and the distribution of digital products.
Beyond the Prototype: 15 Hard-Earned Lessons to Ship Production-Ready AI Agents
It usually starts with a few lines of Python and a ChatGPT API key.
\ You add a few lines of context, hit run, and marvel that it responds at all. Then, you want it to do something useful. Then, reliably. Then, without you. That’s when you realize you’re no longer just calling an LLM. You’re building an agent.
\ I spent the last year cobbling together scripts and wrappers, juggling LangChain chains that felt more like a house of cards than systems, and constantly wondering, “How are people actually shipping this stuff?”
\ I chased patterns that looked elegant in theory but collapsed the moment real users showed up. I built agents that worked perfectly in a notebook and failed spectacularly in production. I kept thinking the next repo, the next tool, the next framework would solve it all.
\ It didn’t.
\ What helped me was slowing down, stripping things back, and paying attention to what actually worked under load, not what looked clever on LinkedIn. ==This guide is a distillation of that hard-earned clarity==. If you’ve been through similar challenges, it’s written for you.
\ Think of it as a pragmatic guide to moving from API wrappers and chains to stable, controllable, scalable AI systems.
Early agent prototypes often come together quickly: a few functions, some prompts, and voilà, it works.
\ You might ask, “If it works, why complicate things?”
\ At first, everything feels stable: the agent responds, runs code, and behaves as expected. But the moment you swap the model, restart the system, or add a new interface, things break. The agent becomes unpredictable, unstable, and a pain to debug.
\ ==Usually, the problem isn’t the logic or prompts; it’s deeper==: poor memory management, hardcoded values, no session persistence, or a rigid entry point.
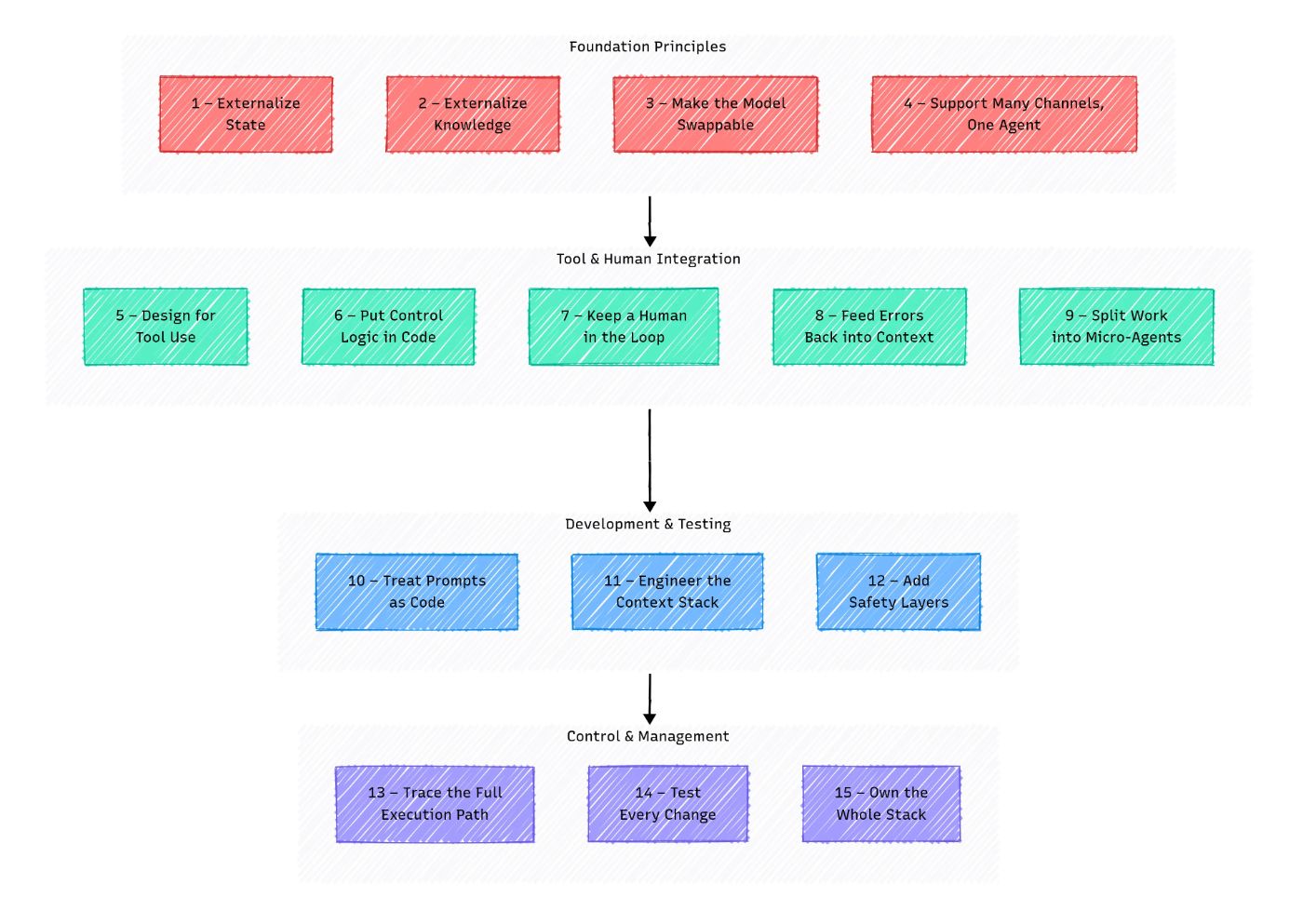
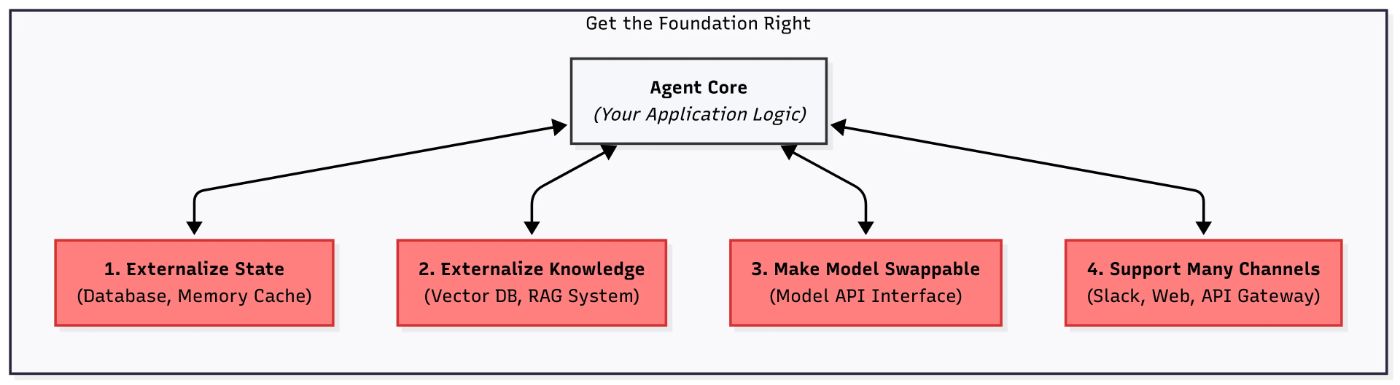
\ This section covers four key principles to help you create a rock-solid foundation, a base where your agent can reliably grow and scale.
\
1 — Externalize StateThe Problem:
- You can’t resume if the agent gets interrupted, crashes, times out, whatever. It needs to pick up exactly where it left off.
