and the distribution of digital products.
How Effective Are Standard Regularization and Replay Methods for Class-Incremental Learning?
:::info Authors:
(1) Sebastian Dziadzio, University of Tübingen ([email protected]);
(2) Çagatay Yıldız, University of Tübingen;
(3) Gido M. van de Ven, KU Leuven;
(4) Tomasz Trzcinski, IDEAS NCBR, Warsaw University of Technology, Tooploox;
(5) Tinne Tuytelaars, KU Leuven;
(6) Matthias Bethge, University of Tübingen.
:::
Table of Links2. Two problems with the current approach to class-incremental continual learning
3. Methods and 3.1. Infinite dSprites
4. Related work
4.1. Continual learning and 4.2. Benchmarking continual learning
5.1. Regularization methods and 5.2. Replay-based methods
5.4. One-shot generalization and 5.5. Open-set classification
Conclusion, Acknowledgments and References
5.1. Regularization methodsIn this section, we compare our method to standard regularization methods: Learning without Forgetting (LwF) [17] and Synaptic Intelligence (SI) [39]. We use implementations from Avalanche [21]. We provide details of the hyperparameter choice in the supplementary material. As shown in Fig. 4, such regularization methods are ill-equipped to deal with the class-incremental learning scenario and perform no better than naive fine-tuning.
5.2. Replay-based methodsReplay-based methods retain a subset of past training data that is then mixed with the current training data for every task. While this can be a viable strategy to preserve accuracy over many tasks, it results in ever-growing memory and computation requirements, unless the buffer size is bounded. In this section, we investigate the effect of buffer size on performance for standard experience replay with reservoir sampling. While there are replay-based methods that improve on this baseline, we are interested in investigating the fundamental limits of rehearsal over long time horizons and strip away the confounding effects of data augmentation, generative replay, sampling strategies, pseudo-rehearsal etc. Figure 5 shows test accuracy for experience replay with different buffer sizes. Storing enough past samples lets the model maintain high test accuracy, but even with a buffer of 20,000 images the performance eventually starts to deteriorate. Note that after 200 tasks a balanced buffer will only contain 10 samples per class.
\ A note on implementation In an attempt to make the replay baseline stronger, we first add the data from the current task to the buffer and then train the model exclusively on the
\
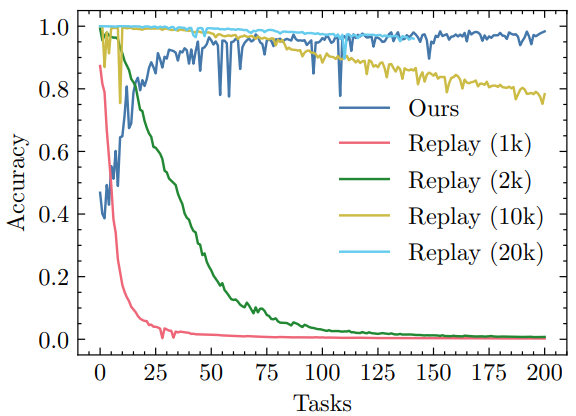
\ buffer, effectively discounting the influence of the current task over time [28]. A more standard version of experience replay would mix current and past data in equal proportions in each mini-batch, likely leading to diminished performance on previous tasks. The supplementary material includes a comparison to this other replay baseline, as well as to a version of experience replay with no memory constraint but with a compute budget matching our approach.
\
:::info This paper is available on arxiv under CC 4.0 license.
:::
\