and the distribution of digital products.
This Code Change Sped Up MySQL Queries from 25 Minutes to 23 Seconds
In JDBC source batch processing tasks, if table_path and partition_column are configured, the engine will dynamically partition the data. We can optimize partition intervals by analyzing sample data to avoid data skew issues. However, it has been observed that even when where_condition is configured, the dynamic partitioning algorithm still partitions the entire table. This leads to excessive time consumption in the partitioning phase, especially when retrieving a small amount of data from a large table. To address this, we need to modify the relevant processes to optimize performance.
\ All SQL statements in the following explanations use MySQL as an example. Different data sources have specific subclass methods implemented via overwriting.
Key Problem Analysis55GB MySQL Table Case:
Original implementation took 25 minutes to read 1000 rows
Optimized version reduced to23 seconds (PR #8760)
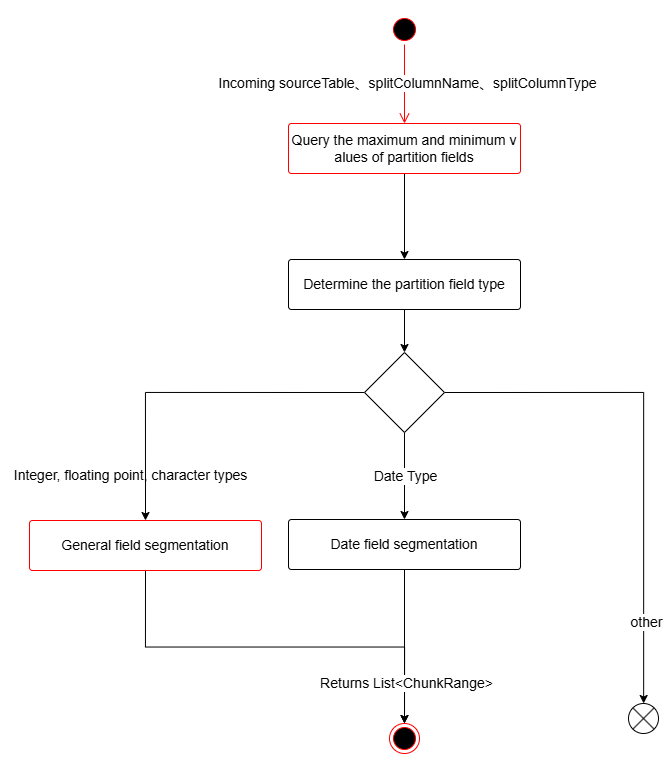
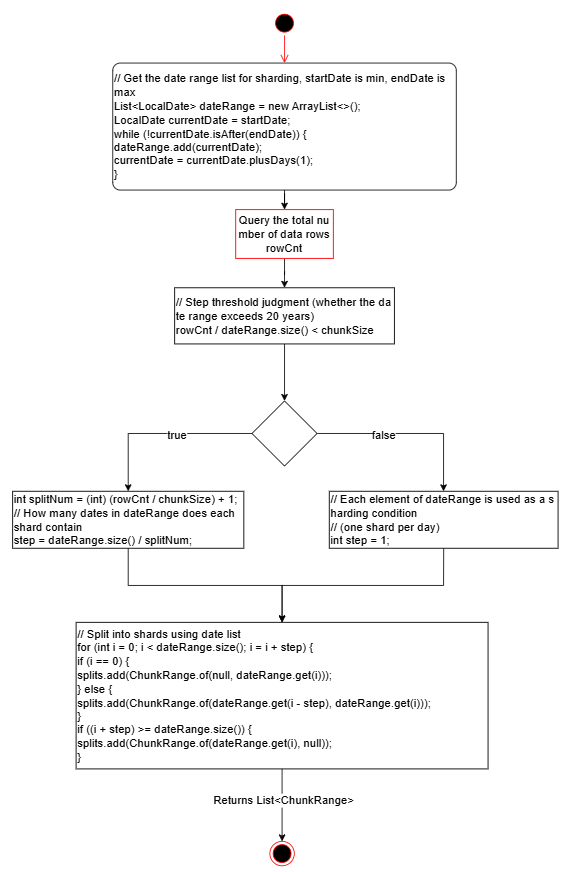
The entry point for dynamic partitioning in the code is the splitTableIntoChunks method in the DynamicChunkSplitter class. The red-highlighted boxes in the flowchart indicate the parts that need modifications, which will be detailed in the following sub-processes.