- Reproducibility: you want to replay what happened for testing and debugging.
- Bonus challenge: sooner or later, you’ll want to run parts of the agent in parallel, like comparing options mid-conversation or branching logic (Memory management is a separate topic we’ll cover soon.)
\ The Solution: Move all state outside the agent, into a database, cache, storage layer, or even a simple JSON file.
\ Your Checklist:
- The agent starts from any step using just a session_id and external state (e.g., saved in a DB or JSON).
- You can interrupt and restart the agent anytime (even after code changes) without losing progress or breaking behavior.
- State is fully serializable without losing functionality.
- The same state can be fed to multiple agent instances running in parallel during a conversation.
The Problem: LLMs don’t actually remember. Even in one session, they can forget what you told them, mix up conversation stages, lose the thread, or start “filling in” details that weren’t there. Sure, context windows are getting bigger (8k, 16k, 128k tokens) but problems remain:
- The model focuses on the beginning and end, losing important middle details.
- More tokens cost more money.
- The limit still exists: transformers work with self-attention at O(n²) complexity, so infinite context is impossible.
\ This hits hardest when:
- Conversations are long
- Documents are large
- Instructions are complex
\ The Solution: Separate “working memory” from “storage”, like in classical computers. Your agent should handle external memory: storing, retrieving, summarizing, and updating knowledge outside the model itself.
\ Common approaches:
- Memory Buffer: stores the last k messages. Quick to prototype, but loses older info and doesn’t scale.
- Summarization Memory: compresses history to fit more in context. Saves tokens but risks distortion and loss of nuance.
- RAG (Retrieval-Augmented Generation): fetches knowledge from external databases. Scalable, fresh, and verifiable, but more complex and latency-sensitive.
- Knowledge Graphs: structured connections between facts and entities. Elegant and explainable, but complex and high barrier to entry.
\ Your Checklist:
- All conversation history is stored outside the prompt and is accessible.
