and the distribution of digital products.
Solve Concurrency Challenges with Spring's @Transactional Annotation
\ This post is part of series on Java and Spring backend microservice development.
\ Also I’d like to mention this post is not a cookbook and doesn’t provide a perfect solution for any business problem. It’s an exploration of a certain technology that, when used correctly, can help you with some real challenges. However, its effectiveness depends on the exact problem you’re trying to solve.
\ If you’re too impatient to read and eager to dive in, you can find the project with all the materials, a docker-compose.yml file for the entire infrastructure (Kafka, PostgreSQL), tests (Gatling projects), and monitoring tools (Grafana, Prometheus, exporters) right here. In this project, you can explore various solutions and check their performance. If you face any difficulties or questions, feel free to ask in the comments, and I’ll do my best to help.
\ Now, let’s get straight to the point. My story began with the burning problem of the “Personal Finance manager” that you’ve probably seen in your favorite banking app.
\
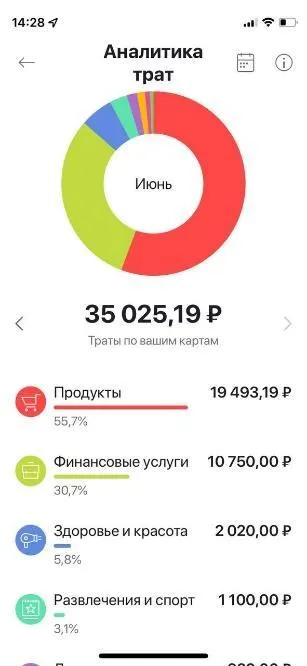
\ After the service development, various tests, including load testing, and deployment to pilot users, we faced an issue. The sums in PFM didn’t match the real expenses, thus making it useless.
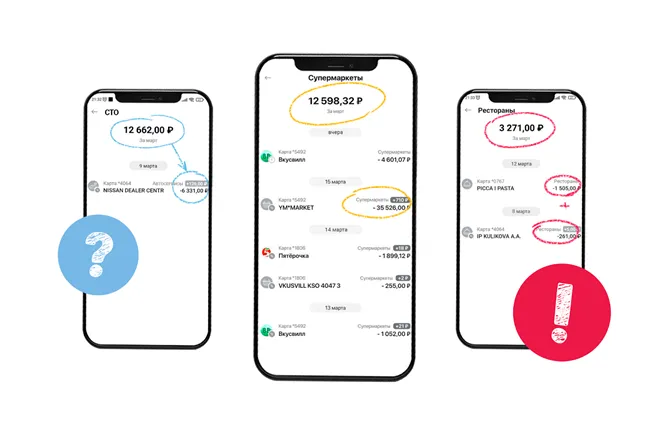
\ In fact, calculations are not the issue here.
\ Let’s dig into. There’s a microservice called “pfm-app” that gets messages from a Kafka topic, and these messages are produced by «operation-history-app» Debezium replicator from a database of another microservice. At least 4 types of history events can show here Hold/Release/Write-off/Bonuses. Each message carries a specific amount, each type of message has its unique UID. Meanwhile, there are no keys for a specific user in Kafka messages.
\ The expense manager service processes these messages in batches, collects batches for every user, and starts processing them: records data into a PostgreSQL table about the amount spent within a certain category in a certain month. Everything falls apart during the processing phase when two service consumers get events about expenses of the same user and begin processing them in parallel. How can this happen?
In general, the cause is quite obvious. While making such applications, developers often forget about parallelism and multithreading. From the developer’s perspective, the process looks like this:
\
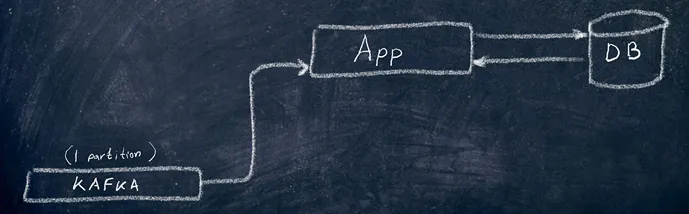
\ How does it actually work? In OpenShift, not just a single one, but a number of service pods is running, and the data is additionally coming from REST streams. The most interesting part begins when multiple consumers (pods or consumers inside a single pod connected to different Kafka partitions) or threads made for REST requests try to create/update/delete the same record in the database.
\
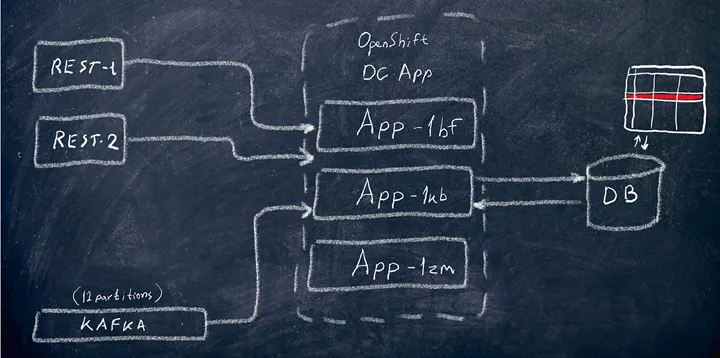
\ What can we get here? You’re right: conflicts and overwrites.
