and the distribution of digital products.
Additional Comparison between Single- and Two-Stage SDXL pipeline
The exponential growth of data and the increasing demand for real-time and data-driven applications have created a need for development of highly scalable and resilient database solutions. Moreover, the increase for cloud computing and shift towards distributed architectures mandate database solutions that can operate across multiple geographical regions and data centers. Traditional monolithic database architectures frequently struggle to meet the performance, availability, and cost-efficiency requirements of modern large-scale systems. According to a report by IDC, the global datasphere is projected to grow from 33 zettabytes in 2018 to 175 zettabytes by 2025, with over 49% of data stored in public cloud environments [1]. In this article, we will explore the architectural principles and strategies for building database capable of handling massive data volumes and globally distributed workloads.
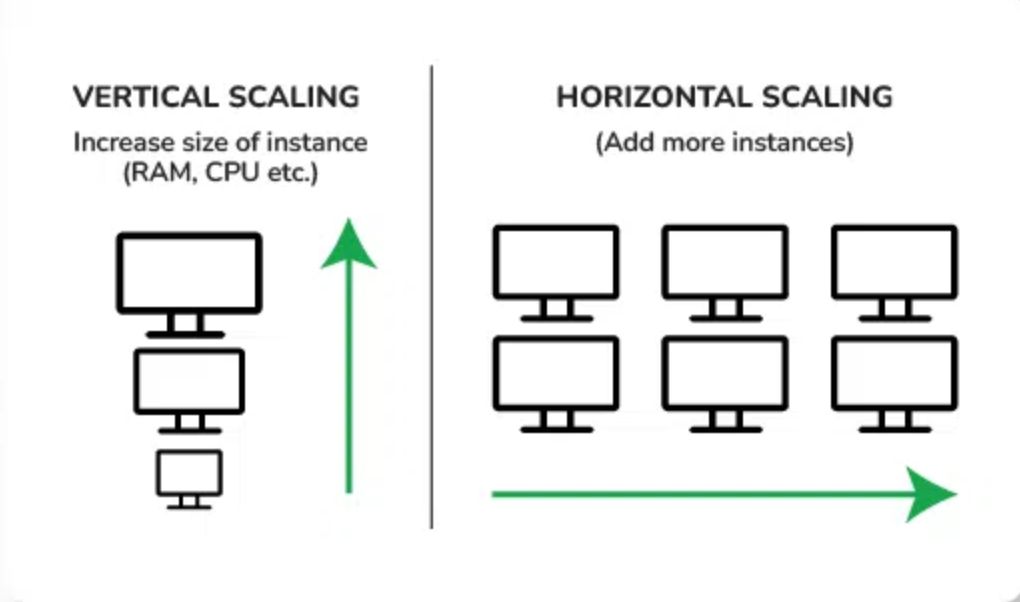
Horizontal Scaling vs Vertical ScalingTraditional database architectures were designed for single-node deployment and vertical scaling and often struggle to meet the demands of large-scale systems. Vertical scaling involves upgrading hardware resources on a single node by adding resources like memory, storage, and processing power to existing software, to enhance its performance. It’s also referred as Scale-up approach. Vertical scaling has some practical limitations like cost and scalability. They also lack the necessary resilience and fault tolerance mechanisms to withstand failures, network partitions and other disruptions.
\ Horizontal Scaling adds more database nodes to handle the increased workload. It decreases the load on the server rather than expanding the individual servers. When you need more capacity, you can add more servers to the cluster. It’s also referred as Scale-out approach. Horizontal scaling is easy to upgrade, costs less and you can easily switch out fault nodes. Large-scale systems require a fundamental shift from traditional vertical scaling approach to horizontal scaling. This approach distributes the data and computational load across a cluster of commodity servers, enabling linear scalability and fault tolerance. It also enables partitioning of data across multiple nodes also referred as Sharding. Studies have shown that sharding can significantly improve database performance, with gains of up to 50% or more, depending on the workload and data distribution [2].
\
\ Sharding strategies can vary depending on the data access patterns and data consistency requirements. One common technique includes range-based sharding, which partitions data based on a range of values (e.g., date ranges). Another approach includes directory-based sharding, which employs a separate lookup service to map data to its corresponding shard. But the most widely used approach is hash-based sharding, which uses a hash function to distribute data evenly across shards. Has-based sharding provides a faster look-up for database entries. The ultimate choice of sharding strategy depends on your application needs and is critical decision as it can impact system performance, response time and operational complexity.
Designing for FailuresIn large-scale systems, data replication plays a key role in ensuring availability and fault tolerance. You can maintain multiple copies of data across different nodes or geographical regions so that the system can operate even in the event of node failures or network partitions. You can choose between synchronous replication strategy, where data is written to multiple replicas simultaneously or asynchronous, where replicas are eventually updated after the initial write operation. According to a study by Google, their globally distributed database system, Spanner, achieves an impressive 99.999% availability by combining synchronous replication within data centers and asynchronous replication across sites [3].