- Knowledge sources are logged and reusable.
- History can grow indefinitely without hitting context window limits.
Problem: LLMs evolve fast: OpenAI, Google, Anthropic, and others constantly update their models. As engineers, we want to tap into these improvements quickly. Your agent should switch between models easily, whether for better performance or lower cost.
\ Solution:
- Use a model_id parameter in configs or environment variables to specify which model to use.
- Build abstract interfaces or wrapper classes that talk to models through a unified API.
- Optionally, apply middleware layers with care (frameworks come with trade-offs).
\ Checklist:
- Changing the model doesn’t break your code or affect other components like memory, orchestration, or tools.
- Adding a new model means just updating the config and, if needed, adding a simple adapter layer.
- Switching models is quick and seamless — ideally supporting any model, or at least switching easily within a model family.
Problem: Even if your agent starts with a single interface (say, a UI), users will soon want more ways to interact: Slack, WhatsApp, SMS, maybe even a CLI for debugging. Without planning for this, you risk a fragmented, hard-to-maintain system.
\ Solution: Create a unified input contract, an API, or a universal interface that all channels feed into. Keep channel-specific logic separate from your agent’s core.
\ Checklist:
- Agent works via CLI, API, UI, or any other interface
- All inputs funnel through a single endpoint, parser, or schema
- Every interface uses the same input format
- No business logic lives inside any channel adapter
- Adding new channels means just writing an adapter — no changes to core agent code
While there’s only one task, everything is simple, like in AI influencers’ posts. But as soon as you add tools, decision-making logic, and multiple stages, the agent turns into a mess.
\ ==It loses track, doesn’t know what to do with errors, forgets to call the right tool, and you’re left alone again with logs, where “well, everything seems to be written there.”==
\ To avoid this, the agent needs a clear behavioral model: what it does, what tools it has, who makes decisions, how humans intervene, and what to do when something goes wrong.
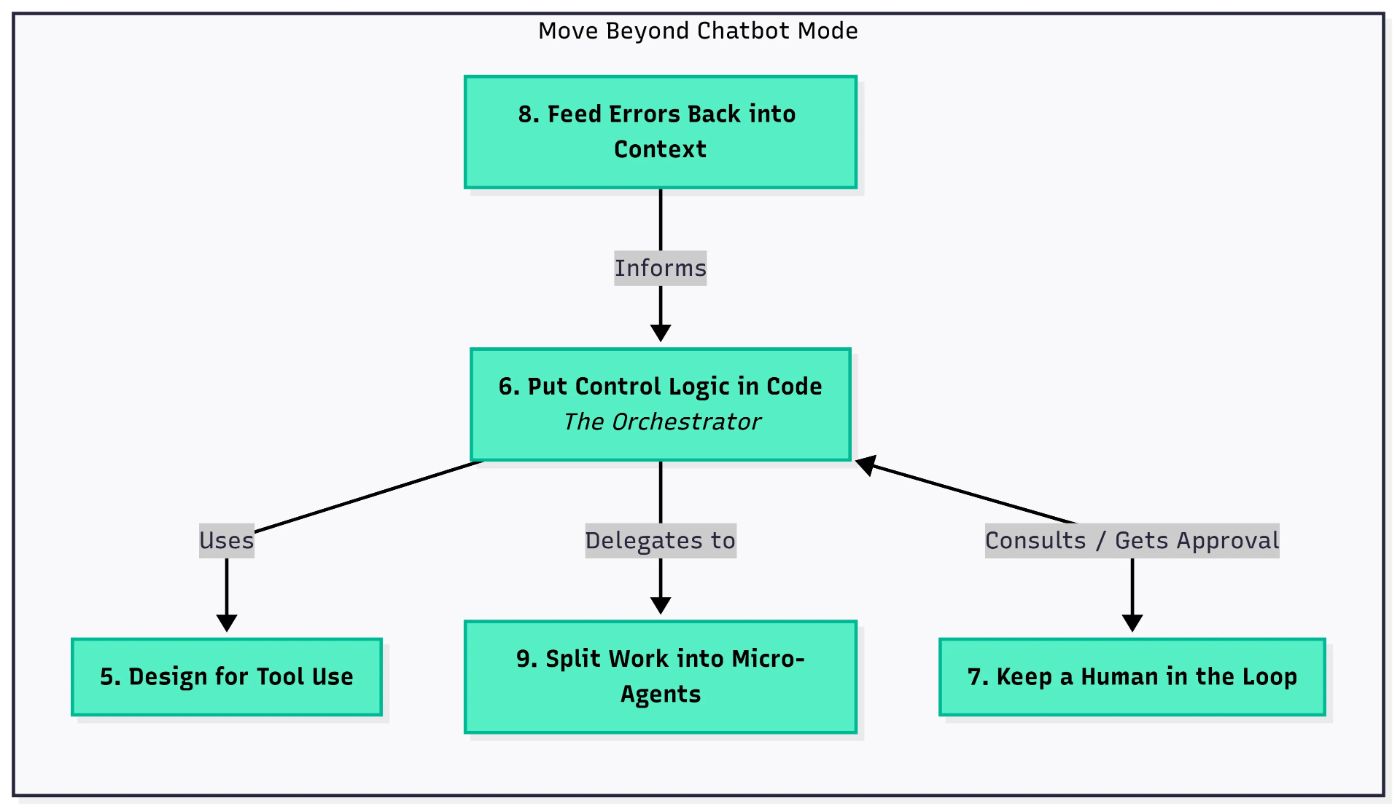
\ This section covers five key principles to help you move your agent beyond a simple chatbot, building a coherent behavioral model that can reliably use tools, manage errors, and execute complex tasks.
