomly chosen models, with the average execution time and standard deviation calculated thereafter. Similarly, getModelDatasets undergoes execution on ten randomly selected models. As for getModelsByLicense, the operation is performed on ten randomly chosen licenses, with the resultant average execution time and standard deviation recorded.
B. Experimental ParametersIn real-world scenarios, the framework hosts data, including dataset metadata, license, and model metadata, contributed by various AOs and COs. These stakeholders engage in executing functional operations (outlined in Table II) to realize data provenance and copyright management. Ensuring the efficiency of operations, particularly those involving complex graph traversals, is paramount in this context. The experimental environment is set up the following parameters:
\ • The framework accommodates N AOs, where each scrape D datasets for model training. Therefore, the framework host a total of N × D datasets.
\ • Each AO acquired L licenses from various COs. Each dataset scraped by that AO is assigned one of the L licenses. For test purposes, the assignment is done randomly. Consequently, the total number of licenses hosted in the framework amounts to N × L. In addition, some fraction of licenses may be associated with multiple datasets, while other licenses without datasets. This aligns well with real-world usage scenarios because AOs may collect licenses before scraping the corresponding dataset.
\
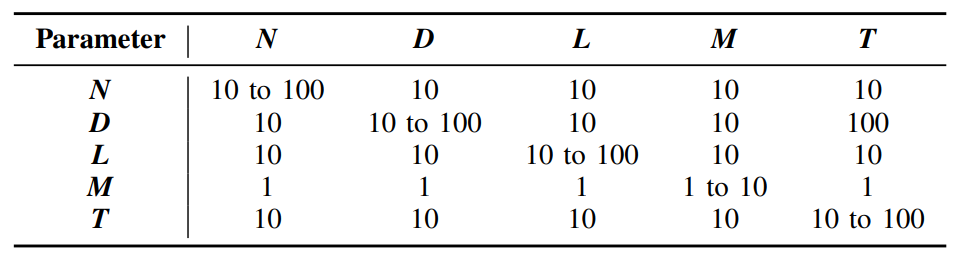
\ • To mirror the model retraining process in the real world, the experiment assumes each AO retrained a model M−1 times and obtained a chain of M models. Consequently, the total number of models hosted in the framework amounts to N × M.
\ • Each model is trained on T datasets. For the testing purpose, those datasets are randomly picked from AO’s D datasets.
\ Note that there are five parameters during the experimental setup, namely N, D, L, M, and T. The system workload can be scaled up by increasing these parameters. In our evaluation, adhering to the control variates method, we measure the performance by varying each parameter individually while keeping the other parameters fixed. Table IV lists the values of the four parameters that remain fixed while adjusting the remaining parameter.
C. Evaluation of Fetching Model LicensesFig.8 illustrates the variations in execution time corresponding to incremental adjustments in each of the five parameters. As explained above, each data point represents the average execution time of getModelLicenses in ten executions, with error bars indicating the standard deviation. The result reveals that the execution time of getModelLicenses increases linearly with the augmentation of the number of models in the model chain M and number of training datasets of each model T. This correlation is logical, as elevating M augments the model training graph depth (see Fig.6), whereas elevating T expands its breadth.
\ The outcomes also indicate that the values of the number of scraped datasets per model owner D, model owners N, and licenses per model owner L exert no discernible influence on the performance of getModelLicenses. In theory, these three parameters do not impact the graph size; hence they have negligible effect on performance. However, theoretically, they could affect performance as querying a record using its identifier might slow down with a greater number of records. However, our optimization efforts, such as designating data, model, and license identifiers as the primary key of a record (cf. Sec.V-B), mitigate any observable impact of increased record numbers. The results demonstrate that the performance of getModelLicenses operation remains consistent regardless of the number of model owners in the system, datasets they scrape, or licenses they acquire, thereby affirming the scalability of the operation.
D. Evaluation of Fetching Model DatasetsFig.9 illustrates the variations in execution time corresponding to incremental adjustments in each of the five parameters. The operation can be viewed as a sub-operation of getModelLicenses that traverses the entire graph from a model to licenses. In contrast, the getModelDatasets operation stops the traversal early at the level of datasets. Therefore, the two operations share many common characteristics in terms of performance. The results highlight a notable correlation between the execution time and the number of models in the model chain M and training datasets of each model T. As M increases, indicating a deeper model-data graph structure, and T expands, indicating a broader breadth of the graph, the execution time rises linearly. This relationship stems from the increased computational complexity associated with traversing deeper and wider graphs.
\ Moreover, experiments show that variations in the number of scraped datasets per model owner D, model owners N, and licenses per model owner L do not significantly impact performance. This observation aligns with similar findings for getModelLicenses and underscores the operation’s scalability. The evaluated operation consistently maintains its performance regardless of the number of model owners in the system, datasets they scrape, or licenses they acquire, reflecting the scalability and efficiency in managing data provenance.
E. Evaluation of Fetching Authorized ModelsFig.10 illustrates the variations in execution time corresponding to incremental adjustments in each of the five parameters. The result exhibits an overall increasing trend in execution time with the increasing number of models in the model chain M. This observation is intuitive, as the operation necessitates traversing more models as the chain of related model lengthens. However, the average performance displays oscillations as M increases, accompanied by high standard deviations for each data point. These fluctuations and high standard deviations stem from the presence of redundancy of the licenses and datasets.
\ In real-world scenarios, redundancy often occurs because licenses may be acquired in advance, before the corresponding data is scraped, or datasets may be stored without immediate model training. Our experimental setup reflects these real-world complexities, resulting in some executions being faster due to the operation encountering redundant licenses or datasets. Consequently, the graph traversal terminates early in these instances, leading to variations in execution times. This phenomenon also explains the observed high standard deviations in the other charts.
\ The results also indicate that the execution time remains constant as the number of training datasets per model T increases. This is because increasing T does not impact the size of the graph starting from a particular license. However, the execution time linearly increases with the increasing number of scraped datasets per model owner D. This phenomenon occurs because as more datasets become associated with a license,
\