\ To reveal the problem better, let’s create a simple service just for tracking visitors’ likes for different talks.
\ The service will consist of the following components:
\ · Kafka Listener
public class LikesConsumer implements Consumer\ · Message Processor
public class SpeakerMessageProcessor { private final SpeakerService speakerService; public void processOneMessage(Likes likes) { speakerService.addLikesToSpeaker(likes); } }\ · A single service
public class SpeakerService { private final SpeakersRepository speakersRepository; private final HistoryRepository historyRepository; private final StreamBridge streamBridge; /** * Method for adding likes to speaker by ID or TalkName. * * @param likes DTO with information about likes to be added. */ public void addLikesToSpeaker(Likes likes) { if (likes.getTalkName() != null) { speakersRepository.findByTalkName(likes.getTalkName()).ifPresentOrElse(speaker -> { saveMessageToHistory(likes, "RECEIVED"); speaker.setLikes(speaker.getLikes() + likes.getLikes()); speakersRepository.save(speaker); log.info("{} likes added to {}", likes.getLikes(), speaker.getFirstName() + " " + speaker.getLastName()); }, () -> { log.warn("Speaker with talk {} not found", likes.getTalkName()); saveMessageToHistory(likes, "ORPHANED"); }); } else { log.error("Error during adding likes, no IDs given"); saveMessageToHistory(likes, "CORRUPTED"); } } /** * Method for creating task to add likes to speaker. * Produces the message with DTO to kafka, for future processing. * * @param likes DTO with information about likes to be added. */ public void createTaskToAddLikes(Likes likes) { streamBridge.send("likesProducer-out-0", likes); } /** * Method for saving message to history. * Produces the message with DTO to kafka, for future processing. * * @param likes DTO with information about likes to be added. */ private void saveMessageToHistory(Likes likes, String status) { try { historyRepository.save(HistoryEntity.builder() .talkName(likes.getTalkName()) .likes(likes.getLikes()) .status(status) .build()); } catch (RuntimeException ex) { log.warn("Failed to save message to history.", ex); } } }\ · REST controller (with the same functions as a message processor)
public class SpeakerController { private final SpeakerService service; @PostMapping("/addlikes") public ResponseEntity\ · JPA repositories (because we will using Spring Data Jpa)
public interface SpeakersRepository extends JpaRepository\ · DTOs and Entities
@Table(name = "speakers") public class SpeakerEntity { @Id private Long id; @Column(name = "firstname") private String firstName; @Column(name = "lastname") private String lastName; @Column(name = "talkname") private String talkName; private int likes; @CreationTimestamp @Column(updatable = false, nullable = false) private LocalDateTime created; @UpdateTimestamp @Column(nullable = false) private LocalDateTime updated; } @Table(name = "history") public class HistoryEntity { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "talkname") private String talkName; private int likes; private String status; @CreationTimestamp @Column(updatable = false, nullable = false) private LocalDateTime created; } public class Likes { @JsonProperty("talkName") private String talkName; @JsonProperty("likes") private int likes; }\ It looks pretty straightforward and logical, so it should work, right? Let’s check it: we’ll start the service and run a couple of tests with a thousand messages in Kafka and the controller using Gatling. You can find the Gatling scenarios in the project linked above.
ProblemAfter running the tests, we hope to see that John Doe receives 2,000 likes. However, instead we got… what we got is 851 likes.
\

\ Why did this happen? After all, according to Einstein’s special theory of relativity, in a perfect sense, it is impossible to claim that two different events happen simultaneously if these events are separated in space. Just kidding! :) In reality, here we have a race where the last one wins.
\
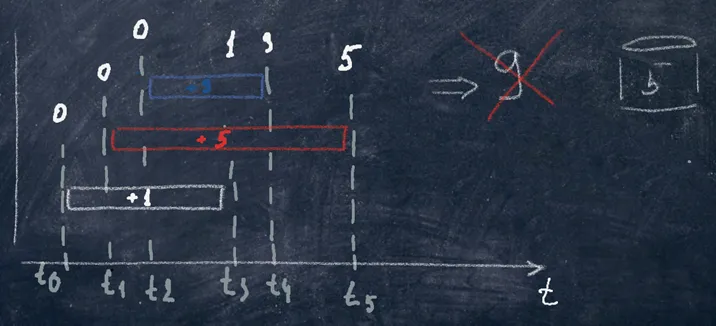
\ In the example above, three events started and ended at different times. But in fact, only one was recorded in the database, ‘5’ instead of ‘9’ in our case.
