and the distribution of digital products.
5 Valuable Tips on How to Prevent the Most Common Errors in Test Automation
\ Ever wished you could make test automation a breeze? Quickly spotting and fixing issues without endless debugging or script maintenance? Yeah, me too. It's the dream of every QA pro out there, but let's face it – it's usually just that, a dream.
\ As someone who runs a company making QA tools, I've learned that fancy tech isn't the whole story. What really counts is the know-how behind it. That's why my team at Zebrunner and I bring together top QA experts from around the world and provide them with a platform to share their insights.
\ One of our guests was Senior Principal Automation Architect Paul Grizzaffi. In this article, I'll break down the key insights from his presentation, offering you practical strategies you can implement in your own projects. Whether you're a seasoned QA professional or just starting out, these tips should help elevate your testing approach..
About the speakerPaul Grizzaffi, Senior Principal Automation Architect
\

As a Senior Principal Automation Architect, Paul Grizzaffi is passionate about providing technology solutions to testing, QE, and QA organizations. His expertise includes automation assessments, implementations, and activities benefiting the broader testing community. An accomplished keynote speaker and writer, Paul has presented at both local and national conferences and meetings. He is a member of the Industry Advisory Board of the Advanced Research Center for Software Testing and Quality Assurance (STQA) at UT Dallas, where he is a frequent guest lecturer.
\n You can follow Paul on LinkedIn, X, and his blog.
What is the product of test automation?Automation is software, whether it’s record and playback, drag and drop, AI-generated, or code written in JavaScript, C#, Python, or any other language. It’s all software. Once we understand that the software is performing tasks for us, we recognize that the software itself is a product.
\ Think about an e-commerce app. The app isn’t the product; the product is the laundry detergent you want to order. No one really wants software; what you want is the convenience of having your laundry detergent delivered to your door. We’re not there yet in terms of instant delivery, but the point is, the software is not the product. The product is what you get from using the software.
\ So, what is the product of automation? What does an app deliver? An app is software, and so is automation, which will be a recurring theme in our discussion. However, the end product of automation is different. We’re not receiving laundry detergent or a doctor’s appointment. Instead, we’re getting information.
\ The purpose of automation is to help testers be more effective or efficient at their job, ideally both. Their job is to uncover potential risks. Automation helps answer: “Here’s what we did” or “Here’s what we didn’t do” or “Here’s what we think we should do”. Decision-makers use this information to decide whether to continue testing or release the software.
\ The purpose of automation is to produce information faster, aiding decision-makers in evaluating the quality of the product they plan to deliver. Therefore, the product of test automation is valuable information, presented in the form of logs and reports. These documents detail what happened, what didn’t happen, and what the software thinks happened. There may be a disconnect between what we think the software is doing and what it is actually doing, but we’ll set that aside for now.
#1. Follow the three “ables” for test automationTo make automation valuable, it must provide value.
\ By following the three “ables” of automation and reporting, it's more likely to be valuable. Here, valuable means providing the information needed from a tester's standpoint to decide on the next steps, such as moving on to the next task, spending more time on a current task, or identifying areas that need attention. The three ables for test automation are:
\ Available. Availability seems obvious, yet Paul has encountered a client whose test automation initiative failed partly because the reporting and logging were not accessible. “What do I mean by not available? The logs were stored in a place inaccessible to those who needed them. While it may seem trivial with tools like Jenkins or Azure DevOps, ensuring that everyone knows where the logs are and has the necessary licenses and authorization to access them is essential. Without this, the logs become useless because they cannot be acted upon,” clarified Paul Grizzaffi.