\
5 — Design for Tool UseProblem: It might sound obvious, but many agents still rely on “Plain Prompting + raw LLM output parsing.” It’s like trying to fix a car engine by randomly turning bolts. When LLMs return plain text that we then try to parse with regex or string methods, you face several issues:
- Brittleness: A tiny change in wording or phrase order can break your parsing, creating a constant arms race between your code and the model’s unpredictability.
- Ambiguity: Natural language is vague. “Call John Smith.” Which John Smith? What number?
- Maintenance complexity: Parsing code gets tangled and hard to debug. Each new agent “skill” means writing more parsing rules.
- Limited capabilities: It’s tough to reliably call multiple tools or pass complex data structures via plain text.
\ Solution: Let the model return JSON (or another structured format), and let your system handle the execution. This means the LLMs interpret user intent and decide what to do, and your code takes care of how it happens, executing the right function through a well-defined interface.
\ Most providers (OpenAI, Google, Anthropic, etc.) now support function calling or structured output:
- You define your tools as JSON Schemas with a name, description, and parameters. Descriptions are key because the model relies on them.
- Each time you call the model, you provide it with these tool schemas alongside the prompt.
- The model returns JSON specifying: (1) the function to call, (2) Parameters according to the schema
- Your code validates the JSON and invokes the correct function with those parameters.
- Optionally, the function’s output can be fed back into the model for final response generation.
\ Important: Tool descriptions are part of the prompt. If they’re unclear, the model might pick the wrong tool. What if your model doesn’t support function calling, or you want to avoid it?
\ Ask the model to produce JSON output via prompt engineering and validate it with libraries like Pydantic. This works well but requires careful formatting and error handling.
\ Checklist:
- Responses are strictly structured (e.g., JSON)
- Tool interfaces are defined with schemas (JSON Schema or Pydantic)
- The output is validated before execution
- Errors in format don’t crash the system (graceful error handling)
- LLM decides which function to call, code handles execution
Problem: Most agents today behave like chatbots: user says something, agent replies. It’s a ping-pong pattern; simple and familiar, but deeply limiting.
\ With that setup, your agent can’t:
- Act on its own without a user prompt
- Run tasks in parallel
- Plan and sequence multiple steps
- Retry failed steps intelligently
- Work in the background
\ It becomes reactive instead of proactive. What you really want is an agent that thinks like a scheduler: one that looks at the job ahead, figures out what to do next, and moves forward without waiting to be poked.
\ That means your agent should be able to:
- Take initiative
- Chain multiple steps together
- Recover from failure
- Switch between tasks
- Keep working, even when no one’s watching
\ Solution: Move the control flow out of the LLM and into your system. The model can still help (e.g., decide which step comes next), but the actual sequencing, retries, and execution logic should live in code.
\ This flips your job from prompt engineering to system design. The model becomes one piece of a broader architecture, not the puppet master.
\ Let’s break down three ways teams are approaching this shift.
\ 1. Finite State Machine (FSM)
- What it is: Break the task into discrete states with defined transitions.
- LLM role: Acts within a state or helps pick the next one.
- Best for: Linear, predictable flows.
- Pros: Simple, stable, easy to debug.
- Tools: StateFlow, YAML configs, classic state pattern in code.
\ 2. Directed Acyclic Graph (DAG)
- What it is: Represent tasks as a graph — nodes are actions, edges are dependencies.
- LLM role: Acts as a node or helps generate the graph.
- Best for: Branching flows, parallel steps.
- Pros: Flexible, visual, good for partial recomputation.
- Tools: LangGraph, Trellis, LLMCompiler, or DIY with a graph lib.
\ 3. Planner + Executor
- What it is: One agent (or model) builds the plan; others execute it step by step.
- LLM role: Big model plans, small ones (or code) execute.
