and the distribution of digital products.
Cost Optimization Techniques for AWS DynamoDB in Orchestration Applications
AWS DynamoDB is a fully managed, serverless document store that offers single-digit millisecond performance at any scale. It supports various data models and supports transactions, global tables for multi-region replication.
\ It is crucial to design the schema well in DynamoDB, otherwise it can lead to significant cost implications and degraded performance. In this article we will go through the techniques that can be applied for cost optimizations and scalability for an orchestration application.
\ The pricing structure of DynamoDB can be found here and here.
\
Orchestration ApplicationThe application is an orchestration service that stores requests from clients, sends the event to multiple upstreams. Each upstream fetches the request on receipt of event, processes it and replies with it’s status. The caller then asynchronously can find out the status of the request. The status contains each upstream responses.
\
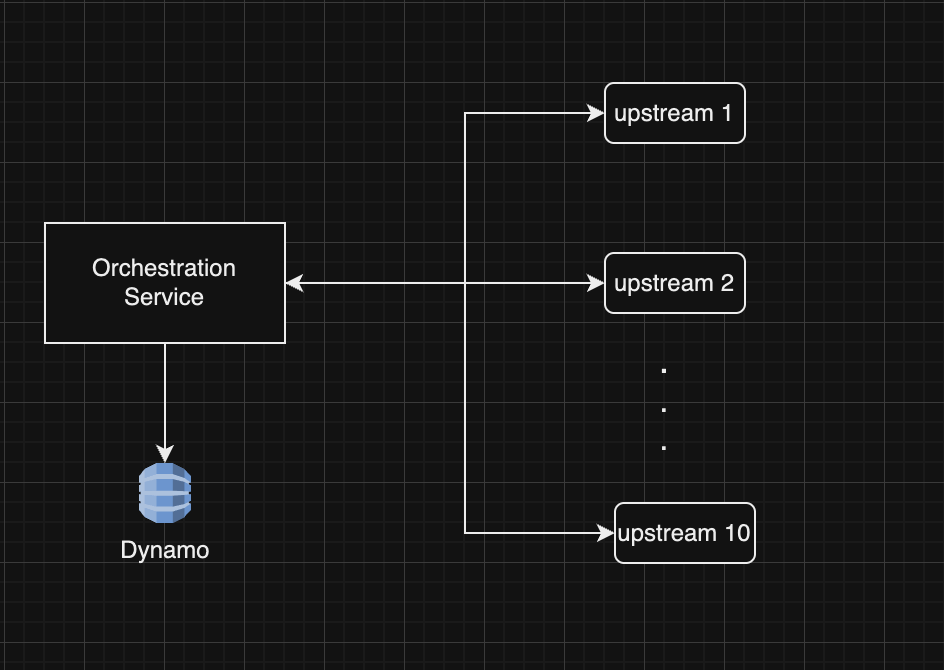
\ This application experiences high volume surge for several minutes followed by inactivity. On-demand pricing is better choice for these type of applications.
\ We will start with a simple schema solution for this application and then go into detail to optimize the schema for better cost and performance. The cost estimates can be calculated using AWS Pricing Calculator
Scenario 1- We store the request as well as upstream responses in the same dynamo document
- Everytime the upstream sends the response, we update this document
- Inputs
- Size of document storing request = 100 KB
- Size of responses from upstreams = 100 KB
- Total average document size = 200 KB
- Requests per day = 1 Million
- number of upstream services to handle each request = 10
\ \ Pricing
| Operation | Calculation | Total Cost | |:---:|:---:|:---:| | Write Operations | | | | 1 write request | 1 WRU per 200 KB = 200 WRUs | - | | 10 upstream writes | 10 * 200 WRUs = 2,000 WRUs | - | | 1 million requests | 1 million * 2,200 WRUs = $1.25 * 2,200 | $2,750 | | | | | | Read Operations (Strongly consistent) | | | | 1 read request | 1 RRU per 200 KB = 50 RRUs | - | | 10 upstream reads | 10 * 50 RRUs = 500 RRUs | - | | 1 million requests | 1 million * 500 RRUs = $0.25 * 500 | $125 | | | | | | Total Cost per Day | | $2,875 |
\
Scenario 2The major cost in previous scenario is due to writes with larger item size. In our application, we really don’t need to maintain the request data and responses data in a single document. If we split them into two, we do not need to write whole document each time the upstream sends reply. We update only the responses document which is 100 KB, reducing writes on 100 KB per upstream per request
\ \ Pricing
| Operation | Calculation | Total Cost | |:---:|:---:|:---:| | Write Operations | | | | 1 write request | 1 WRU per 100 KB = 100 WRUs | - | | 10 upstream writes | 10 * 100 WRUs = 1,000 WRUs | - | | 1 million requests | 1 million * 1,100 WRUs = $1.25 * 1,100 | $1,375 | | | | | | Read Operations (Strongly Consistent) | | | | 1 read request | 1 RRU per 100 KB = 25 RRUs | - | | 10 upstream reads | 10 * 25 RRUs = 250 RRUs | - | | 1 million requests | 1 million * 250 RRUs = $0.25 * 250 | $62.5 | | | | | | Total Cost per Day | | $1,437.5 |
\ This design resulted in 50% reduction in cost from Scenario 1
\
Scenario 3Looking deep into the use case of the upstream responses, there is no dependency on replies between each upstream services. We do not need to write each reply in a single document. If we keep them in a single document, it makes easier to read them. Given our use case, the writes are higher compared to reads. So we can try to split the responses document into separate ones for each upstream service. In this scenario, we will have 10 documents with 10 KB size for upstream responses instead of single 100 KB document.
\ \ Pricing
| Operation | Calculation | Total Cost | |:---:|:---:|:---:| | Write Operations | | | | 1 write request | 1 WRU per 100 KB (request) = 100 WRUs | - | | 1 write request (upstream) | 1 WRU per 10 KB = 10 WRUs | - | | 10 upstream writes | 10 * 10 WRUs = 100 WRUs | - | | 1 million requests | 1 million * 200 WRUs = $1.25 * 200 | $250 | | | | | | Read Operations (Strongly consistent) | | | | 1 read request | 1 RCU per 100 KB = 25 RRUs | - | | 10 upstream reads | 10 * 25 RCUs = 250 RRUs | - | | 1 million requests | 1 million * 250 RRUs = 0.25 * 250 | $62.5 | | | | | | Total Cost per Day | | $312.5 |
\ This design achieves 78.26% reduction in cost compared to Scenario 2 and 89.1% reduction compared to Scenario 1
\
ConclusionThe schema design plays an important role in DynamoDb cost optimizations. The size of each document should be kept as minimal as possible for write heavy applications. To reduce costs, each document’s size should be minimized, as larger items incur higher write costs.
\