\
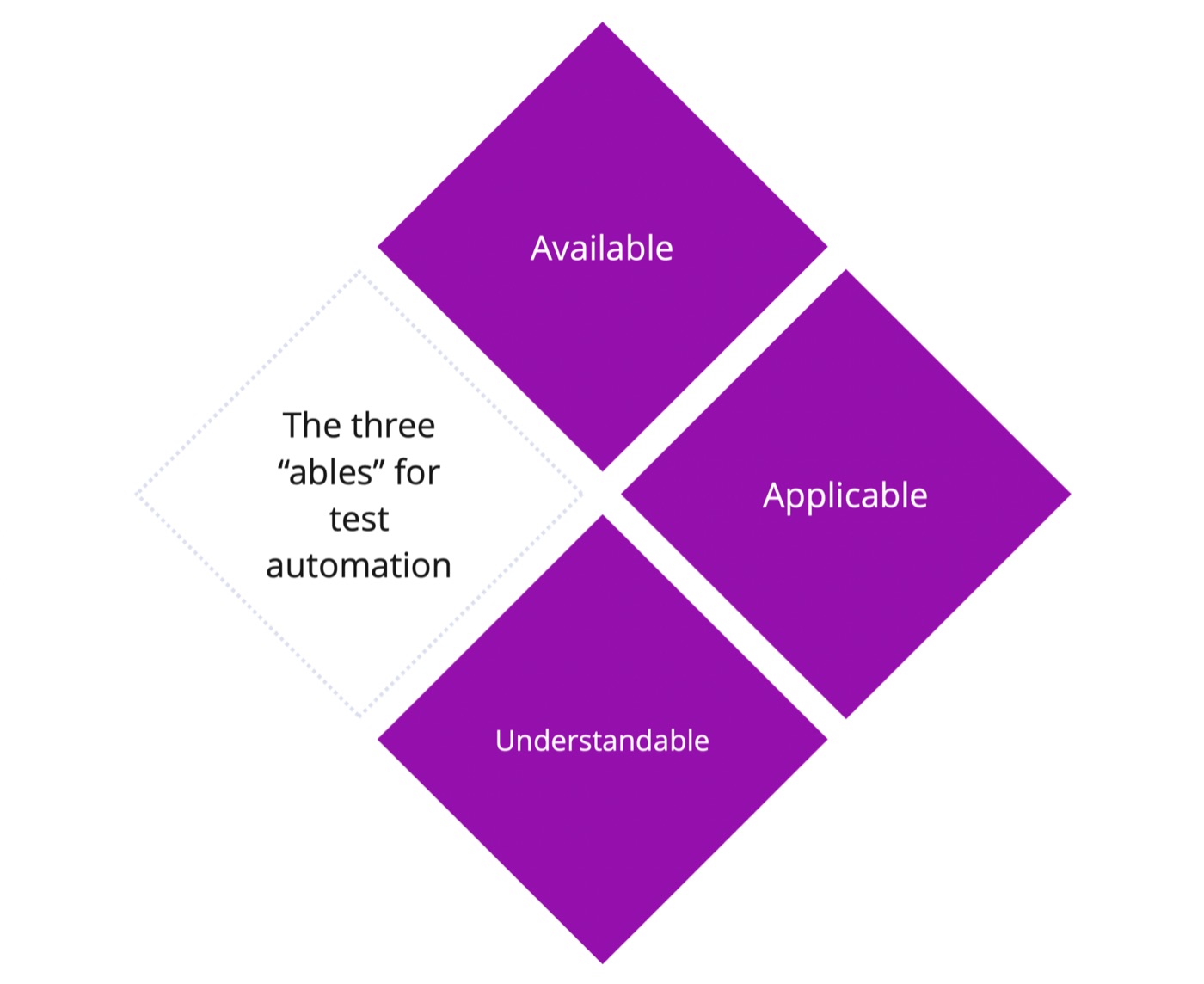
Applicable. Logs must also be applicable. In automation, we often either log too much, making it hard to sift through the information, or log too little, leaving us without crucial details when issues arise. Finding the balance between logging too much and too little is context-dependent. Some teams need more detailed logs, while others need less. Even within a team, the level of detail required can vary depending on the situation. Typically, you may need a certain amount of detail, but for specific problems, additional detail might be necessary. Striking a balance between providing enough information to be useful and making it digestible for typical cases is crucial.
