and the distribution of digital products.
Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 3): Server-Side Task Submission
This is the last piece of the series articles to analyze the Apache SeaTunnel Zeta Engine Source Code; review the previous series to get the full picture:
- Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 1): Server Initialization
- Source Code Analysis of Apache SeaTunnel Zeta Engine (Part 2): Task Submission Process on the Client Side
\ Let's review the components that execute after the server starts:
- CoordinatorService: Enabled only on master/standby nodes, listens to cluster status, and handles master-standby failovers.
- SlotService: Enabled on worker nodes, periodically reports its status to the master.
- TaskExecutionService: Enabled on worker nodes, periodically updates task metrics to IMAP.
\ When no tasks are received by the cluster, these components run. However, when a client sends a SeaTunnelSubmitJobCodec message to the server, how does the server handle it?
Message ReceptionSince the client and server are on different machines, method calls cannot be used; instead, message passing is employed. Upon receiving a message, how does the server process it?
\ Firstly, the client sends a message of type SeaTunnelSubmitJobCodec:
// Client code ClientMessage request = SeaTunnelSubmitJobCodec.encodeRequest( jobImmutableInformation.getJobId(), seaTunnelHazelcastClient .getSerializationService() .toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint()); PassiveCompletableFutureIn the SeaTunnelSubmitJobCodec class, it is associated with a SeaTunnelMessageTaskFactoryProvider class, which maps message types to MessageTask classes. For SeaTunnelSubmitJobCodec, it maps to the SubmitJobTaskclass:
\
private final Int2ObjectHashMap\ When examining the SubmitJobTask class, it invokes the SubmitJobOperation class:
@Override protected Operation prepareOperation() { return new SubmitJobOperation( parameters.jobId, parameters.jobImmutableInformation, parameters.isStartWithSavePoint); }\ In the SubmitJobOperation class, the task information is handed over to the CoordinatorService component via its submitJob method:
@Override protected PassiveCompletableFuture doRun() throws Exception { SeaTunnelServer seaTunnelServer = getService(); return seaTunnelServer .getCoordinatorService() .submitJob(jobId, jobImmutableInformation, isStartWithSavePoint); }At this point, a client message is effectively handed over to the server for method invocation. Other types of operations can be traced in a similar manner.
CoordinatorServiceNext, let’s explore how CoordinatorService handles job submissions:
public PassiveCompletableFutureIn the server, a JobMaster object is created to manage the individual task. During the JobMaster creation, it retrieves the resource manager via getResourceManager() and job history information via getJobHistoryService(). The jobHistoryService is initialized at startup, while ResourceManager is lazily loaded upon the first task submission:
/** Lazy load for resource manager */ public ResourceManager getResourceManager() { if (resourceManager == null) { synchronized (this) { if (resourceManager == null) { ResourceManager manager = new ResourceManagerFactory(nodeEngine, engineConfig) .getResourceManager(); manager.init(); resourceManager = manager; } } } return resourceManager; } ResourceManagerCurrently, SeaTunnel supports only standalone deployment. When initializing ResourceManager, it gathers all cluster nodes and sends a SyncWorkerProfileOperation to get node information, updating the internal registerWorker state:
@Override public void init() { log.info("Init ResourceManager"); initWorker(); } private void initWorker() { log.info("initWorker... "); List aliveNode = nodeEngine.getClusterService().getMembers().stream() .map(Member::getAddress) .collect(Collectors.toList()); log.info("init live nodes: {}", aliveNode); ListPreviously, we observed that SlotService sends heartbeat messages to the master from each node periodically. Upon receiving these heartbeats, the ResourceManager updates the node statuses in its internal state.
\
@Override public void heartbeat(WorkerProfile workerProfile) { if (!registerWorker.containsKey(workerProfile.getAddress())) { log.info("received new worker register: " + workerProfile.getAddress()); sendToMember(new ResetResourceOperation(), workerProfile.getAddress()).join(); } else { log.debug("received worker heartbeat from: " + workerProfile.getAddress()); } registerWorker.put(workerProfile.getAddress(), workerProfile); } JobMasterIn the CoordinatorService, a JobMaster instance is created and its init method is called. When the init method is completed, it is considered that the task creation is successful. The run method is then called to formally execute the task.
