and the distribution of digital products.
Experimental Setup For Large Language Model Video Generation
:::info Authors:
(1) Dan Kondratyuk, Google Research and with Equal contribution;
(2) Lijun Yu, Google Research, Carnegie Mellon University and with Equal contribution;
(3) Xiuye Gu, Google Research and with Equal contribution;
(4) Jose Lezama, Google Research and with Equal contribution;
(5) Jonathan Huang, Google Research and with Equal contribution;
(6) Grant Schindler, Google Research;
(7) Rachel Hornung, Google Research;
(8) Vighnesh Birodkar, Google Research;
(9) Jimmy Yan, Google Research;
(10) Krishna Somandepalli, Google Research;
(11) Hassan Akbari, Google Research;
(12) Yair Alon, Google Research;
(13) Yong Cheng, Google DeepMind;
(14) Josh Dillon, Google Research;
(15) Agrim Gupta, Google Research;
(16) Meera Hahn, Google Research;
(17) Anja Hauth, Google Research;
(18) David Hendon, Google Research;
(19) Alonso Martinez, Google Research;
(20) David Minnen, Google Research;
(21) Mikhail Sirotenko, Google Research;
(22) Kihyuk Sohn, Google Research;
(23) Xuan Yang, Google Research;
(24) Hartwig Adam, Google Research;
(25) Ming-Hsuan Yang, Google Research;
(26) Irfan Essa, Google Research;
(27) Huisheng Wang, Google Research;
(28) David A. Ross, Google Research;
(29) Bryan Seybold, Google Research and with Equal contribution;
(30) Lu Jiang, Google Research and with Equal contribution.
:::
Table of Links3. Model Overview and 3.1. Tokenization
3.2. Language Model Backbone and 3.3. Super-Resolution
4. LLM Pretraining for Generation
5. Experiments
5.2. Pretraining Task Analysis
5.3. Comparison with the State-of-the-Art
5.4. LLM’s Diverse Capabilities in Video Generation and 5.5. Limitations
6. Conclusion, Acknowledgements, and References
5.1. Experimental SetupTraining tasks. We train the model on a mixture of pretraining tasks as detailed in Section 4.1. We finetune a model on a high-quality training subset for text-to-video evaluations, as discussed in Section 4.2. Unless explicitly stated, we do not finetune on specific tasks for evaluations.
\ Datasets. We train on a total of 1B image-text pairs and ∼270M videos (∼100M with paired text, of which ∼50M are used for high-quality finetuning, and ∼170M with paired audio) from the public internet and other sources, i.e. around 2 trillion tokens across all modalities. The data has been filtered to remove egregious content and sampled to improve contextual and demographic diversity.
\ Evaluation protocol. We employ a zero-shot generation evaluation protocol, as the model has not been trained on the training data of target benchmarks. Specifically, the evaluation benchmark includes two text-to-video generation datasets, MSR-VTT (Xu et al., 2016) and UCF-101 (Soomro et al., 2012), as well as the frame prediction task on Kinetics 600 (K600) (Carreira et al., 2018), in which the first 5 frames are provided as the condition to predict the next 11 frames. We also include inpainting and outpainting tasks (Yu et al., 2023a) on Something-Something V2 (SSv2) (Goyal et al., 2017).
\ We adopt widely used metrics such as Frechet Video Distance (FVD) (Unterthiner et al., 2018), CLIP similarity
\
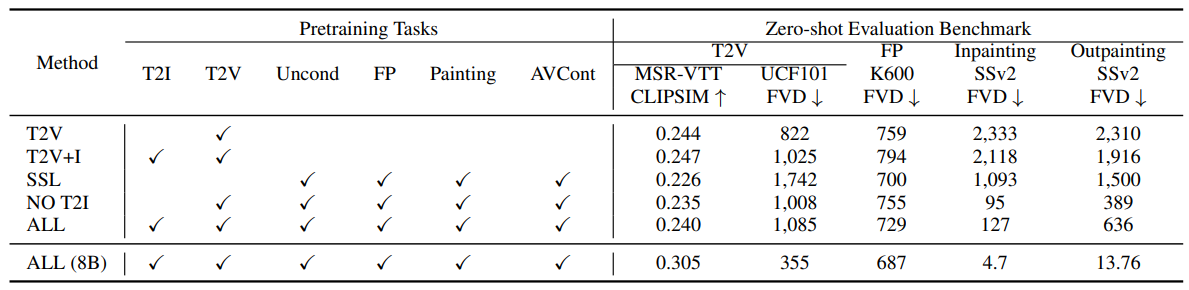
\ score (Wu et al., 2021), and Inception Score (IS) (Saito et al., 2020) for evaluation. Note that the specific metrics and evaluation methods vary across different datasets. Detailed information on these variations can be found in Appendix A.5.4. We include examples of the generated videos in the supplementary materials.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\