and the distribution of digital products.
How AI Might Be Recycling—and Shrinking—Knowledge
:::info Author:
(1) Andrew J. Peterson, University of Poitiers ([email protected]).
:::
Table of LinksThe media, filter bubbles and echo chambers
Network effects and Information Cascades
\ Appendix
A Model of Knowledge Collapse Defining Knowledge Collapse \n
In other domains, however, it is less clear, especially within regions. Historically, knowledge has not progressed monotonically, as evidenced by the fall of the Western Roman empire, the destruction of the House of Wisdom in Baghdad and subsequent decline of the Abbasid Empire after 1258, or the collapse of the Mayan civilization in the 8th or 9th century. Or, to cite specific examples, the ancient Romans had a recipe for concrete that was subsequently lost, and despite progress we have not yet re-discovered the secrets of its durability (Seymour et al., 2023), and similarly for Damascus steel (Kurnsteiner et al ¨ ., 2020). Culturally, there are many languages, cultural and artistic practices, and religious beliefs that were once held by communities of humans which are now lost in that they do not exist among any known sources (Nettle and Romaine, 2000).
\ The distribution of knowledge across individuals also varies over time. For example, traditional huntergatherers could identify thousands of different plants and knew their medicinal usages, whereas most humans today only know a few dozen plants and whether they can be purchased in a grocery store. This could be seen as a more efficient form of specialization of information across individuals, but it might also impact our beliefs about the value of those species or of a walk through a forest, or influence scientific or policy-relevant judgements. \n
Informally,[2] we define knowledge collapse as the progressive narrowing over time (or over technological representations) of the set of information available to humans, along with a concomitant narrowing in the perceived availability and utility of different sets of information. The latter is important because for many purposes it is not sufficient for their to exist a capability to, for example, go to an archive to look up some information. If all members deem it too costly or not worthwhile to seek out some information, that theoretically available information is neglected and useless.
Model OverviewThe main focus of the model is whether individuals decide to invest in innovation or learning (we treat these as interchangeable) in the ‘traditional’ way, through a possibly cheaper AI-enabled process, or not at all. The idea is to capture, for example, the difference between someone who does extensive research in an archive rather than just relying on readily-available materials, or someone who takes the time to read a full book rather than reading a two-paragraph LLM-generated summary.
\ Humans, unlike LLMs trained by researchers, have agency in deciding among possible inputs. Thus, a key dynamic of the model is to allow for the possibility that rational agents may be able to prevent or to correct for distortion from over-dependence on ‘centrist’ information. If past samples neglect the ‘tail’ regions, the returns from such knowledge should be relatively higher. To the extent that they observe this, individuals would be willing to pay more (put in more labor) to profit from these additional gains. We thus investigate under what conditions such updating among individuals is sufficient to preserve an accurate vision of the truth for the community as a whole.
\ The cost-benefit decision to invest in new information depends on the expected value of that information. Anyone who experiments with AI for, e.g. text sum2For further discussion and a more precise definition, see the Appendix. marization, develops an intuitive sense of when the AI provides the main idea sufficiently well for a given purpose and when it is worth going straight to the source. We assume that individuals cannot foresee the future, but they do observe in common the realized rewards from previous rounds. The decision also depends on each individual’s type. Specifically, n individuals have types Θn drawn from a lognormal distribution with µ = 1, σ = 0.5. Depending on how their utility is calculated (not a substantive focus here), these could be interpreted as different expected returns from innovation (e.g.technooptimists versus pessimists), or their relative ability or desire to engage in innovation.
\ We model knowledge as a process of approximating a (Students t) probability distribution.[3] This is simply a metaphor, although it has parallels for example in the work of Shumailov et al. (2023), but we make no claim that “truth” is in some deep way distributed 1-D Gaussian. This is a modeling assumption in order to work with a process with well-known properties, where there is both a large central mass and long-tails, which we take to be in some general way reflective of the nature of knowledge (and of the distribution of training data for LLMs.)
\ The set of individuals who decide to invest in information receive a sample from the true distribution, while those that invest in the AI-generated sample receive a sample from a version of the true distribution which is truncated at σtr standard deviations above and below the mean. To vary the extent of mass in the tails, we model the true distribution as a Student’s t-distribution with e.g. 10 degrees of freedom. The results are similar for a standard normal distribution, and as expected the problem of knowledge collapse is more pronounced for wider tails (c.f. Appendix Figure 7).
\ While individuals choose whether or not to invest in innovation according to their personal payoff, when they do so invest they also contribute their knowledge to the public. That is, a public knowledge probability distribution function (‘public pdf’) is generated by gathering the nsamp = 100 most recent samples[4] and generating an estimate of the truth using kernel density estimation. The distance between the public pdf and the truth provides a shorthand for the general welfare of a society. We define knowledge collapse as occurring where there is a large and increasing distance between the public and true pdfs as a result of the collapse of tail regions and increasing mass near the mean.