\ Understandable. Lastly, logs must be understandable. Those working in test automation, who deal with the intricate details, can interpret messages like "HTML element XYZ didn’t exist," "wasn’t clickable," or "was behind another element." However, not everyone consuming these results has the expertise to understand such technical jargon. Creating logs in a vocabulary that more people can understand, while still allowing lower-level details to be accessible for those who need them, is a good balancing act.
\ It’s important to remember that logs are only valuable if they provide meaningful information, which is context-dependent. What’s valuable for one team might be noise for another, and vice versa.
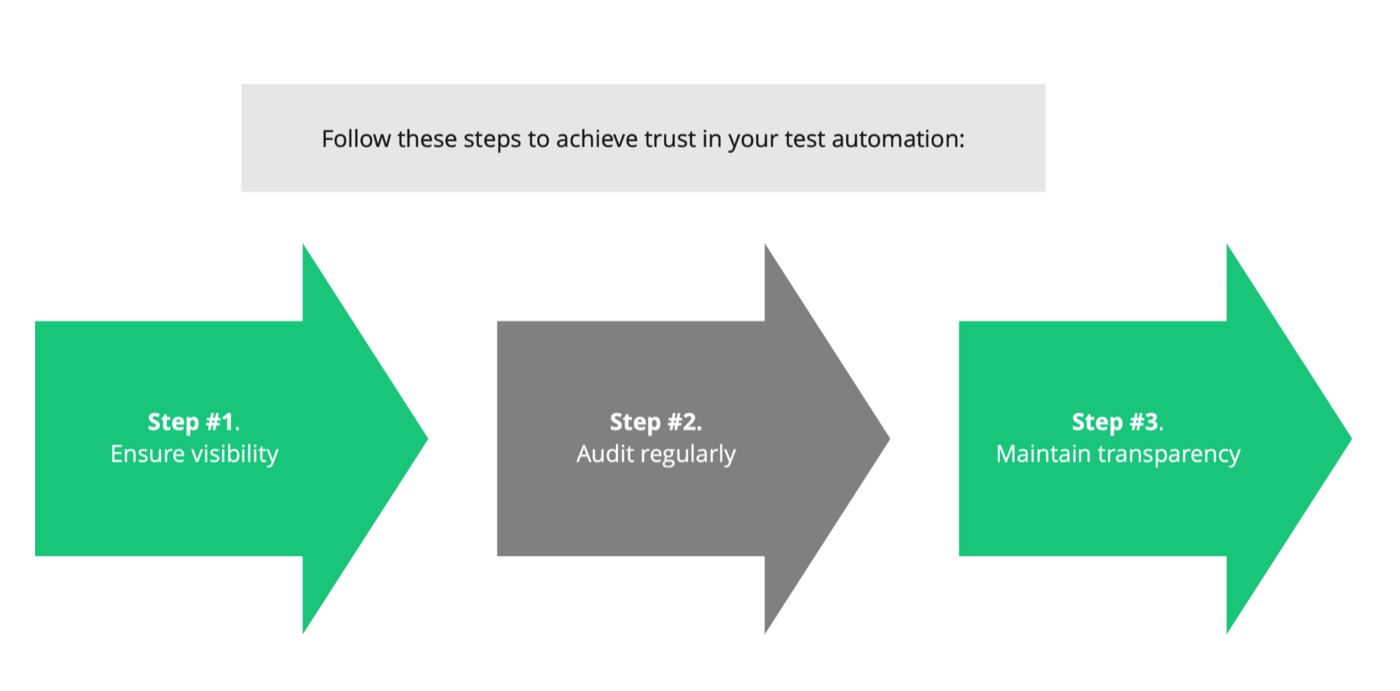
#2. Trust your test automationLogs are your bridge between what the machine is doing for you and what you would normally do manually. Therefore, trust is essential. If you don’t trust your automation, you might still run it, but you'll likely double-check many things, rerunning some tasks by hand. This diminishes the value of your automation because if you have to redo tasks that the automation was supposed to handle, its value is compromised. Thus, you need to have a certain level of trust – a "trust but verify" approach. Periodically auditing your automation ensures it is performing as expected. Without trust, the automation's value is diminished.