How to Solve the Problem?The first thing that may come to a beginner’s mind facing this race is thread synchronization. A traditional thread synchronization won’t hep, because here we have a distributed system with multiple service instances receiving messages from various sources (consumers and REST controllers). Strict message reading from a single Kafka partition might be an interesting approach, but it will decrease performance. Managing Kafka message keys is another intriguing idea, but do we know if the producer can set the keys necessary? And how to apply this to REST-driven messages?
\ Also, it’s essential to understand who controls Kafka and whether you can create additional temporary topics. Furthermore, we have REST requests which can be parallelized by Tomcat. What if we run the service in single-pod mode, disable hot DR, and synchronize threads later… no, that’s weird.
\ Let’s start with a meaning of a transaction. In Spring, transactions are made with @Transactional annotation.
\ A transaction is a group of sequential operations on a database that forms a logical unit of working with data. A transaction can be executed fully and successfully, ensuring data integrity and independence from concurrent transactions, or it can fail and leave no traces. Transactions are used to maintain the consistency and integrity of data in a database.
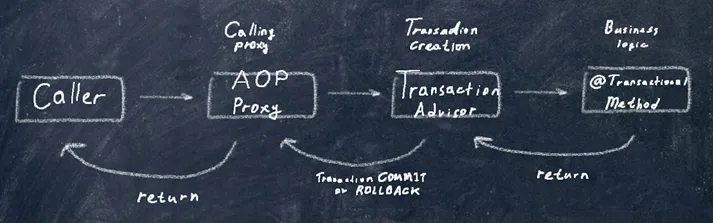
\ Transactions in Spring work as follows. We annotate a method and attempt to call it (in fact, we call a proxy that wraps our method). The Transaction Advisor creates a transaction, then our business logic is executed. Next, it returns to the Transaction Advisor, which decides whether to commit or rollback the transaction. Finally, everything returns to the proxy, and the result is returned. It’s important to know that transactions are thread-local, so they apply to the current thread only.
\
\ In our example, we place the @Transactional annotation before the addLikesToSpeaker method, because it contains the main business logic. This is where threads will call the transaction. Let’s run our test with two thousand likes again. The result will be even worse:
\n 
Let’s move on and discuss two key properties of a transaction: Isolation level and Propagation.
IsolationIsolation is the third letter in the ACID acronym. It means that concurrent transactions should not impact each other. The degree of this impact is determined by the isolation level. There are four isolation levels: Read Uncommitted, Read Committed, Repeatable Read, and Serializable. Read Uncommitted is not available in Postgres and is only kept there for compatibility. In reality, it works like Read Committed, so let’s start with this.
\ Read Committed
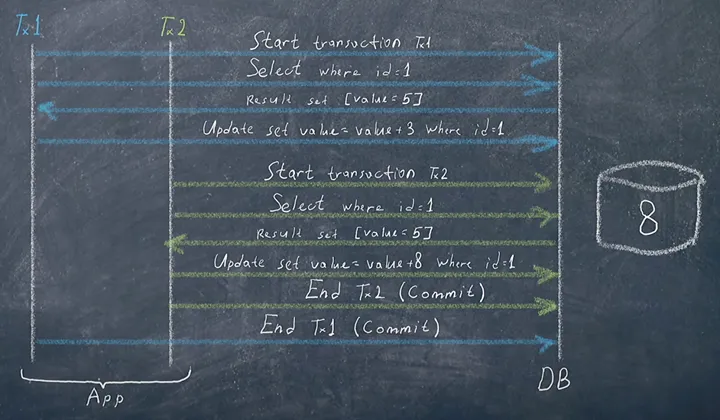
Imagine that two transactions are about to modify data in a table. Both transactions read (select) data and do updates. However, they only read the data that has been committed before. So while one transaction has not been committed, the other will read the same data as the first one. And update the same data, so in the end in the table we’ll only have the data from the last transaction committed. It looks like this:
\
\
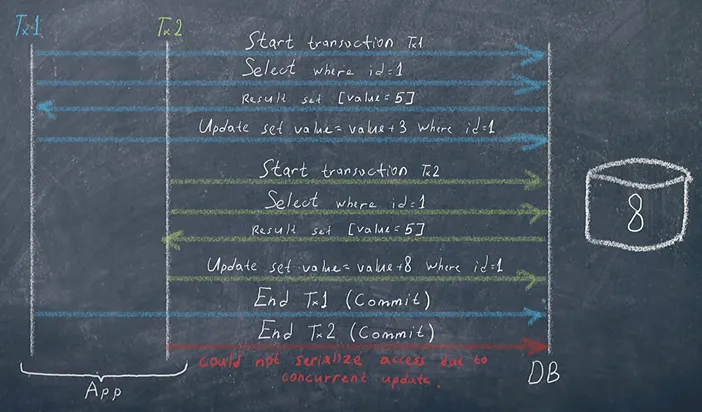
\ Imagine that before transaction 1 is committed, transaction 2 begins. It also does a similar select and gets the same result because transaction 1 has not yet been committed. In its update, transaction 2 adds 8 to the value, so the final result is 13. However, later on, transaction 1 does commit, and we end up with ‘8’ as the final value. So, after both transactions, we have the incorrect result.