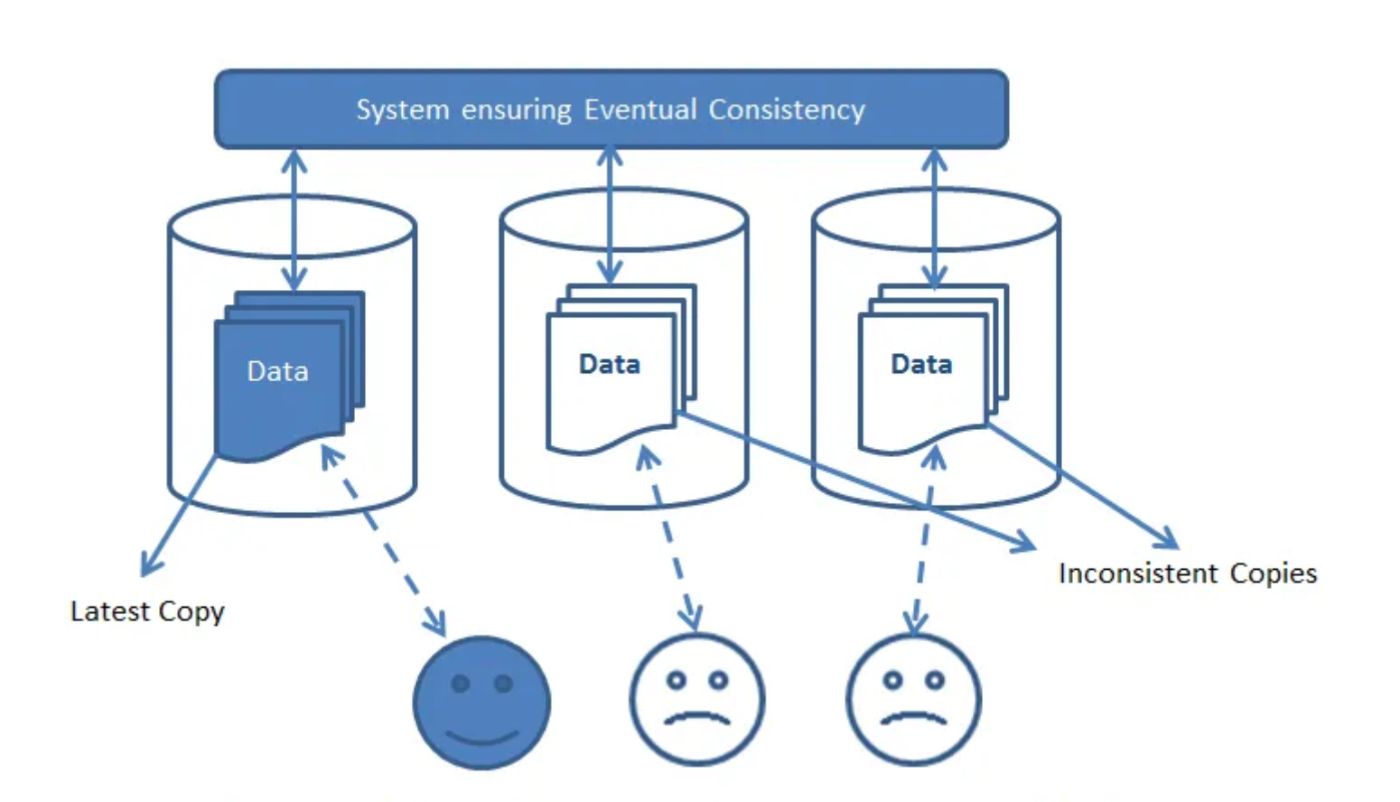
Eventual ConsistencyConsistency models, such as strong consistency (e.g., using consensus protocols like Paxos or Raft) and eventual consistency (e.g., using conflict-free replicated data types, CRDTs), govern how data is replicated and reconciled across replicas. The choice of consistency model depends on the specific application requirements, striking a delicate balance between data integrity, performance, and availability. Its best to use eventual consistency if your system can handle it as not all nodes need to be in the same state after every single operation for example updating product inventory count between two system, you can let you customers order a product and then tally remaining stock. Strong consistency is absolutely required for financial/banking transactions or payment applications, as all database nodes in your system should be consistent all the time. If you look closely, most applications can make leverage eventual consistency. Research by Yahoo showed that eventual consistency can provide up to 10x higher throughput compared to strong consistency models, while maintaining acceptable data correctness for certain workloads [4].
\
\
Achieve faster response with nothing but CachingCaching mechanisms are essential for improving read performance and reducing the load on the database storage layer. Caching can occur at various levels, including in-memory caches (e.g., Redis, Memcached), content delivery networks (CDNs), and reverse proxies. Effective cache invalidation strategies, such as time-to-live (TTL) expiration or cache busting techniques, are crucial for ensuring data consistency between the cache and the underlying database storage. According to a study by Facebook, their Tao caching system reduced database load by up to 95% for certain workloads [5], underscoring the significant performance gains that can be achieved through intelligent caching strategies.