- Best for: Modular systems, long chains of reasoning.
- Pros: Separation of concerns, scalable, cost-efficient.
- Tools: LangChain’s Plan-and-Execute, or your own planner/executor architecture.
\ Why This Matters
- You gain control over the agent’s behavior
- You can retry, debug, and test individual steps
- You can scale parts independently or swap models
- You make things visible and traceable instead of opaque and magical
\ Checklist
- Agent follows the FSM, DAG, or planner structure
- LLM suggests actions but doesn’t drive the flow
- You can visualize task progression
- Error handling is baked into the flow logic
Problem: Even with tools, control flow, and structured outputs, full autonomy is still a myth. LLMs don’t understand what they’re doing. They can’t be held accountable. And in the real world, they will make the wrong call (sooner or later).
\ When agents act alone, you risk:
- Irreversible mistakes: deleting records, messaging the wrong person, sending money to a dead wallet.
- Compliance issues: violating policy, law, or basic social norms.
- Weird behavior: skipping steps, hallucinating actions, or just doing something no human ever would.
- Broken trust: users won’t rely on something that seems out of control.
- No accountability: when it breaks, it’s unclear what went wrong or who owns the mess.
\ Solution: Bring Humans Into the Loop (HITL)
Treat the human as a co-pilot, not a fallback. Design your system to pause, ask, or route decisions to a person when needed. Not everything should be fully automatic. Sometimes, “Are you sure?” is the most valuable feature you can build.
\ Ways to Include Humans
- Approval gates: Critical or irreversible actions (e.g., sending, deleting, publishing) require explicit human confirmation.
- Escalation paths: When the model’s confidence is low or the situation is ambiguous, route to a human for review.
- Interactive correction: Allow users to review and edit model responses before they’re sent.
- Feedback loops: Capture human feedback to improve agent behavior and train models over time (Reinforcement Learning from Human Feedback).
- Override options: Enable humans to interrupt, override, or re-route the agent’s workflow.
\ Checklist
- Sensitive actions are confirmed by a human before execution
- There’s a clear path to escalate complex or risky decisions
- Users can edit or reject agent outputs before they’re final
- Logs and decisions are reviewable for audit and debugging
- The agent explains why it made a decision (to the extent possible)
Problem: Most systems crash or stop when an error happens. For an autonomous agent, that’s a dead end. But blindly ignoring errors or hallucinating around them is just as bad.
\ What can go wrong:
- Brittleness: Any failure, whether an external tool error or unexpected LLM output, can break the entire process.
- Inefficiency: Frequent restarts and manual fixes waste time and resources.
- No Learning: Without awareness of its own errors, the agent can’t improve or adapt.
- Hallucinations: Errors unaddressed can lead to misleading or fabricated responses.
\ Solution: Treat errors as part of the agent’s context. Include them in prompts or memory so the agent can try self-correction and adapt its behavior.
\ How it works:
- Understand the error: Capture error messages or failure reasons clearly.
- Self-correction: The agent reflects on the error and tries to fix it by: (1) detecting and diagnosing the issue, (2) adjusting parameters, rephrasing requests, or switching tools, (3) retrying the action with changes.
- Error context matters: Detailed error info (like instructions or explanations) helps the agent correct itself better. Even simple error logs improve performance.
- Training for self-correction: Incorporate error-fix examples into model training for improved resilience.
- Human escalation: If self-correction repeatedly fails, escalate to a human (see Principle 7).
\ Checklist:
- Errors from previous steps are saved and fed into context
- Retry logic is implemented with adaptive changes
- Repeated failures trigger a fallback to human review or intervention
Problem: The larger and messier the task, the longer the context window, and the more likely an LLM is to lose the plot. Complex workflows with dozens of steps push the model past its sweet spot, leading to confusion, wasted tokens, and lower accuracy.
\ Solution: Divide and conquer. Use small, purpose-built agents, each responsible for one clearly defined job. A top-level orchestrator strings them together.
\ Why small, focused agents work
- Manageable context: shorter windows keep the model sharp.
- Clear ownership: one agent, one task, zero ambiguity.
- Higher reliability: simpler flows mean fewer places to get lost.
- Easier testing: you can unit-test each agent in isolation.
- Faster debugging: when something breaks, you know exactly where to look.
\ There’s no magic formula for when to split logic; it’s part art, part experience, and the boundary will keep shifting as models improve. A good rule of thumb: if you can’t describe an agent’s job in one or two sentences, it’s probably doing too much.
\ Checklist
- The overall workflow is a series of micro-agent calls.
- Each agent can be restarted and tested on its own.
- You can explain Agent definition in 1–2 sentences.
Most agent bugs don’t show up as red errors; they show up as weird outputs. A missed instruction. A half-followed format. Something that almost works… until it doesn’t.