We faced a similar issue in the “expense manager” when we set the isolation level of all transactions to TRANSACTIONREADCOMMITTED.
\ Repeatable Read
The Repeatable Read isolation level is designed to solve the issue of non-repeatable reads, where the same data is read multiple times within a transaction, and the values change between reads, because other transactions commit their own changes.
\
\ It starts the same way as in the first case. Transaction 1 commits after transaction 2 has completed. Then there is an attempt to commit Transaction 2, resulting in error: ‘Could not serialize access due to concurrent update’.
\ Seems like this can work. However, an exception occurs, so we need to consider using @Retryable. Let’s set a bigger number of retries, enough for our level of concurrency:
\ @Retryable(maxAttempts = 15) // This is actually quite a lot. Ideally, 1–3 attempts should be sufficient.
\ Now we run two tests with 2000 likes:
\n 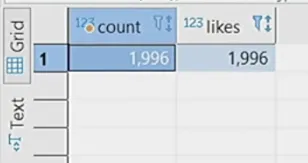
We’re almost at 100%, but not exactly. The “Could not serialize access due to concurrent update” errors are unavoidable. Let’s take a look at the monitoring to see what’s happening with the threads:
\
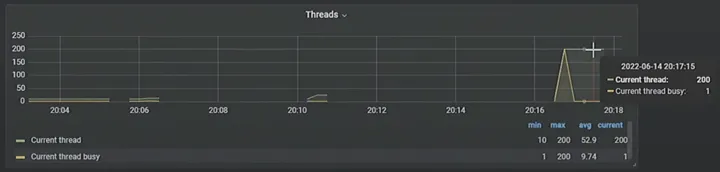
\ 200 (!!!) threads tried to update one entity. This is too much. If you see such a high number of threads in production, something probably goes wrong. Let’s try to reduce the concurrency on the REST side. Instead of triggering the update immediately, we’ll use the createTaskToAddLikes method to schedule the updates:
\
@PostMapping("/addlikes") public ResponseEntity\ It will also send messages to the Kafka queue, where we have five partitions and five consumers that process the lag:
\n 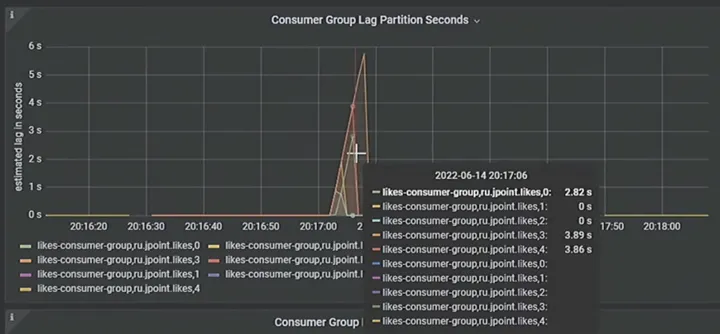
Let’s run the test. Hooray, we have 100% now:
\
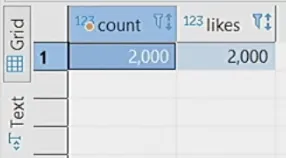
Reducing concurrency helped us decrease the number of errors. Finally, it’s worth mentioning that Repeatable Read in Postgres also solves the phantom read problem.
\ Serializable
Serializable isolation level is made to solve serialization anomalies. Here, there’s no need for explicit locks because reading and writing are monitored by the database. If the database detects that two transactions read the same record and then write to it (no matter where), it won’t allow one of the transactions to commit. As a result, transactions can update data so that nothing can overlap, in a sequence.
\
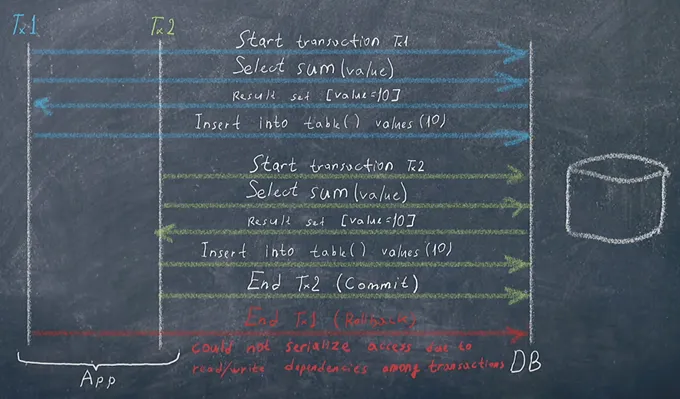
\ In our example, this isolation level will behave the same way as Repeatable Read. Let’s run the first test with 1000 likes:
\
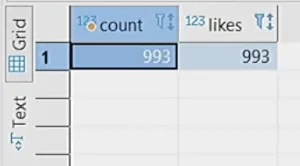
\ The reason for 993 instead of 1000 is that the saveMessageToHistory method…
private void saveMessageToHistory(Likes likes, String status) { try { historyRepository.save(HistoryEntity.builder() .talkName(likes.getTalkName()) .likes(likes.getLikes()) .status(status) .build()); } catch (RuntimeException ex) { log.warn("Failed to save message to history.", ex); }\ …is called within a transaction. Therefore, with any exceptions related, the entire transaction will be rolled back. To solve it, let’s look at another transaction property — propagation.