Here are two key components in building trust in your test automation:
\
- Visibility. Visibility is the number one way to build trust. Understand what the automation is doing by making the code and logs available. Include sufficient details in the logs to know exactly what actions the automation is performing. For instance, logs should show actions such as "I clicked this," "I sent this message," "I received this response," and other relevant information. This way, if something seems off, you can review the logs to determine whether the automation is at fault or if your assumptions are incorrect.
- Transparency in logs. Logs should clearly show what happened and what didn’t happen. If something is not in the log, it might not have happened, which is another aspect of trust. Transparency is crucial because without trust, there will be no value. If you don’t trust the automation, you won’t rely on it, leading you to redo the tasks manually. This defeats the purpose of investing time, effort, and money into creating the automation in the first place.
Finding issues takes effort. When something goes wrong in the system or the application, you need to determine what happened. Without detailed logs, you might spend considerable time digging through application and automation logs without finding any clues. This results in extensive time spent on debugging, triaging, and attempting to reproduce issues. Good logs can help you identify the problem faster.
\ Fixing issues also requires effort, as does testing the fixes. Every hour spent on these activities is an opportunity cost because it’s time not spent on other tasks that could reduce costs or generate revenue for the company. Thus, minimizing the effort required to track down issues is beneficial. Proper logs facilitate this process, making debugging and error reporting more efficient and effective.
\ So, appropriate logging can reduce costs by:
\ Enhancing issue detection: Quickly pinpointing what went wrong.
Minimizing debugging time: Reducing the time spent on identifying and fixing issues.
Lowering opportunity costs: Allowing team members to focus on other value-adding tasks.
#4. Apply “good logs”"Good" logs for one team might not be good for another. Instead of "good," we should use "appropriate." What logs are appropriate for this product, this team, this organization, and this company? The goal is to meet our business objectives, support the testers, and enable developers to write code that aligns with business goals. \n
So, what do good logs look like?
\ Just enough information:
Provide all necessary information for the problem at hand – nothing more, nothing less. While the ideal balance is rare, aim to either log extensively but make it filterable, or log minimally but ensure crucial details are captured.
\ Filterable:
Log extensively but allow for filtering based on severity or detail level. This approach helps during debugging, especially for intermittent failures due to interconnected systems and third-party dependencies.
\ Guidance for debugging:
Logs should indicate what was done and what the expected outcome was. For example, "I sent a 12 and expected a 4, but got a 3." This provides clues for where to start debugging, such as a calculation error or a communication issue with a third party.
\ Meaningful and actionable information:
Ensure logs are understandable and actionable for whoever needs to use them. Avoid requiring users to consult a catalog to decipher log entries. Instead, provide clear and concise information like "Error 304 means this specific issue."
\ Visual logs:
In GUI automation, visual logs can be particularly helpful. Screenshots showing discrepancies between expected and actual UI states provide immediate clarity and context for debugging.
\ Example. Imagine working with a client dealing with intermittent issues. Turning on additional logging in specific parts of the application can provide new insights without needing to reproduce the issue repeatedly. This saves time and effort, making the debugging process more efficient.
\ Paul provides further clarification on what "good" logs look like:
\ “I'm a music guy, and of course, you can never have too many copies of Ozzy's "Bark at the Moon." Imagine I want to buy "Bark at the Moon" again, but the transaction fails. Something in my test script caused the add-to-cart function to fail. Imagine having logs that simply state, "Failed to add 'Bark at the Moon' to the cart." While somewhat helpful, more details would be beneficial”.