1.1.1 Querying Minimum and Maximum Values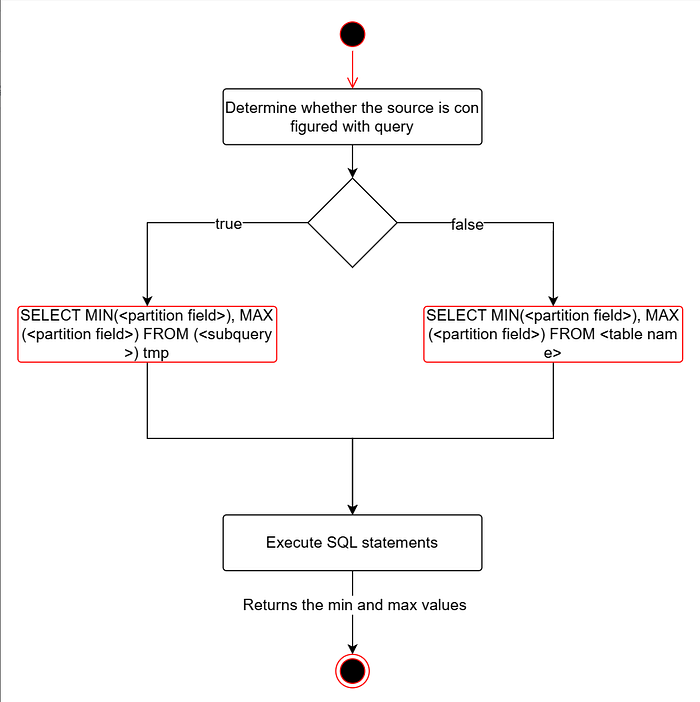
It is necessary to include the where_condition configuration in the source and append it to the query.
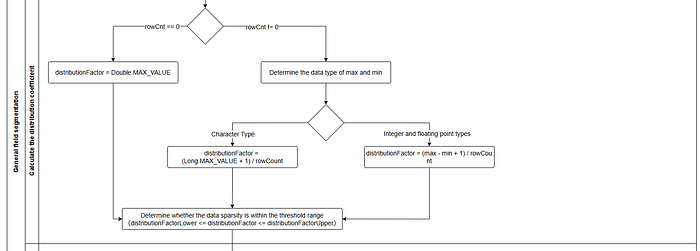
1.1.2 General Column Partitioning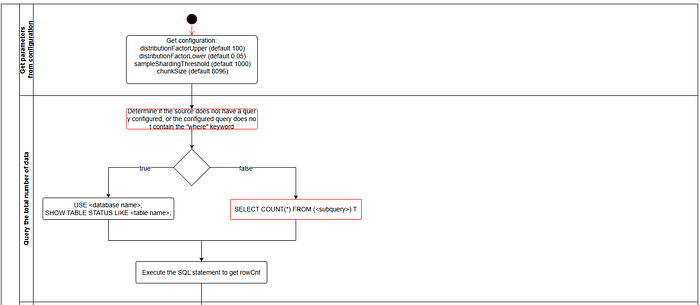
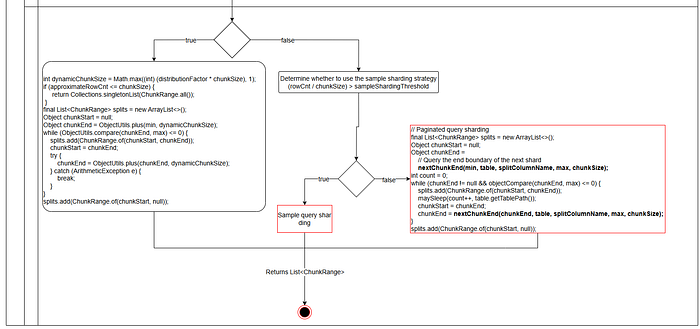
- Add a condition to ensure that the “yes” branch is executed only when where_condition is empty.
- Modify the “no” branch to include where_condition validation and concatenate it into the corresponding query statement. The query rules are as follows:
- If query is configured, use:
- Otherwise, use:
- If where_condition is configured, append it to the end of the query.
Refer to the following sub-process for details.
1.1.2.1 Pagination-Based PartitioningQuerying the next partition boundary (nextChunkEnd)
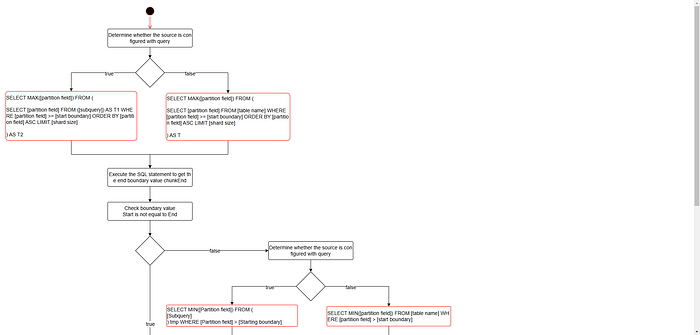

- Max Query Section
If where_condition is configured, append it to the LIMIT query layer.
