and the distribution of digital products.
Dynamic Frontier PageRank Achieves Efficiency and Accuracy with Batch Updates and Parallel Computing
:::info Author:
(1) Subhajit Sahu, IIIT Hyderabad, Hyderabad, Telangana, India ([email protected]).
:::
Table of Links5.2 Performance of Dynamic Frontier PageRank
5.3 Strong Scaling of Dynamic Frontier PageRan
6 Conclusion, Acknowledgments, and References
5. EVALUATION 5.1 Experimental Setup5.1.1 System used. We conduct experiments on a system equipped with an AMD EPYC-7742 processor, with 64 cores and operating at a frequency of 2.25 GHz. Each core has a 4 MB L1 cache, a 32 MB L2 cache, and shares a 256 MB L3 cache. The server is configured with 512 GB of DDR4 system memory and operates on Ubuntu 20.04.
\

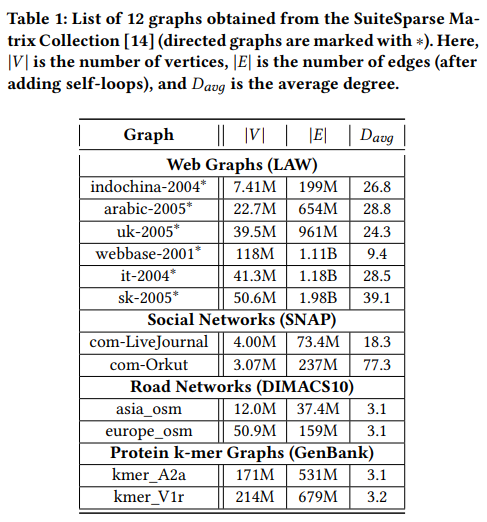
\ 5.1.3 Dataset. We use four graph classes sourced from the SuiteSparse Matrix Collection [14], as detailed in Table 1. The number of vertices in these graphs range from 3.07 million to 214 million, with edge counts spanning from 37.4 million to 1.98 billion. To address the impact of dead ends (vertices lacking out-links), a global teleport rank computation is needed in each iteration. We mitigate this overhead by adding self-loops to all vertices in the graph [1, 15].
\

\

\
\
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
:::
\