\ For instance, if you get a screenshot along with the log, you might see that the "add to cart" button is missing. If it’s not visible, you need more detail. A deeper log might indicate, "Couldn't find the 'add to cart' button when trying to click it." This tells you the test attempted to click the button, but the tool couldn’t find it. Why? The specific web element with a particular ID couldn’t be located.
\ Some team members might only understand the initial log entry. They would need to escalate the issue for further analysis. Others might understand the additional log detail and the screenshot but not have enough HTML knowledge to resolve the issue. They might also need assistance. However, for those who work across multiple levels of the testing pyramid, having comprehensive logs is invaluable. These logs allow us to investigate deeply: Was the element there but the tool missed it? Did the ID change? With detailed logs, we can answer these questions without trying to reproduce the issue repeatedly.
\ Imagine this process expanded over hundreds or thousands of tests, or an entire suite of API tests. Logging exactly what you send and receive helps identify failures quickly. If you get unexpected responses, like a 404 error, detailed logs let you debug the issue immediately without rerunning the tests.
Recommendations for practitioners on how to work with logs: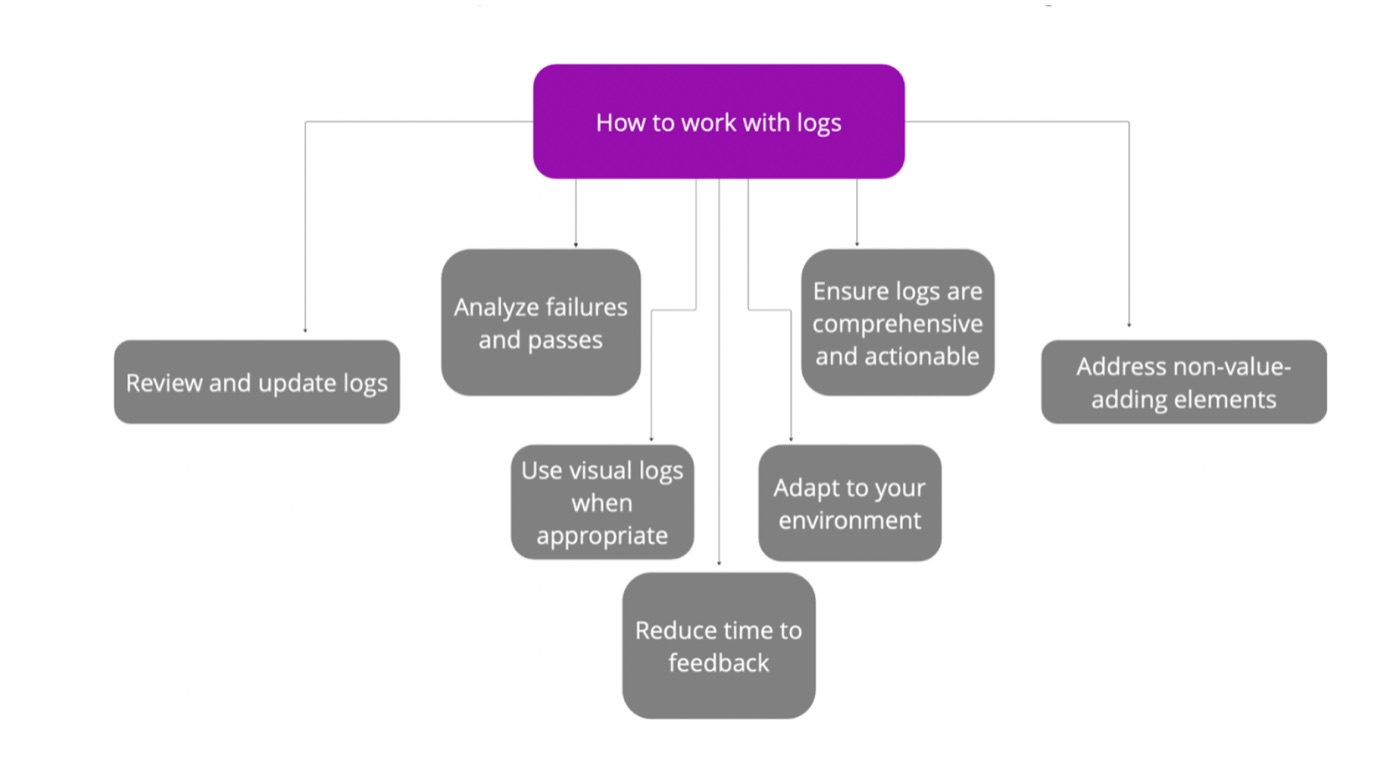
Review and update your logs. Regularly review the logs from your test automation runs. During code reviews, assess if the logs provide clear information. If you're unsure about what happened between certain steps, increase the logging level or add more logs.