\ Let's look at the initialization and init method.
public JobMaster( @NonNull Data jobImmutableInformationData, @NonNull NodeEngine nodeEngine, @NonNull ExecutorService executorService, @NonNull ResourceManager resourceManager, @NonNull JobHistoryService jobHistoryService, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull IMap ownedSlotProfilesIMap, @NonNull IMapDuring initialization, only simple variable assignments are performed without any significant operations. We need to focus on the init method.
public synchronized void init(long initializationTimestamp, boolean restart) throws Exception { // The server receives a binary object from the client, // which is first converted to a JobImmutableInformation object, the same object sent by the client jobImmutableInformation = nodeEngine.getSerializationService().toObject(jobImmutableInformationData); // Get the checkpoint configuration, such as the interval, timeout, etc. jobCheckpointConfig = createJobCheckpointConfig( engineConfig.getCheckpointConfig(), jobImmutableInformation.getJobConfig()); LOGGER.info( String.format( "Init JobMaster for Job %s (%s) ", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId())); LOGGER.info( String.format( "Job %s (%s) needed jar urls %s", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls())); ClassLoader appClassLoader = Thread.currentThread().getContextClassLoader(); // Get the ClassLoader ClassLoader classLoader = seaTunnelServer .getClassLoaderService() .getClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); // Deserialize the logical DAG from the client-provided information logicalDag = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, jobImmutableInformation.getLogicalDag()); try { Thread.currentThread().setContextClassLoader(classLoader); // Execute save mode functionality, such as table creation and deletion if (!restart && !logicalDag.isStartWithSavePoint() && ReadonlyConfig.fromMap(logicalDag.getJobConfig().getEnvOptions()) .get(EnvCommonOptions.SAVEMODE_EXECUTE_LOCATION) .equals(SaveModeExecuteLocation.CLUSTER)) { logicalDag.getLogicalVertexMap().values().stream() .map(LogicalVertex::getAction) .filter(action -> action instanceof SinkAction) .map(sink -> ((SinkAction) sink).getSink()) .forEach(JobMaster::handleSaveMode); } // Parse the logical plan into a physical plan final Tuple2\ Lastly, let's look at the run method:
public void run() { try { physicalPlan.startJob(); } catch (Throwable e) { LOGGER.severe( String.format( "Job %s (%s) run error with: %s", physicalPlan.getJobImmutableInformation().getJobConfig().getName(), physicalPlan.getJobImmutableInformation().getJobId(), ExceptionUtils.getMessage(e))); } finally { jobMasterCompleteFuture.join(); if (engineConfig.getConnectorJarStorageConfig().getEnable()) { ListThis method is relatively straightforward, calling physicalPlan.startJob() to execute the generated physical plan.
\ From the above code, it is evident that after the server receives a client task submission request, it initializes the JobMasterclass, which generates the physical plan from the logical plan, and then executes the physical plan.
\ Next, we need to delve into how the logical plan is converted into a physical plan.
Conversion From Logical Plan to Physical PlanThe generation of the physical plan is done by calling the following method in JobMaster:
final Tuple2In the method for generating the physical plan, the logical plan is first converted into an execution plan, and then the execution plan is converted into a physical plan.
\
public static Tuple2The ExecutionPlanGenerator class takes a logical plan and produces an execution plan through a series of steps, including generating execution edges, shuffle edges, transform chain edges, and finally, pipelines.
Generation of the Physical PlanThe PhysicalPlanGenerator class converts the execution plan into a physical plan:
public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.executionPlan = executionPlan; this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public PhysicalPlan generate() { List\ Let's examine the contents of these two classes.
public class ExecutionPlan { private final List\ Let's compare it with the logical plan:
public class LogicalDag implements IdentifiedDataSerializable { @Getter private JobConfig jobConfig; private final SetIt seems that each Pipeline resembles a logical plan. Why do we need this transformation step? Let’s take a closer look at the process of generating a logical plan.
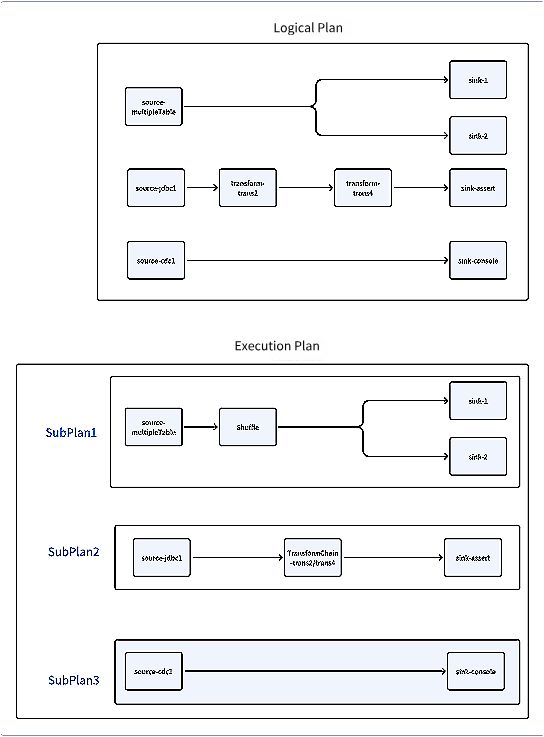
\ As shown above, generating an execution plan involves five steps, which we will review one by one.