\

\ To begin, we are interested in the Required propagation level. If a transaction already exists in the caller method where we invoke the transaction, we simply reuse it and make the decision to commit or rollback at the end. If there was no transaction, we create a new one.
What else should we know about propagation levels? Nested is not possible in the JPA dialect because you cannot create a save point here. Nested, unlike Required New, creates a kind of save point. For example, if you are updating a huge batch of data, you won’t have to roll back everything in case of an error; you may roll back just to the save point.
\ Let’s not reinvent the wheel and mix the approaches. To annotate the desired private method with a transaction, we’ll simply move it to a separate class. We’ll extract a separate service and create a new transaction. It doesn’t matter whether it rolls back or not; the main thing is that it won’t affect the previous transaction, and vice versa:
\
public class HistoryService { private final HistoryRepository historyRepository; /** * Method for saving message to history. * Produces the message with DTO to kafka, for future processing. * * @param likes DTO with information about likes to be added. */ @Transactional(propagation = Propagation.REQUIRES_NEW) public void saveMessageToHistory(Likes likes, String status) { try { historyRepository.save(HistoryEntity.builder() .talkName(likes.getTalkName()) .likes(likes.getLikes()) .status(status) .build()); } catch (RuntimeException ex) { log.warn("Failed to save message to history.", ex); } } }\ Now we rerun our test with two retry attempts. What’s interesting is that there are more than 2000 events recorded in the history, but the number of likes is less:
\
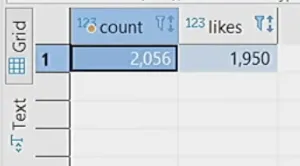
The reason is the retry mechanism. The retry attempt captures not only the event but also the history save. It will be overwritten because idempotence is not provided here.
\ What can we do here? Let’s create a @Recover method to called in case of failure, and we won’t record the history into it.
\
@Recover public void addLikesToSpeakerRecover(Exception ex, Likes likes) { if (likes.getTalkName() != null) { speakersRepository.findByTalkName(likes.getTalkName()).ifPresentOrElse(speaker -> { log.info("Adding {} likes to {}", likes.getLikes(), speaker.getFirstName() + " " + speaker.getLastName()); speaker.setLikes(speaker.getLikes() + likes.getLikes()); }, () -> { log.warn("Speaker with talk {} not found", likes.getTalkName()); saveMessageToHistory(likes, "ORPHANED"); }); } else { log.error("Error during adding likes, no IDs given"); saveMessageToHistory(likes, "CORRUPTED"); throw new SQLException() } }\
LockingAnother way to handle transactions is through locking, either optimistic or pessimistic.
\ Optimistic locking
This locking mechanism operates at the application level, not the database level. In Spring, it can be easily implemented using the @Version annotation on an entity field. The result is saved as a @Version, and updates are performed based on it. If the result set is 0 and there is no matching record in the database, an exception is raised.
\

\ Here, we don’t even need transactions, we can remove all this logic. However, we need to configure retry: set max attempts = 10. Now let’s choose the right field for annotation. The perfect candidate is the @UpdateTimestamp field. It will be updated with each save, and there should be no issues.
\
@Version @UpdateTimestamp @Column(nullable = false) private LocalDateTime updated;\ Let’s run our test:
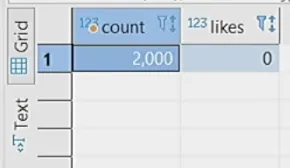
Events are coming in, but likes are not being added. This is happening because we removed the save and the transaction. So, we need to bring back save(). Keep this in mind if you are refactoring a similar service. In the case of optimistic locking and retries, you should adjust the number of retries depending on the level of concurrency. The higher the concurrency, the bigger the chances of errors, and therefore, we’ll need more retries to process all the data. Below, we will explore optimization options to reduce concurrency.
\ Pessimistic locking
This locking mechanism operates at the database level, using row-level locking. The query looks like this:
\
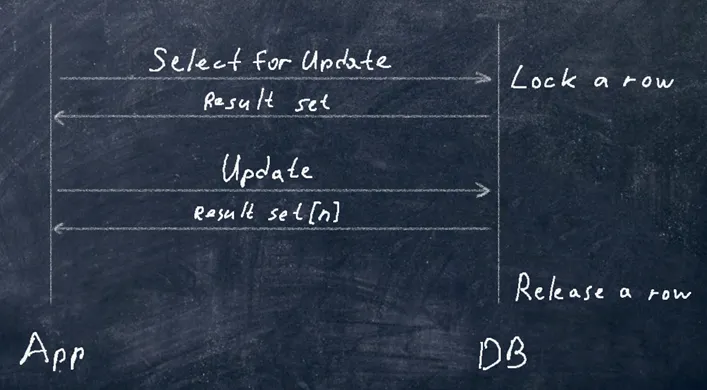
\ Let’s try to implement this in Spring. We will need the @Lock annotation.