\ Analyze failures and passes. Focus on both failures and passes. Ensure that logs for passes indicate that the checks are still relevant and comprehensive.
\ Ensure logs are comprehensive and actionable. Logs should provide actionable information. For example, "Expected 4 but got 3" is actionable. Avoid logs that require consulting external references to understand the issue.
\ Use visual logs when appropriate. In GUI automation, incorporate screenshots to show discrepancies between expected and actual states.
\ Adapt to your environment. Use logging practices appropriate for your tools, team, and organization. If your tool provides all necessary information, additional logging may not be required.
\ Address non-value-adding elements. Remove or fix test scripts and logs that don’t add value. Ineffective logs or tests contribute to failure fatigue and increase debugging time.
\ Reduce time to feedback. Treat logs as a means to reduce time to feedback. How quickly can you learn something valuable about your product? The better your logs, the quicker you can identify and address issues, accelerating your time to market.
#5. Find your ideal test automation tool"Once at a conference, a vendor posed a question that caught me off guard: 'What would you want if you were designing a test automation tool?' It was a thought-provoking question, one that I hadn't prepared a full talk on at the time. However, over the years, my thoughts on what I want and need from such a tool, particularly in terms of logging, have evolved significantly," Paul recalled. \n
So, what does an ideal test automation tool look like for a high-level professional like Paul Grizzaffi?
\ Centralized logging. Ideally, the vision involves a tool or suite of tools capable of aggregating logs from various sources – test automation, the product under test, and third-party integrations. Imagine having all these logs synchronized in one place. When encountering an issue or anomaly, synchronized logs can be reviewed to trace the sequence of events: what happened in automation, how the product responded, and the interactions with third parties. Such synchronized logs could reveal discrepancies or mismatches between expected and actual behaviors across these components.
\ Root cause identification. In a previous role, we utilized an in-house tool that performed thousands of calculations, comparing them against expected results. Despite its utility, we faced challenges when data inconsistencies arose due to changes in calculation rules. The tool, while comprehensive, required manual investigation to pinpoint whether discrepancies were due to data mismatches or coding errors. A more advanced tool could categorize failures, suggesting prioritization – flagging data mismatches for immediate attention while highlighting potential calculation or coding errors for further investigation.
\ Failure trends and predictive insights. Another crucial feature would be the ability to analyze failure trends and identify recurring problem areas. With access to historical data from multiple test runs or releases, the tool could leverage AI or statistical analysis to pinpoint critical areas needing more testing or development attention. Predictive insights could warn of potential failure causes based on past patterns – alerting teams to script errors, tool issues, or genuine product defects before they impact operations.
Takeaways- Remember, in this environment, if you treat automation as software, as you should, information becomes the product. We must create logs that deliver information in a manner that is appropriate, digestible, and usable.
- Keep in mind the three "ables" (available, applicable, and understandable) when it comes to your logs and reports.
- Consider reducing the time to feedback: how quickly can action be taken on these logs to understand what's happening? Reducing the time to feedback will shorten the time to fix issues and reduce the opportunity cost.
- Trust is absolutely essential. If you don’t trust your automation, you won’t use it effectively, and it won’t be effective for you. Appropriate logs can help build trust because they provide a clear trail of breadcrumbs about what the scripts and tools did or did not do.
\