- Step 1: Converting Logical Plan to Execution Plan
- Step 2
The Shuffle step addresses specific scenarios where the source supports reading multiple tables, and there are multiple sink nodes depending on this source. In such cases, a shuffle node is added in between.
Step 3 private Set- Step 5
Step five involves generating the execution plan instances, passing the Pipeline parameters generated in step four.
Summary:The execution plan performs the following tasks on the logical plan:
When a source generates multiple tables and multiple sink nodes depend on this source, a shuffle node is added in between.
Attempt to chain merge transform nodes, combining multiple transform nodes into one node.
Split the tasks, dividing a configuration file/LogicalDag into several unrelated tasks represented as List
. 
\
Physical Plan GenerationBefore delving into physical plan generation, let's first review what information is included in the generated physical plan and examine its internal components.
public class PhysicalPlan { private final List\ In this class, a key field is pipelineList, which is a list of SubPlan instances:
public class SubPlan { private final int pipelineMaxRestoreNum; private final int pipelineRestoreIntervalSeconds; private final List\ The SubPlan class maintains a list of PhysicalVertexinstances, divided into physical plan nodes and coordinator nodes:
public class PhysicalVertex { private final TaskGroupLocation taskGroupLocation; private final String taskFullName; private final TaskGroupDefaultImpl taskGroup; private final ExecutorService executorService; private final FlakeIdGenerator flakeIdGenerator; private final Set\ The PhysicalPlanGenerator is responsible for converting the execution plan into SeaTunnelTask and adding various coordination tasks such as data splitting, data committing, and checkpoint tasks during execution.
public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.pipelines = executionPlan.getPipelines(); this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; // the checkpoint of a pipeline this.pipelineTasks = new HashSet<>(); this.startingTasks = new HashSet<>(); this.subtaskActions = new HashMap<>(); this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public Tuple2The process of generating the physical plan involves converting the execution plan into SeaTunnelTask and adding various coordination tasks, such as data splitting tasks, data committing tasks, and checkpoint tasks.
\ In SeaTunnelTask, tasks are converted into SourceFlowLifeCycle, SinkFlowLifeCycle, TransformFlowLifeCycle, ShuffleSinkFlowLifeCycle, ShuffleSourceFlowLifeCycle.
\ For example, the SourceFlowLifeCycle and SinkFlowLifeCycle classes are as follows:
- SourceFlowLifeCycle
In SourceFlowLifeCycle, data reading is performed in the collect method. Once data is read, it is placed into SeaTunnelSourceCollector. When data is received, the collector updates metrics and sends the data to downstream components.
\
@Override public void collect(T row) { try { if (row instanceof SeaTunnelRow) { String tableId = ((SeaTunnelRow) row).getTableId(); int size; if (rowType instanceof SeaTunnelRowType) { size = ((SeaTunnelRow) row).getBytesSize((SeaTunnelRowType) rowType); } else if (rowType instanceof MultipleRowType) { size = ((SeaTunnelRow) row).getBytesSize(rowTypeMap.get(tableId)); } else { throw new SeaTunnelEngineException( "Unsupported row type: " + rowType.getClass().getName()); } sourceReceivedBytes.inc(size); sourceReceivedBytesPerSeconds.markEvent(size); flowControlGate.audit((SeaTunnelRow) row); if (StringUtils.isNotEmpty(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sourceTableCounter = sourceReceivedCountPerTable.get(tableName); if (Objects.nonNull(sourceTableCounter)) { sourceTableCounter.inc(); } else { Counter counter = metricsContext.counter(SOURCE_RECEIVED_COUNT + "#" + tableName); counter.inc(); sourceReceivedCountPerTable.put(tableName, counter); } } } sendRecordToNext(new Record<>(row)); emptyThisPollNext = false; sourceReceivedCount.inc(); sourceReceivedQPS.markEvent(); } catch (IOException e) { throw new RuntimeException(e); } } public void sendRecordToNext(Record record) throws IOException { synchronized (checkpointLock) { for (OneInputFlowLifeCycle- SinkFlowLifeCycle
In the CoordinatorService, a physical plan is generated through the init method, and then the run method is called to actually start the task.
