and the distribution of digital products.
How Effective is vLLM When a Prefix Is Thrown Into the Mix?
2 Background and 2.1 Transformer-Based Large Language Models
2.2 LLM Service & Autoregressive Generation
2.3 Batching Techniques for LLMs
3 Memory Challenges in LLM Serving
3.1 Memory Management in Existing Systems
4 Method and 4.1 PagedAttention
4.3 Decoding with PagedAttention and vLLM
4.4 Application to Other Decoding Scenarios
6 Evaluation and 6.1 Experimental Setup
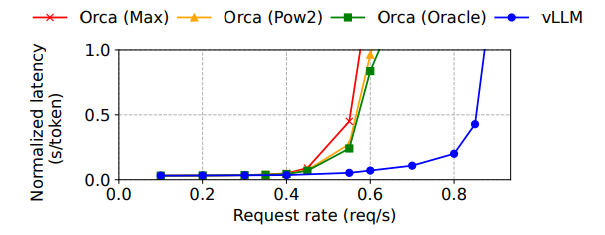
6.3 Parallel Sampling and Beam Search
10 Conclusion, Acknowledgement and References
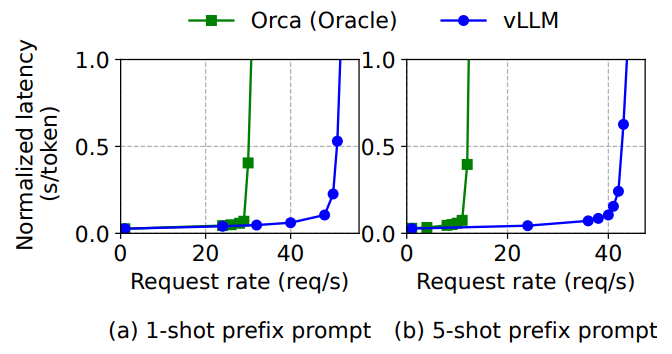
6.4 Shared prefixWe explore the effectiveness of vLLM for the case a prefix is shared among different input prompts, as illustrated in
\
\
\ Fig. 10. For the model, we use LLaMA-13B [52], which is multilingual. For the workload, we use the WMT16 [4] Englishto-German translation dataset and synthesize two prefixes that include an instruction and a few translation examples. The first prefix includes a single example (i.e., one-shot) while the other prefix includes 5 examples (i.e., few-shot). As shown in Fig. 16 (a), vLLM achieves 1.67× higher throughput than Orca (Oracle) when the one-shot prefix is shared. Furthermore, when more examples are shared (Fig. 16 (b)), vLLM achieves 3.58× higher throughput than Orca (Oracle).
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
:::info Authors:
(1) Woosuk Kwon, UC Berkeley with Equal contribution;
(2) Zhuohan Li, UC Berkeley with Equal contribution;
(3) Siyuan Zhuang, UC Berkeley;
(4) Ying Sheng, UC Berkeley and Stanford University;
(5) Lianmin Zheng, UC Berkeley;
(6) Cody Hao Yu, Independent Researcher;
(7) Cody Hao Yu, Independent Researcher;
(8) Joseph E. Gonzalez, UC Berkeley;
(9) Hao Zhang, UC San Diego;
(10) Ion Stoica, UC Berkeley.
:::
\