\
- Min Query Section
- If where_condition is configured, append it to the query.
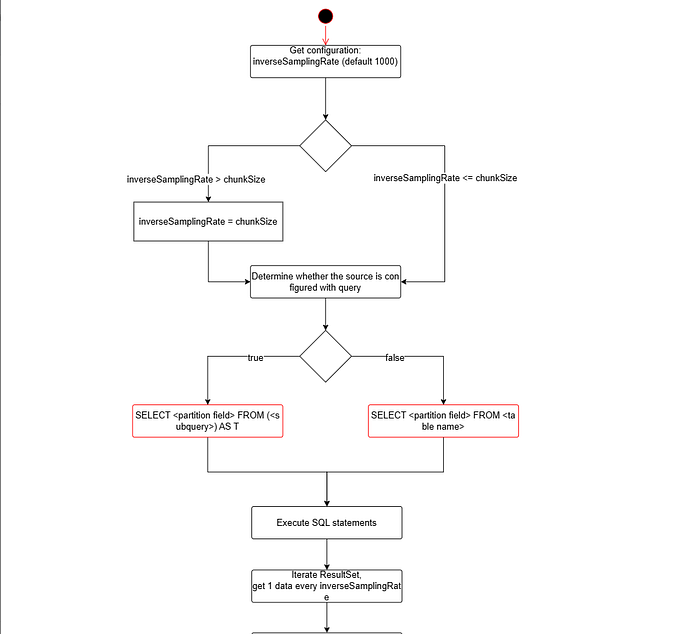
- If where_condition is configured, append it to the query.
This section reuses the logic from 1.1.2.1, requiring only a single modification.
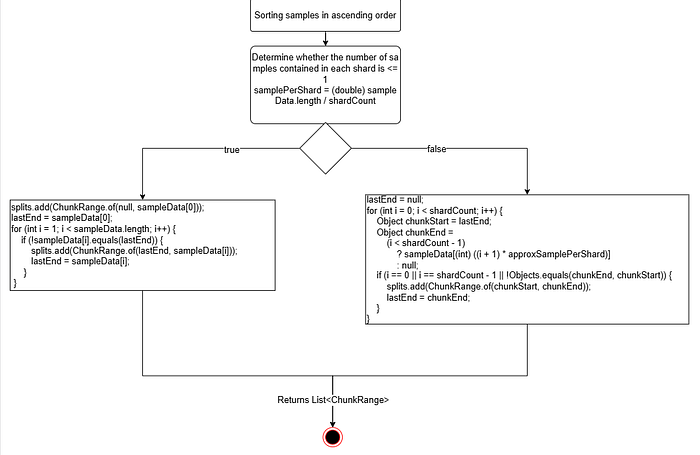
1.2 Usage of PartitionsThis section does not require modifications. The analysis here aims to understand how partitions are utilized, ensuring the correctness, necessity, and risks of the previous modifications.
\ Once the data is partitioned, it is distributed to the worker’s SourceSeaTunnelTask. Finally, it is used in the open method of the JdbcInputFormat class. The primary process is as follows:
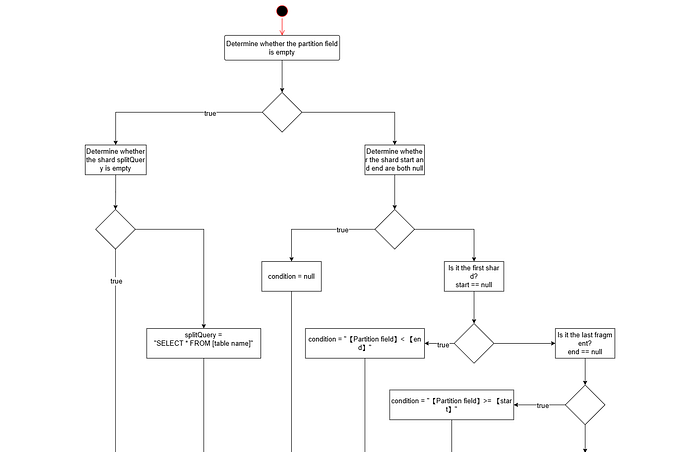

\ From the process above, it is evident that it where_condition is appended to the generated SQL in the final step. If it where_condition is not considered during partition generation, some partitions may end up querying no data when where_condition is applied. When numerous such partitions exist, it not only impacts partitioning performance but also degrades data retrieval performance due to a high volume of ineffective queries.
1.3 Optimization ResultsAfter optimization, local testing showed that the time required to filter and retrieve 1,000 rows from a 55GB MySQL table using where_condition and write them to an Oracle table reduced from 25 minutes to 23 seconds.
\ The corresponding PR for this optimization can be found here: PR #8760.