CoordinatorService { jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); ... jobMaster.run(); } JobMaster { public void run() { ... physicalPlan.startJob(); ... } }\ In JobMaster, when starting the task, it calls the startJobmethod of PhysicalPlan.
public void startJob() { isRunning = true; log.info("{} state process is start", getJobFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process is stopped", jobFullName)); return; } switch (getJobStatus()) { case CREATED: updateJobState(JobStatus.SCHEDULED); break; case SCHEDULED: getPipelineList() .forEach( subPlan -> { if (PipelineStatus.CREATED.equals( subPlan.getCurrPipelineStatus())) { subPlan.startSubPlanStateProcess(); } }); updateJobState(JobStatus.RUNNING); break; case RUNNING: case DOING_SAVEPOINT: break; case FAILING: case CANCELING: jobMaster.neverNeedRestore(); getPipelineList().forEach(SubPlan::cancelPipeline); break; case FAILED: case CANCELED: case SAVEPOINT_DONE: case FINISHED: stopJobStateProcess(); jobEndFuture.complete(new JobResult(getJobStatus(), errorBySubPlan.get())); return; default: throw new IllegalArgumentException("Unknown Job State: " + getJobStatus()); } }In PhysicalPlan, starting a task updates the task's status to SCHEDULED and then continues to call the start method of SubPlan.
public void startSubPlanStateProcess() { isRunning = true; log.info("{} state process is start", getPipelineFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process not start", pipelineFullName)); return; } PipelineStatus state = getCurrPipelineStatus(); switch (state) { case CREATED: updatePipelineState(PipelineStatus.SCHEDULED); break; case SCHEDULED: try { ResourceUtils.applyResourceForPipeline(jobMaster.getResourceManager(), this); log.debug( "slotProfiles: {}, PipelineLocation: {}", slotProfiles, this.getPipelineLocation()); updatePipelineState(PipelineStatus.DEPLOYING); } catch (Exception e) { makePipelineFailing(e); } break; case DEPLOYING: coordinatorVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); physicalVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); updatePipelineState(PipelineStatus.RUNNING); break; case RUNNING: break; case FAILING: case CANCELING: coordinatorVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); physicalVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); break; case FAILED: case CANCELED: if (checkNeedRestore(state) && prepareRestorePipeline()) { jobMaster.releasePipelineResource(this); restorePipeline(); return; } subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState(pipelineId, state, errorByPhysicalVertex.get())); return; case FINISHED: subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState( pipelineId, getPipelineState(), errorByPhysicalVertex.get())); return; default: throw new IllegalArgumentException("Unknown Pipeline State: " + getPipelineState()); } }In a SubPlan, resources are applied for all tasks. Resource application is done through the ResourceManager. During resource application, nodes are selected based on user-defined tags to ensure that tasks run on specific nodes, achieving resource isolation.
\
public static void applyResourceForPipeline( @NonNull ResourceManager resourceManager, @NonNull SubPlan subPlan) { MapWhen all available nodes are obtained, the nodes are shuffled and a node with resources larger than the required resources is randomly selected. The node is then contacted, and a RequestSlotOperation is sent to it.
\
public OptionalWhen the node’s SlotService receives the requestSlotrequest, it updates its own information and returns it to the master node. If the resource request does not meet the expected result, a NoEnoughResourceException is thrown, indicating task failure. When resource allocation succeeds, task deployment begins with task.makeTaskGroupDeploy(), which sends the task to the worker node for execution.
\
TaskDeployState deployState = deploy(jobMaster.getOwnedSlotProfiles(taskGroupLocation)); public TaskDeployState deploy(@NonNull SlotProfile slotProfile) { try { if (slotProfile.getWorker().equals(nodeEngine.getThisAddress())) { return deployOnLocal(slotProfile); } else { return deployOnRemote(slotProfile); } } catch (Throwable th) { return TaskDeployState.failed(th); } } private TaskDeployState deployOnRemote(@Non Null SlotProfile slotProfile) { return deployInternal( taskGroupImmutableInformation -> { try { return (TaskDeployState) NodeEngineUtil.sendOperationToMemberNode( nodeEngine, new DeployTaskOperation( slotProfile, nodeEngine .getSerializationService() .toData( taskGroupImmutableInformation)), slotProfile.getWorker()) .get(); } catch (Exception e) { if (getExecutionState().isEndState()) { log.warn(ExceptionUtils.getMessage(e)); log.warn( String.format( "%s deploy error, but the state is already in end state %s, skip this error", getTaskFullName(), currExecutionState)); return TaskDeployState.success(); } else { return TaskDeployState.failed(e); } } }); } Task DeploymentWhen deploying a task, the task information is sent to the node obtained during resource allocation:
public TaskDeployState deployTask(@NonNull Data taskImmutableInformation) { TaskGroupImmutableInformation taskImmutableInfo = nodeEngine.getSerializationService().toObject(taskImmutableInformation); return deployTask(taskImmutableInfo); } public TaskDeployState deployTask(@NonNull TaskGroupImmutableInformation taskImmutableInfo) { logger.info( String.format( "received deploying task executionId [%s]", taskImmutableInfo.getExecutionId())); TaskGroup taskGroup = null; try { SetWhen a worker node receives the task, it calls the deployTaskmethod of TaskExecutionService to submit the task to the thread pool created at startup.