\

\

\ the graph starting from that license experiences an increase in breadth, consequently prolonging the traversal time.
\ Additionally, the performance remains consistent with the increasing number of model owners N and licenses per model owner L, mirroring the behavior observed in the previous operations. This consistency affirms the scalability of IBIS to accommodate a large number of users and licenses.
F. Discussions Between Evaluated OperationsIt is evident that the execution time of fetching model datasets using getModelDatasets operation is approximately half that of fetching model licenses getModelLicenses using. This phenomenon arises because fetching model datasets can be considered a sub-operation of fetching model licenses, which undertakes partial tasks compared to all. While fetching a license traverses the entire graph from a model to licenses, fetching a dataset terminates the traversal early at the dataset level. Moreover, because a training dataset consistently corresponds to a single license, traversing from datasets to licenses involves the same number of edges as traversing from models to datasets.
\ Moreover, the performance of fetching authorized model using getModelsByLicense operation displays distinct performance characteristics compared to the other two operations, particularly evidenced by its high standard deviations. This variance arises due to the different graph traversal directions. Additionally, the redundancy of datasets and licenses is only encountered in the traversal direction of the operation. Equivalently, while a dataset may not necessarily correspond to any model, a model invariably corresponds to some datasets. Similarly, while a license may not correspond to any datasets, a training dataset always corresponds to a license. Consequently, the graph traversal performance in the direction of getModelsByLicense exhibits greater statistical variability.
\ Overall, depending on the operation, the execution time can increase linearly with the number of scraped datasets per model owner D, training datasets per model T, or models in a model chain M. Meanwhile, the number of model owners N and licenses per model owner L do not significantly affect the execution time. This is consistent with our performance analysis in Table II and validates scalability and feasibility.
\
:::info Authors:
(1) Yilin Sai, CSIRO Data61 and The University of New South Wales, Sydney, Australia;
(2) Qin Wang, CSIRO Data61 and The University of New South Wales, Sydney, Australia;
(3) Guangsheng Yu, CSIRO Data61;
(4) H.M.N. Dilum Bandara, CSIRO Data61 and The University of New South Wales, Sydney, Australia;
(5) Shiping Chen, CSIRO Data61 and The University of New South Wales, Sydney, Australia.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[6] Testing script: https://github.com/yilin-sai/ai-copyright-framework