\
@Lock(LockModeType.PESSIMISTIC_WRITE) Optional\ To test this, let’s send a single message. We will immediately receive an exception: “No transaction in progress.” That’s because previously we removed transactions from the code. Usually, developers encounter this issue and turn to Google, where they find recommendations on Stack Overflow to add @Transactional to the repository method…
\
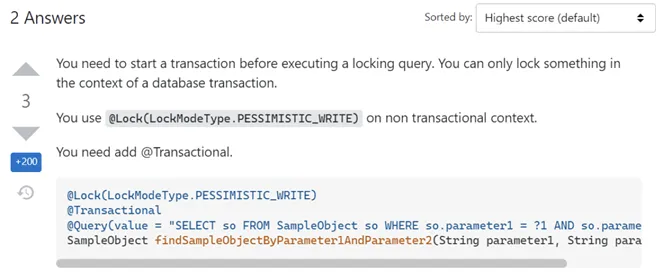
\
@Transactional @Lock(LockModeType.PESSIMISTIC_WRITE) Optional\ In our case, the tests are running without exceptions, but the likes are not being updated correctly, and we still have a shortfall.
\

\ The transaction is committed upon exiting the associated method — in our case, findByTalkName:
\
@Transactional @Lock(LockModeType.PESSIMISTIC_WRITE) Optional\ The entire transaction will be committed upon exiting that method, which means it will release the @Lock. The problem is not resolved..
\
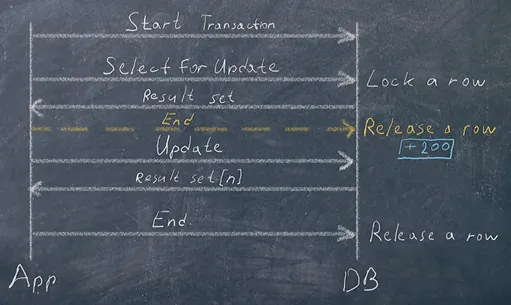
\ Actually, the transaction should be completed later, after the update, and @Transactional should be placed elsewhere. Here, we commit the transaction upon exiting the addLikesToSpeaker method:
\
@Transactional public void addLikesToSpeaker(Likes likes) { if (likes.getTalkName() != null) { speakersRepository.findByTalkName(likes.getTalkName()).ifPresentOrElse(speaker -> { saveMessageToHistory(likes, "RECEIVED"); log.info("Adding {} likes to {}", likes.getLikes(), speaker.getFirstName() + " " + speaker.getLastName()); speaker.setLikes(speaker.getLikes() + likes.getLikes()); }, () -> { log.warn("Speaker with talk {} not found", likes.getTalkName()); saveMessageToHistory(likes, "ORPHANED"); }); } else { log.error("Error during adding likes, no IDs given"); saveMessageToHistory(likes, "CORRUPTED"); } }\ When using locks, you’d better switch to the Read Committed isolation level. With Serializable, for example, the locks may not work correctly.
\
\ You can compare the performance of all the solutions discussed using the graph below. You can also try them out yourself by deploying the project locally and exploring other solutions.
\
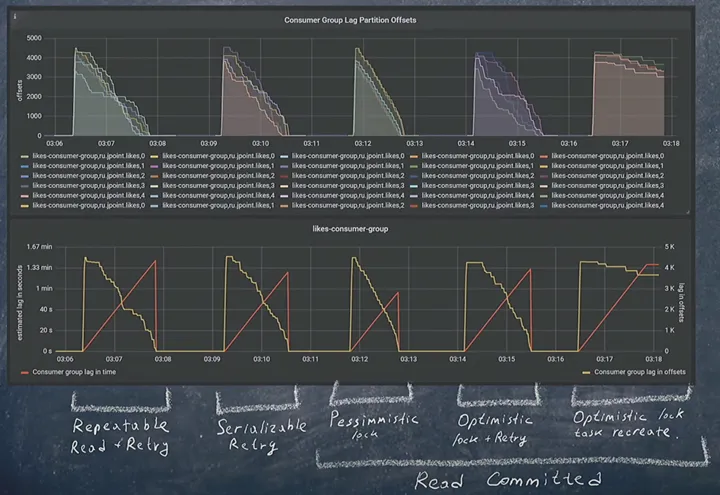
\ We see that pessimistic locking is faster than the others due to no competition between locks. The downside is that it puts more load on the processor than to the others because of the long queue creation. However, if all the requests are redirected to Kafka, there won’t be any abnormal load. Until a certain time, of course, as the client database is still growing :)
\ Now, let’s imagine that another team decided to add a check for the user’s presence in the database when saving messages and reused our query with pessimistic locking:
\
@Transactional(propagation = Propagation.REQUIRES_NEW) public void saveMessageToHistory(Likes likes, String status) { try { speakersRepository.findByTalkName(likes.getTalkName()).ifPresent((x) -> { historyRepository.save(HistoryEntity.builder() .talkName(likes.getTalkName()) .likes(likes.getLikes()) .status(status) .build()); }); } catch (RuntimeException ex) { log.warn("Failed to save message to history.", ex); } }\ What’s wrong here? Everything works until all connections to the database run out :P We have a deadlock here. It happened, because while using Propagation.REQUIRES_NEW, we stop the current transaction without releasing the lock and then try to set that lock again in a new transaction. And we wait… and wait…
\ That’s the main danger of pessimistic locks: they can lead to deadlocks. There’s no silver bullet here either, so keep this in mind in your own tasks.