\ That’s because LLMs don’t read minds. They read tokens.
\ The way you frame requests, what you pass into context, and how you write prompts, all of it directly shapes the outcome. And any mistake in that setup becomes an invisible bug waiting to surface later. This is what makes agent engineering feel unstable: ==if you’re not careful, every interaction slowly drifts off course==.
\ This section is about tightening that feedback loop. Prompts aren’t throwaway strings, they’re code. Context isn’t magic, it’s a state you manage explicitly. And clarity isn’t optional, it’s the difference between repeatable behavior and creative nonsense.
\
10 — Treat Prompts as CodeProblem: Too many projects treat prompts like disposable strings: hardcoded in Python files, scattered across the codebase, or vaguely dumped into Notion. As your agent gets more complex, this laziness becomes expensive:
- It’s hard to find, update, or even understand what each prompt does
- There’s no version control — no way to track what changed, when, or why
- Optimization becomes guesswork: no feedback loops, no A/B testing
- And debugging a prompt-related issue feels like trying to fix a bug in a comment
\ Solution: Prompts are code. They define behavior. So manage them like you would real code:
- Separate them from your logic: store them in txt, .md, .yaml, .json or use template engines like Jinja2 or BAML
- Version them with your repo (just like functions)
- Test them: (1) Unit-test responses for format, keywords, JSON validity, (2) Run evals over prompt variations, (3) Use LLM-as-a-judge or heuristic scoring to measure performance
\ Bonus: Treat prompt reviews like code reviews. If a change could affect output behavior, it deserves a second set of eyes.
\ Checklist:
- Prompts live outside your code (and are clearly named)
- They’re versioned and diffable
- They’re tested or evaluated
- They go through review when it matters
Problem: We’ve already tackled LLM forgetfulness by offloading memory and splitting agents by task. But there’s still a deeper challenge: how we format and deliver information to the model.
\ Most setups just throw a pile of role: content messages into the prompt and call it a day. That works… until it doesn’t. These standard formats often:
- Burn tokens on redundant metadata
- Struggle to represent tool chains, states, or multiple knowledge types
- Fail to guide the model properly in complex flows
\ And yet, we still expect the model to “just figure it out.” That’s not engineering. That’s vibes.
\ Solution: Engineer the context.
Treat the whole input package like a carefully designed interface, because that’s exactly what it is.
\ \ Here’s how:
- Own the full stack: Control what gets in, how it’s ordered, and where it shows up. Everything from system instructions to retrieved docs to memory entries should be intentional.
- Go beyond chat format: Build richer, denser formats. XML-style blocks, compact schemas, compressed tool traces, even Markdown sections for clarity.
- Think holistically: Context = everything the model sees: prompt, task state, prior decisions, tool logs, instructions, even prior outputs. It’s not just “dialogue history.”
\ This becomes especially important if you’re optimizing for:
- Information density: packing more meaning into fewer tokens
- Cost efficiency: high performance at low context size
- Security: controlling and tagging what the model sees
- Error resilience: explicitly signaling edge cases, known issues, or fallback instructions
\ Bottom line: Prompting is only half the battle. Context engineering is the other half. And if you’re not doing it yet, you will be once your agent grows up.
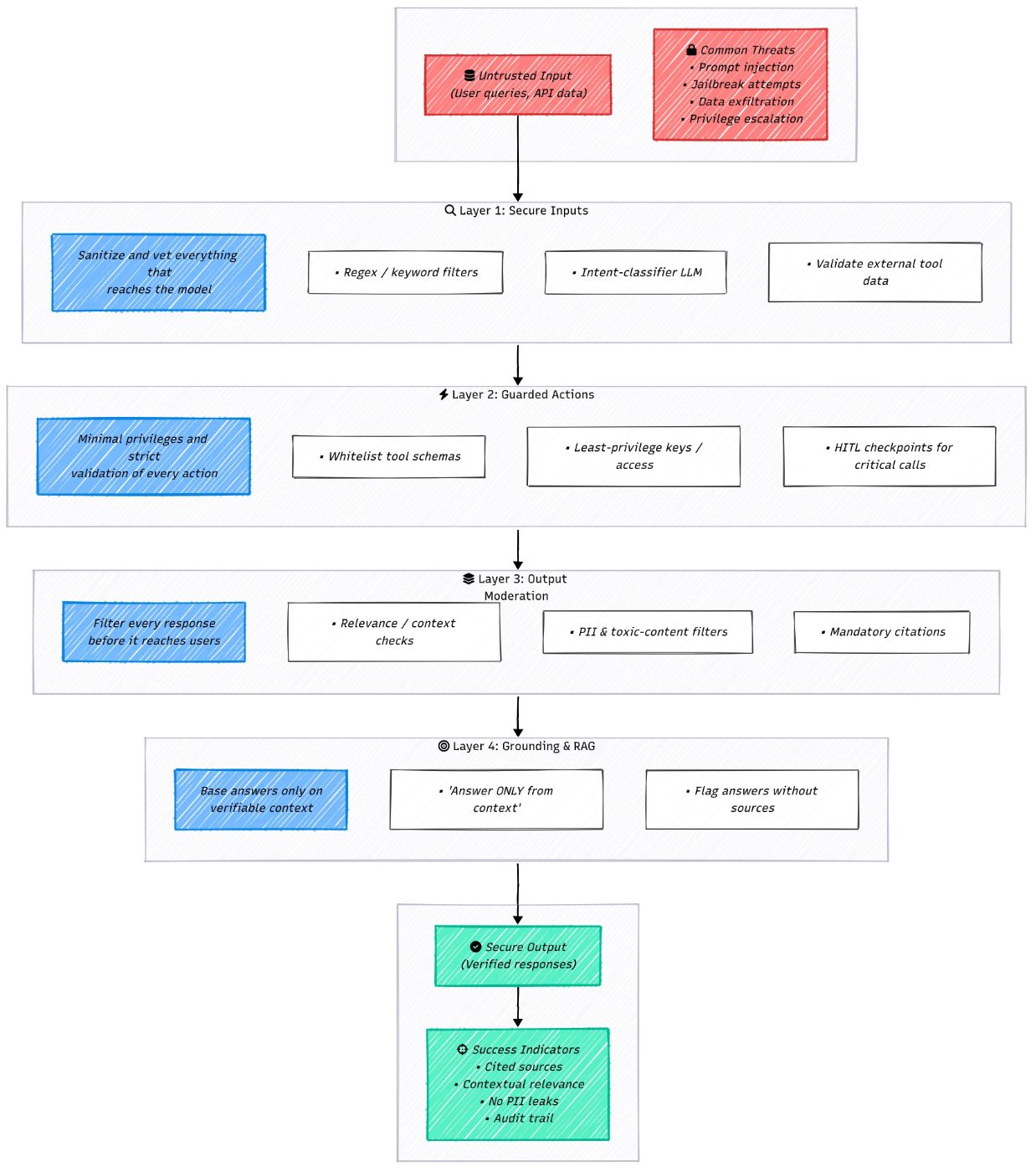
12 — Add Safety LayersEven with solid prompts, memory, and control flow, an agent can still go off the rails. Think of this principle as an insurance policy against the worst-case scenarios:
- Prompt injection: users (or other systems) slip in instructions that hijack the agent.
- Sensitive-data leaks: the model blurts out PII or corporate secrets.
- Toxic or malicious content: unwanted hate speech, spam, or disallowed material.
- Hallucinations: confident but false answers.
- Out-of-scope actions: the agent “gets creative” and does something it should never do.
\ No single fix covers all of that. You need defense-in-depth: multiple safeguards that catch problems at every stage of the request/response cycle.
\ Quick Checklist
- User input validation is in place (jailbreak phrases, intent check).
- For factual tasks, answers must reference RAG context.
- The prompt explicitly tells the model to stick to retrieved facts.
- Output filter blocks PII or disallowed content.
- Responses include a citation/link to the source.
- Agent and tools follow the least privilege.
- Critical actions route through HITL approval or monitoring.
\ Treat these layers as standard DevOps: log them, test them, and fail safe. That’s how you keep an “autonomous” agent from becoming an uncontrolled liability.
Part 4 - Keep it Working Under LoadIn production, failures rarely happen all at once, and often you don’t notice them right away, sometimes not at all.
\ This section focuses on building the engineering discipline to monitor your agent continuously, ensuring everything runs smoothly. ==From logs and tracing to automated tests, these practices make your agent’s behavior clear and dependable, whether you’re actively watching or focused on building the next breakthrough==.

\
13 — Trace the Full Execution PathProblem: Agents will inevitably misbehave during development, updates, or even normal operation. Debugging these issues can consume countless hours trying to reproduce errors and pinpoint failures. If you’ve already implemented key principles like keeping state outside and compacting errors into context, you’re ahead. But regardless, planning for effective debugging from the start saves you serious headaches later.
\ Solution: Log the entire journey from the user request through every step of the agent’s decision and action process. Individual component logs aren’t enough; you need end-to-end tracing covering every detail.
\ Why this matters:
- Debugging: Quickly identify where and why things went wrong.
- Analytics: Spot bottlenecks and improvement opportunities.
- Quality assessment: Measure how changes affect behavior.
- Reproducibility: Recreate any session precisely.
- Auditing: Maintain a full record of agent decisions and actions.