\ When the task is submitted to the thread pool:
private final class BlockingWorker implements Runnable { private final TaskTracker tracker; private final CountDownLatch startedLatch; private BlockingWorker(TaskTracker tracker, CountDownLatch startedLatch) { this.tracker = tracker; this.startedLatch = startedLatch; } @Override public void run() { TaskExecutionService.TaskGroupExecutionTracker taskGroupExecutionTracker = tracker.taskGroupExecutionTracker; ClassLoader classLoader = executionContexts .get(taskGroupExecutionTracker.taskGroup.getTaskGroupLocation()) .getClassLoader(); ClassLoader oldClassLoader = Thread.currentThread().getContextClassLoader(); Thread.currentThread().setContextClassLoader(classLoader); final Task t = tracker.task; ProgressState result = null; try { startedLatch.countDown(); t.init(); do { result = t.call(); } while (!result.isDone() && isRunning && !taskGroupExecutionTracker.executionCompletedExceptionally()); ... } }The Task.call method is invoked, and thus data synchronization tasks are truly executed.
ClassLoaderIn SeaTunnel, the default ClassLoader has been modified to prioritize subclasses to avoid conflicts with other component classes:
@Override public synchronized ClassLoader getClassLoader(long jobId, CollectionSeaTunnel also supports task submission via REST API. To enable this feature, add the following configuration to the hazelcast.yaml file:
network: rest-api: enabled: true endpoint-groups: CLUSTER_WRITE: enabled: true DATA: enabled: trueAfter adding this configuration, the Hazelcast node will be able to receive HTTP requests.
\ Using REST API for task submission, the client becomes the node sending the HTTP request, and the server is the SeaTunnel cluster.
\ When the server receives the request, it will call the appropriate method based on the request URI:
public void handle(HttpPostCommand httpPostCommand) { String uri = httpPostCommand.getURI(); try { if (uri.startsWith(SUBMIT_JOB_URL)) { handleSubmitJob(httpPostCommand, uri); } else if (uri.startsWith(STOP_JOB_URL)) { handleStopJob(httpPostCommand, uri); } else if (uri.startsWith(ENCRYPT_CONFIG)) { handleEncrypt(httpPostCommand); } else { original.handle(httpPostCommand); } } catch (IllegalArgumentException e) { prepareResponse(SC_400, httpPostCommand, exceptionResponse(e)); } catch (Throwable e) { logger.warning("An error occurred while handling request " + httpPostCommand, e); prepareResponse(SC_500, httpPostCommand, exceptionResponse(e)); } this.textCommandService.sendResponse(httpPostCommand); }The method to handle the job submission request is determined by the path:
private void handleSubmitJob(HttpPostCommand httpPostCommand, String uri) throws IllegalArgumentException { MapThe logic here is similar to the client-side. Since there is no local mode, a local service does not need to be created.
\ On the client side, the ClientJobExecutionEnvironment class is used for logical plan parsing, and similarly, the RestJobExecutionEnvironment class performs the same tasks.
\ When submitting a task, if the current node is not the master node, it will send information to the master node. The master node will handle task submission similarly to how it handles commands from the command-line client.
\ If the current node is the master node, it will directly call the submitJob method, which invokes the coordinatorService.submitJob method for subsequent processing:
private void submitJob( SeaTunnelServer seaTunnelServer, JobImmutableInformation jobImmutableInformation, JobConfig jobConfig) { CoordinatorService coordinatorService = seaTunnelServer.getCoordinatorService(); Data data = textCommandService .getNode() .nodeEngine .getSerializationService() .toData(jobImmutableInformation); PassiveCompletableFutureBoth submission methods involve parsing the logical plan on the submission side and then sending the information to the master node. The master node then performs the physical plan parsing, allocation, and other operations.