Timeout vs deadlocksThe deadlock can be broken with a wonderful property, timeout:
\

\ Here’s what you need to know about timeouts in transactions:
\ · The timeout set in a transaction applies to database queries only and is propagated as a @QueryHint(javax.persistence.timeout) only to queries within the current transaction. This means that the timeout set on a transaction will never throw you out of a method unless you make a database query.
· At the time of calling a transactional method, a deadline is set.
· The queries include only the time until the deadline, not the entire specified timeout.
· The timeout does not propagate to newly created transactions, and no exception is thrown from a suspended transaction.
· If the timeout is triggered, an exception will be thrown, and the transaction must be rolled back.
\ Here are the possible exceptions related to transaction timeouts:
\ · org.springframework.transaction.TransactionTimedOutException — this exception is thrown when a transaction times out, indicating that the deadline for the transaction has passed. This typically occurs when a query or operation within the transaction exceeds the specified timeout.
· org.hibernate.TransactionException — this exception is thrown when a transaction timeout has expired. It can be wrapped in a org.springframework.orm.jpa.JpaSystemException if you’re using JPA. This occurs when Hibernate attempts to commit the transaction after the deadline has passed.
· org.springframework.dao.QueryTimeoutException — this exception occurs when a query execution exceeds the specified timeout. The root cause can be database-specific, such as org.postgresql.util.PSQLException, indicating that the statement was canceled due to a user request.
What other problems does @Transactional address?Let’s imagine that we have received a message from Kafka, processed it, and need to commit it. Processing occurs within a transaction, then data appears, and you need to commit the offset.
\
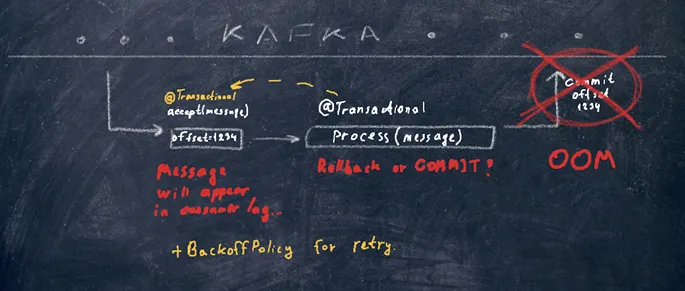
\ Suddenly, an OutOfMemoryError (OOM) occurs. What should we do next, a commit or a rollback? Probably rollback. The message will reappear in the topic’s lag. In our example, it’s not possible to implement idempotent processing right away since the messages don’t have any unique identifiers. However, we can move the transaction to a lower level, and if an exception occurs when shifting the offset, the transaction manager will see it and roll it back. The number of attempts for the consumer (BackOff) also needs to be configured for this.
Implementing this in code is not complicated. If we have a Consumer, we simply annotate the accept() method with @Transactional:
\
public class LikesConsumer implements Consumer\ If you approach it through StreamConfig and define a Bean Consumer, just annotating it is enough for all the methods within to become transactional.
\
public class StreamsConfig { private final SpeakerMessageProcessor messageProcessor; @Transactional @Bean Consumer\ Performance overhead with @Transactional
What happens when we execute a method annotated with @Transactional? First, the JPATransactionManager wraps our method, then it executes the logic, commits or rolls it back in case of an exception.
\
speakerService.addLikesToSpeaker(likes); private final JPATransactionManager transactionManager; try { // begin a new transaction if expected // (depending on the current transaction context and/or propagation mode setting) transactionManager.begin(..); addLikesToSpeaker(likes) // the method invocation, EntityManager works. transactionManager.commit(..); } catch(Exception e) { transactionManager.rollback(..); // initiate rollback if code fails throw e;\ Let’s take a simple transactional method that logs two messages and doesn’t even access the database:
\
@GetMapping("/test") @Transactional public ResponseEntity\ Let’s run it and check the logs:
\

\ As we can see, even such a simple method brings some micro-delays. On a larger scale, this can create overhead. Therefore, it is always worth considering whether you need a transaction in a specific place.