\ Minimum data to capture
- Input: User request and parameters from prior steps.
- Agent state: Key variables before each step.
- Prompt: Full prompt sent to the LLM (system instructions, history, context).
- LLM output: Raw response before processing.
- Tool call: Tool name and parameters invoked.
- Tool result: Tool output or error.
- Agent decision: Next steps or responses chosen.
- Metadata: Timing, model info, costs, code, and prompt versions.
\ Use existing tracing tools where possible: LangSmith, Arize, Weights & Biases, OpenTelemetry, etc. But first, make sure you have the basics covered (see Principle 15).
\ Checklist:
- All steps logged with full detail.
- Logs linked by session_id and a step_id.
- Interface to review full call chains.
- Ability to fully reproduce any prompt at any point.
Problem: By now, your agent might feel ready to launch: it works, maybe even exactly how you wanted. But how can you be sure it will keep working after updates? Changes to code, datasets, base models, or prompts can silently break existing logic or degrade performance. Traditional testing methods don’t cover all the quirks of LLMs:
- Model drift: performance drops over time without code changes due to model or data shifts
- Prompt brittleness: small prompt tweaks can cause big output changes
- Non-determinism: LLMs often give different answers to the same input, complicating exact-match tests
- Hard-to-reproduce errors: even with fixed inputs, bugs can be tough to track down
- The butterfly effect: changes cascade unpredictably across systems
- Hallucinations and other LLM-specific risks
\ Solution: Adopt a thorough, multi-layered testing strategy combining classic software tests with LLM-focused quality checks:
- Multi-level testing: unit tests for functions/prompts, integration tests, and full end-to-end scenarios
- Focus on LLM output quality: relevance, coherence, accuracy, style, and safety
- Use golden datasets with expected outputs or acceptable result ranges for regression checks
- Automate tests and integrate them into CI/CD pipelines
- Involve humans for critical or complex evaluations (human-in-the-loop)
- Iteratively test and refine prompts before deployment
- Test at different levels: components, prompts, chains/agents, and complete workflows
\ Checklist:
- Logic is modular and thoroughly tested individually and in combination
- Output quality is evaluated against benchmark data
- Tests cover common cases, edge cases, failures, and malicious inputs
- Robustness against noisy or adversarial inputs is ensured
- All changes pass automated tests and are monitored in production to detect unnoticed regressions
This principle ties everything together, it’s a meta-rule that runs through all others.
\ Today, there are countless tools and frameworks to handle almost any task, which is great for speed and ease of prototyping — but it’s also a trap. Relying too much on framework abstractions often means sacrificing flexibility, control, and sometimes, security.
\ That’s especially important in agent development, where you need to manage:
- The inherent unpredictability of LLMs
- Complex logic around transitions and self-correction
- The need for your system to adapt and evolve without rewriting core tasks
\ Frameworks often invert control: they dictate how your agent should behave. This can speed up prototyping but make long-term development harder to manage and customize.
\ Many principles you’ve seen can be implemented with off-the-shelf tools. But sometimes, building the core logic explicitly takes similar effort and gives you far better transparency, control, and adaptability.
\ On the other hand, going full custom and rewriting everything from scratch is over-engineering, and equally risky.
\ The key is balance. As an engineer, you consciously decide when to lean on frameworks and when to take full control, fully understanding the trade-offs involved.
\ Remember: the AI tooling landscape is still evolving fast. Many current tools were built before standards solidified. They might become obsolete tomorrow — but the architectural choices you make now will stick around much longer.
ConclusionBuilding an LLM agent isn’t just about calling APIs anymore. It’s about designing a system that can handle real-world messiness: errors, state, context limits, unexpected inputs, and evolving requirements.
\ The 15 principles we covered aren’t theory, they’re battle-tested lessons from the trenches. They’ll help you turn fragile scripts into stable, scalable, and maintainable agents that don’t break the moment real users show up.
\ ==Each principle deserves consideration to see if it fits your project. In the end, it’s your project, your goals, and your creation. But remember: the LLM is powerful, but it’s just one part of a complex system. Your job as an engineer is to own the process, manage complexity, and keep the whole thing running smoothly.==
\ If you take away one thing, let it be this: slow down, build solid foundations, and plan for the long haul. Because that’s the only way to go from “wow, it answered!” to “yeah, it keeps working.”
\ Keep iterating, testing, and learning. And don’t forget, humans in the loop aren’t a fallback, they keep your agent grounded and effective.
\ This isn’t the end. It’s just the start of building agents that actually deliver.
Struggling to grow your audience as a Tech Professional?The Tech Audience Accelerator is the go-to newsletter for tech creators serious about growing their audience. You’ll get the proven frameworks, templates, and tactics behind my 30M+ impressions (and counting).
\