and the distribution of digital products.
Can AI Tell Jane Austen’s Writing Apart from a Fake?
:::info Authors:
(1) Todd K. Moon, Electrical and Computer Engineering Department, Utah State University, Logan, Utah;
(2) Jacob H. Gunther, Electrical and Computer Engineering Department, Utah State University, Logan, Utah.
:::
Table of LinksAbstract and 1 Introduction and Background
2 Statistical Parsing and Extracted Features
7 Conclusions, Discussion, and Future Work
A. A Brief Introduction to Statistical Parsing
B. Dimension Reduction: Some Mathematical Details
6.1 SanditonUp until shortly before her death in 1817, Jane Austen was working on a novel posthumously titled Sanditon [32, p. 20]. Before her death she completed a draft of twelve chapters (about 24,000 words). The novel was posthumously “completed” by various writers with varying success. The version best known was published in 1975 [33], coathored by “Another Lady,” whose identity remains unknown. Whoever she was, she was a fan of Austen’s and attempted to mimic her style. Of this version, it was said, it “received, as compared with [its] predecessors, a warm reception from the English critics.” [34, p. 76]. Notwithstanding its literary appeal and the attempts at imitating the conscious habits of Austen, she failed in capturing the unconscious habits of detail: stylometric analysis has been able to distinguish between the different authors [2, Chapter 16].
\ We obtained a computer-readable document from the Electronic Text Center at the University of Virginia Library [35]. The document was evidently obtained optical character recognition (OCR) from scanned documents, so it was necessary to carefully spell-check the document, but contemporary spellings were retained. Two documents were produced, the first for Austen (with 1176 sentences) and the second for Other (with 2559 sentences). These were split into segments (for purposes of testing the classification capability). The Austen document had two segments of length 588 sentences. The Other document had four segments of lengths 640, 640, 640, 639. Subtrees of various depths were extracted from the segments, and these were classified the same way as the Federalist papers. Summary statistics about the documents are provided in Table 11.
\ Despite the attempt to duplicate Austen’s style, the segments for the different authors readily classify according to author, as shown below.
\
\
\
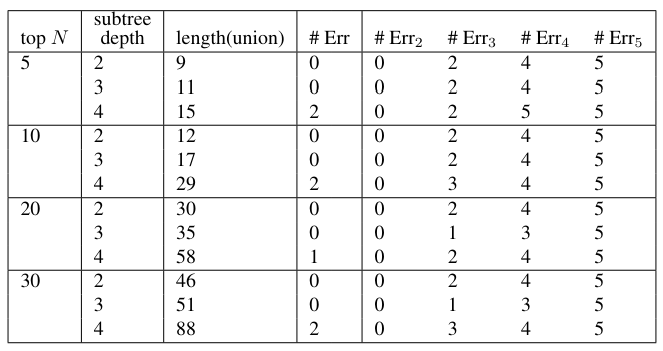
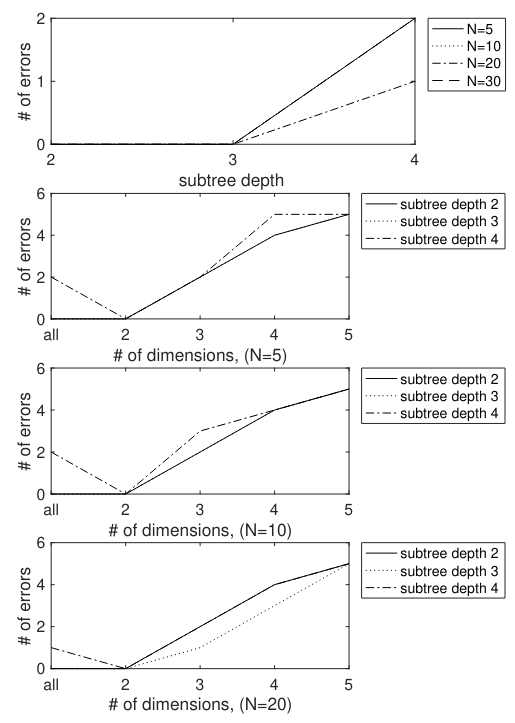
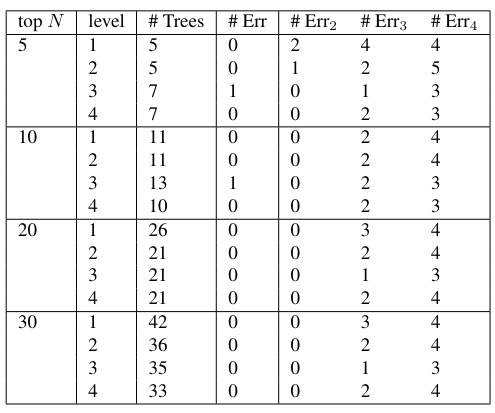
\ All Subtrees For each six of the documents (two Austen, four Other), counts of all subtrees were extracted. As for the Federalist papers, the top N counts were extracted for N = 5, 10, 20, 30, and the union of these features was formed. This was done for subtrees of depth 2, 3, and 4. The number of trees in the union and intersection of these sets is shown in Table 12.