\ But the scariest part is not here, actually. Let’s reduce the maximum pool size to 1 and the timeout to 5 in the configuration, set a sleep for 8 seconds, and run the program:
\
@GetMapping("/test") @Transactional public ResponseEntity\ In the end, we had one thread started, but the second one failed with an error:
\

\ Who took the connection if we didn’t addresss to the database? When a transaction is created from the hikari pool, one connection is always acquired to set auto-commit = false. The decision to commit will actually be made by the transaction manager. With high concurrency, lack of connections can be a problem. You can fix this by manually disabling auto-commit.
\
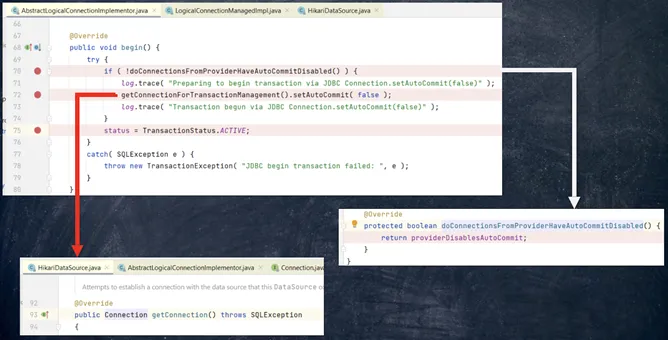
\ Here are a few tips to reduce overhead when using @Transactional:
· Avoid using @Transactional where processing occurs only at the service level.
· Under certain conditions, invoking a method marked with @Transactional can occupy a database connection from the connection pool and may not release it until the method exits.
· Use propagation = NEVER where you want to disallow the use of transactions (e.g., during parallel development).
· Separate the logic for working with the database and the internal logic of the service into different methods or services, especially for interactions with external systems or long-running computational operations..
Message processing optimizationWhen you receive a large number of messages and end up triggering many transactions, you can easily incur a significant overhead on the database.
\
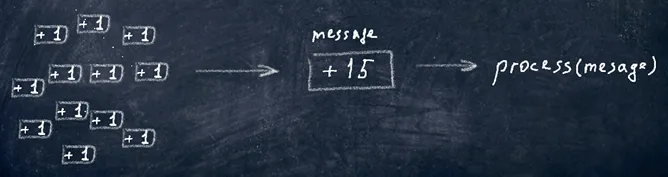
\ For example, in our service, you can write the following method for aggregating incoming messages, grouping them by the title of the presentation:
\
public void processBatchOfMessages(List\ It really speeds up the process. Such a method can be executed in multiple threads; for example, concurrently for three users. @Transactional allows these operations to be saved within the method.
Bonus: A solution with no locks/retries, and isolation tuningIs there a solution without locks and other transaction isolation complexities? There’s always a solution, and one of them is distributing event messages across Kafka partitions using Kafka message keys.
\
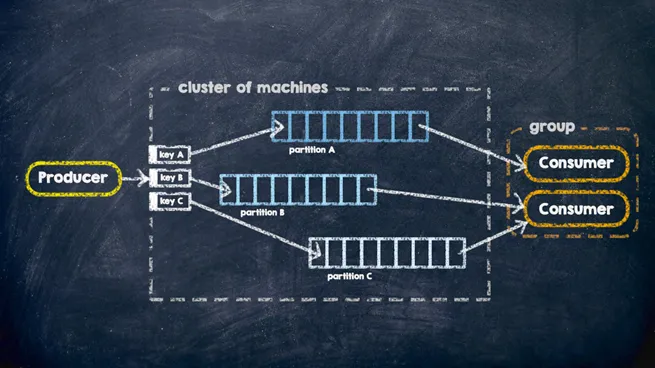
\ Messages with the same keys will always end up in the same partition of the topic, which means that only a single consumer will read these messages. If the key corresponds to a user, then you can be assured that no more than one message will be read concurrently for that user. As a result, concurrency is eliminated, and you can do it all without any transactions or locks.
\ When receiving messages from different sources, you’d better transfer all the received messages to a buffer topic, add a key to each message, and then read them from that topic with a properly configured BackOffPolicy. In this case, at the service level you eliminate concurrency and ensure the processing of all messages. Pay attention at asynchronous processing used here: this may not fit if an external system requires real-time message processing.
ConclusionTo manage transactions effectively, consider the following:
\ · Find out if you need transactions and/or locks in your code and you can reduce competition during message acquisition.
· Place the @Transactional annotation correctly in your code, only where necessary.
· Choose an appropriate isolation level to work with the database within a single project.
· Recognize when a new transaction is required and when to continue an existing one.
· Find out if you should use locks and what types you need, and plan the deadlock prevention.
· Implement transaction timeouts.
· Optimize your code for less transactional method calls and database queries.
· Plan idempotent data processing in case of retries.
\ Once again, here is the GitHub project link.
\