\ Data access patterns, such as read-heavy or write-heavy workloads, also influence the architectural decisions for database storage. Read-heavy workloads may benefit from caching and replication strategies that prioritize read performance, while write-heavy workloads may require optimizations for write throughput and consistency guarantees. Identifying and understanding these patterns is essential for tailoring the database storage architecture to meet the specific needs of the application.
Leveraging Managed Service ArchitectureCloud-native architectures and managed database services offer powerful tools for building scalable database storage solutions. Containerization technologies like Docker and orchestration platforms like Kubernetes enable seamless deployment, scaling, and management of database clusters across multiple nodes or cloud environments. A study by Google demonstrated that their Kubernetes-based database platform, Cloud SQL, could automatically scale from 10 to 100 nodes within minutes, handling up to 1.5 million queries per second [6] – a feat that would be challenging, if not impossible, with traditional database architectures.
\ Managed database services, such as Amazon RDS, Google Cloud SQL, and Azure SQL Database, abstract away many of the operational complexities associated with database management, freeing developers to focus on application logic. These services often provide built-in features for scalability, high availability, and automated backups, reducing the overall complexity of building and maintaining large-scale database storage. By leveraging managed services, organizations can benefit from the expertise and resources of cloud providers, while reducing the operational burden on their internal teams.
Continuous Monitoring & Disaster RecoveryMonitoring and observability are important for detecting and resolving issues quickly. Comprehensive monitoring solutions should track key performance indicators (KPIs) such as latency, throughput, and resource utilization, enabling timely identification of bottlenecks and performance degradation. Research by Dropbox revealed that their monitoring system, which collects over 20 billion metrics per day, helped reduce incident detection time from hours to minutes [7], underscoring the critical role of effective monitoring in minimizing system downtime and ensuring optimal performance.
\ Observability tools, like distributed tracing and log aggregation, provide invaluable insights into the behavior of complex distributed systems, aiding in root cause analysis and troubleshooting. These tools enable developers and operators to understand the intricate interactions and dependencies between various components of the system, facilitating rapid identification and resolution of issues.
\ Furthermore, robust disaster recovery strategies, including data backups, failover mechanisms, and recovery plans, are essential for ensuring business continuity in the face of catastrophic failures or data loss incidents. A study by AWS showed that their Elastic Disaster Recovery service could restore a 16TB database in under 60 minutes, with minimal data loss [8], demonstrating the importance of having a comprehensive disaster recovery plan in place for large-scale database storage systems.
ConclusionBuilding scalable database storage for large-scale systems requires a holistic approach that considers factors such as horizontal scaling, data replication, caching, monitoring, and disaster recovery. By embracing horizontal scaling through sharding and distribution across commodity servers, organizations can achieve linear scalability and fault tolerance to handle ever-increasing data volumes and user demands. Continuous monitoring and disaster recovery practices are essential for maintaining the resilience of the systems As the data volumes and user demands continue to grow, the principles and strategies outlined in this article will remain fundamental to architecting scalable and high-performance database storage solutions. Continuous evaluation, adaptation, and innovation will be necessary to stay ahead of the curve in this rapidly evolving landscape.
References:[1] Reinsel, D., Gantz, J., & Rydning, J. (2018). The Digitization of the World: From Edge to Core. IDC White Paper. https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf
\
[2] Sumbaly, R., Kreps, J., Gao, L., Feinberg, A., Soman, C., & Shah, S. (2012). Serving large-scale batch computed data with Project Voldemort. In Proceedings of the 10th USENIX conference on File and Storage Technologies. https://static.usenix.org/events/fast12/tech/full_papers/Sumbaly.pdf
\
[3] Corbett, J. C., Dean, J., Epstein, M., Fikes, A., Frost, C., Furman, J. J., … & Zwicky, E. (2012). Spanner: Google's globally distributed database. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI'12). https://www.usenix.org/system/files/conference/osdi12/osdi12-final-16.pdf
\
[4] Cooper, B. F., Ramakrishnan, R., Srivastava, U., Silberstein, A., Bohannon, P., Jacobsen, H. A., & Yerneni, R. (2008). PNUTS: Yahoo!'s hosted data serving platform. Proceedings of the VLDB Endowment, 1(2), 1277-1288. https://sites.cs.ucsb.edu/~agrawal/fall2009/PNUTS.pdf
\
[5] Bronson, N., Amsden, Z., Cabrera, G., Chakka, P., Dimov, P., Ding, H., … & Xu, L. (2013). TAO: Facebook's distributed data store for the social graph. In Presented as part of the 2013 USENIX Annual Technical Conference (USENIX ATC'13). http://0b4af6cdc2f0c5998459-c0245c5c937c5dedcca3f1764ecc9b2f.r43.cf2.rackcdn.com/11730-atc13-bronson.pdf
\
[6] Google Cloud Platform. (2022). Cloud SQL: Fully managed relational databases. https://console.cloud.google.com/marketplace/product/google-cloud-platform/cloud-sql
\
[7] Dropbox. (2021). Scaling Monitoring at Dropbox. https://dropbox.tech/infrastructure/lessons-learned-in-incident-management
\
[8] Amazon Web Services. (2022). AWS Elastic Disaster Recovery. https://aws.amazon.com/disaster-recovery/
\