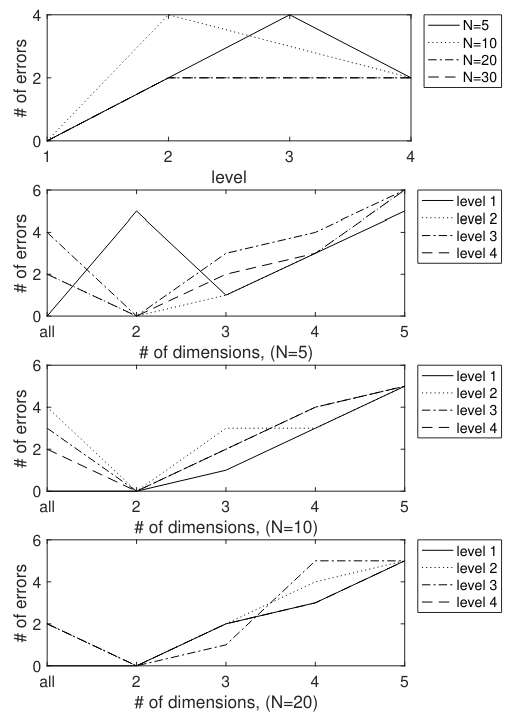
\ Classifier results for the all subtrees feature are shown in Table 13, and also portrayed in figure 9. As is shown, even with the full dimensionality (without projecting into a lower dimensional space), separation can be done completely accurately. On the other hand, the projected feature vectors do not generally perform as well as the full-dimensional data. This differs from how the lower dimensional projections worked for the Federalist documents.
\ Rooted Subtrees We next considered using rooted subtrees as feature vectors. Feature vectors were formed in the same way as for the The Federalist Papers. Results are shown in Table 14 and portrayed in figure 10. While not as effective at distinguishing as the subtrees features, this feature still shows the ability to distinguish between authors.
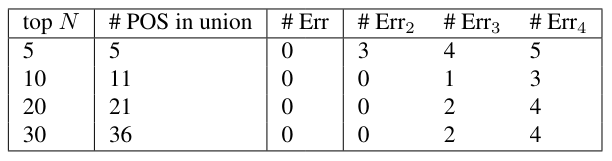
\ POS POS feature vectors were extracted in the same manner as for the The Federalist Papers. Data up to Err4 were produced. The POS data was able to effectively distinguish between authors, more effectively than for the The Federalist Papers. Reducing the dimensionality did not improve the classifier (and beyond ℓ = 2 made it worse).
\
\
\
\
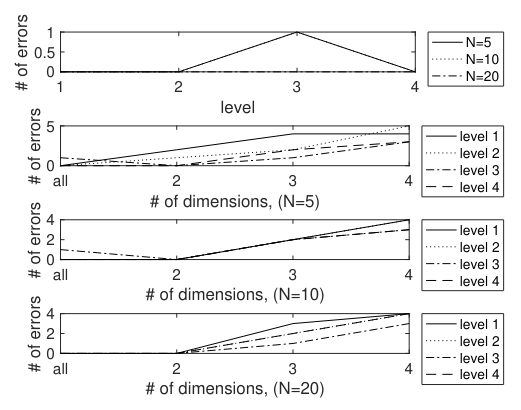
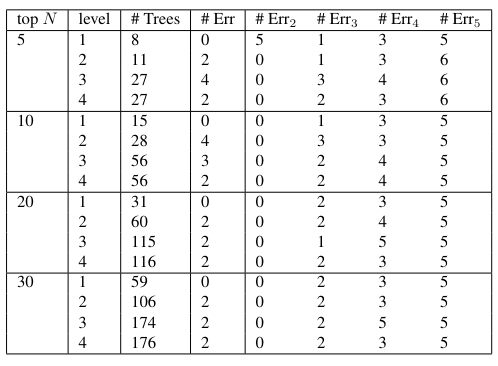
\ POS by Level POS by Level feature vectors were extracted in the same manner as for the The Federalist Papers. Data up to Err4 were produced. The classification results are shown in Table 16 and portrayed in figure 11.
\ The POS by Level data was able to effectively distinguish between authors, more effectively than for the The Federalist Papers. Reducing the dimensionality did not improve the classifier (and beyond ℓ = 2 made it worse).
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\