\ The individual’s payoff is calculated according to the distance they move the public pdf towards the true pdf. That is, the innovation (individual payoff) I generated by an individuals additional (n + 1)th sample is calculated with respect to the true pdf ptrue(x) and the current public pdf ppublic(x), based on the Hellinger distance H(p(x), q(x))[5], as follows:
\ innovation = previous distance − new distance
\
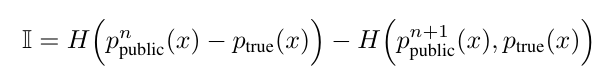
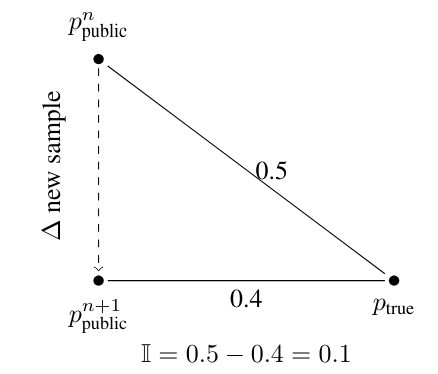
\ In Figure 2, we illustrate the innovation calculation for a hypothetical example where the distance between the existing public pdf and the true pdf is 0.5, while the n + 1th sample reduces the distance to 0.4, thereby generating an innovation of 0.1.
\
\ This can be thought of as akin to a patent process, in which an individual receives rents for her patent (to the extent that it is truly innovative) in exchange for contributing to public knowledge that benefits others.
\ As noted above, individuals cannot foresee the true future value of their innovation options (they do not know what sample they will receive or how much value it will add. Instead, they can only estimate the relative values of innovation based on the previous rounds. Specifically, they update their belief about the options based on the previous full and truncated (AI) samples from the previous round (and a minimum of three), according to a learning rate (η) as follows. For the previous estimate vt−1, the new estimate vt for each of the full- and truncated-samples is calculated from the observed value in the previous round (It−1) as
\

\ By varying the learning rate, we can evaluate the impact of having more or less up-to-date information on the value of different information sources, where we expect that if individuals are sufficiently informed, they will avoid knowledge collapse by seeing and acting on the potential to exploit knowledge from the tail regions, even if relatively more expensive.
\ While the individual payoff is based on the true movement of the public pdf towards the true pdf, the public pdf is updated based on all samples. This reflects that public consciousness is overwhelmed with knowledge claims and cannot evaluate each, so that a consensus is formed around the sum of all voices. Unlike the individual innovator who has a narrow focus and observes whether her patent ultimately generates value, the public sphere has limited attention and is forced to accept the aggregate contributions of the marketplace of ideas
\ As a result, individuals’ investments in innovation have positive spillovers to the extent they can move public knowledge towards the truth. However, if too many people invest in ‘popular’ or ‘central’ knowledge by sampling from the truncated distribution, this can have a negative externality, by distorting public knowledge towards the center and thinning the tails.[6]
\ We also introduce the possibility of generational turnover in some models to explore the impact on knowledge collapse. This could either be taken to be literal generations of humans, as in economic ‘overlapping generation’ models (e.g. Weil, 2008), or alternatively as reflecting the recursive nature of reliance on interleaved AI-systems, which could generate the same result within a rapid timeframe
\ In the version of the model with generational change, the new generation takes the existing public pdf to be representative and thus begins sampling from a distribution with the same (possibly smaller) variance (and correspondingly the truncation limits are updated). Interpreted in terms of human generations, this could be understood as the new generation fixing its ‘epistemic horizon’ based on the previous generation. That is, the new generation may underestimate the breadth of possible knowledge and then rely on these perceived limits to restrict their search.[7] An information cascade model could justify such a situation if individuals assume that previous actors would have invested in tail knowledge if was valuable, and thus take the absence of such information as implying that it must be of little value.[8]
\ A second interpretation views these ‘generations’ not in terms of human populations but as a result of recursive dynamics among AI systems, such as when a user reads an AI-generated summary of an AI-written research article which was itself constructed from Wikipedia articles edited with AI, etc., a fancy version of the telephone game.
\
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
:::
[2] For further discussion and a more precise definition, see the Appendix.
\ [3] Full replication code available at: https://github.com/aristotle-tek/knowledge-collapse
\ [4] Varying this has trivial effect on the model, though higher values can distort public knowledge.
\

\ [6] If individuals knew they were sampling from a truncated distribution, they could use the Expectation-Maximization algorithm to recover the full distribution, but again this process is meant to be metaphorical, and there is no known real-life method for recovering the source knowledge from AI-generated content.
\ [7] Zamora-Bonilla (2010, p.328) suggests a scientific process of ‘verisimiltude’, where we judge evidence not with reference to objective truth by by “perceived closeness to what we empirically know about the truth, weighted by the perceived amount of information this empirical knowledge contains”. For a more recent review of models and experiments on human cultural transmission see (Mesoudi and Whiten, 2008) and in particular the model of Henrich (2004) which attempts to explain how the Tasmanians lost a number of useful technologies over time.
\ [8] For example, Christian communities at times actively promoted and preserved ‘canonical’ texts while neglecting or banning others, with the result that those excluded from reproduction by scribes were taken to have little value. Perhaps the heliocentric view espoused by Aristarchus of Samos in the 3rd century BCE would have been more readily (re)considered if his works had not been neglected (Russo and others, 2003, ch.3). A number of authors, such as Basilides, are known to us today only through texts denouncing (and sometimes misrepresenting) their views (Layton, 1989).